 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDCP-NAS: Discrepant Child-Parent Neural Architecture Search for 1-bit CNNs
Jun 27, 2023Neural architecture search (NAS) proves to be among the effective approaches for many tasks by generating an application-adaptive neural architecture, which is still challenged by high computational cost and memory consumption. At the same time, 1-bit convolutional neural networks (CNNs) with binary weights and activations show their potential for resource-limited embedded devices. One natural approach is to use 1-bit CNNs to reduce the computation and memory cost of NAS by taking advantage of the strengths of each in a unified framework, while searching the 1-bit CNNs is more challenging due to the more complicated processes involved. In this paper, we introduce Discrepant Child-Parent Neural Architecture Search (DCP-NAS) to efficiently search 1-bit CNNs, based on a new framework of searching the 1-bit model (Child) under the supervision of a real-valued model (Parent). Particularly, we first utilize a Parent model to calculate a tangent direction, based on which the tangent propagation method is introduced to search the optimized 1-bit Child. We further observe a coupling relationship between the weights and architecture parameters existing in such differentiable frameworks. To address the issue, we propose a decoupled optimization method to search an optimized architecture. Extensive experiments demonstrate that our DCP-NAS achieves much better results than prior arts on both CIFAR-10 and ImageNet datasets. In particular, the backbones achieved by our DCP-NAS achieve strong generalization performance on person re-identification and object detection.
DiffHand: End-to-End Hand Mesh Reconstruction via Diffusion Models
May 23, 2023



Hand mesh reconstruction from the monocular image is a challenging task due to its depth ambiguity and severe occlusion, there remains a non-unique mapping between the monocular image and hand mesh. To address this, we develop DiffHand, the first diffusion-based framework that approaches hand mesh reconstruction as a denoising diffusion process. Our one-stage pipeline utilizes noise to model the uncertainty distribution of the intermediate hand mesh in a forward process. We reformulate the denoising diffusion process to gradually refine noisy hand mesh and then select mesh with the highest probability of being correct based on the image itself, rather than relying on 2D joints extracted beforehand. To better model the connectivity of hand vertices, we design a novel network module called the cross-modality decoder. Extensive experiments on the popular benchmarks demonstrate that our method outperforms the state-of-the-art hand mesh reconstruction approaches by achieving 5.8mm PA-MPJPE on the Freihand test set, 4.98mm PA-MPJPE on the DexYCB test set.
One-stage Action Detection Transformer
Jun 21, 2022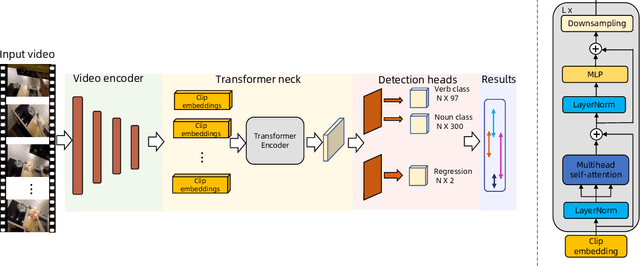
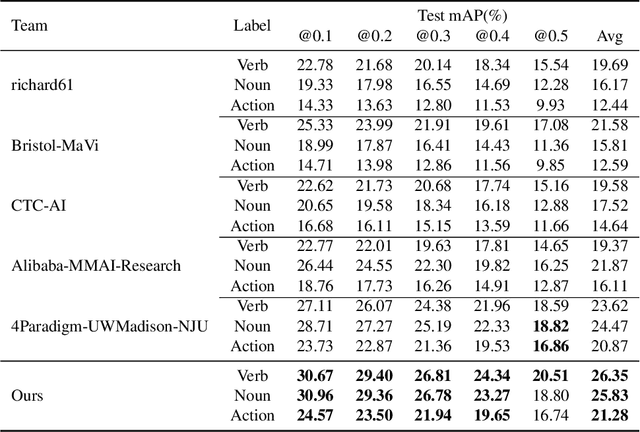
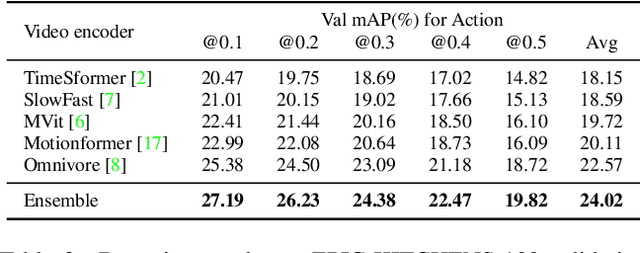
In this work, we introduce our solution to the EPIC-KITCHENS-100 2022 Action Detection challenge. One-stage Action Detection Transformer (OADT) is proposed to model the temporal connection of video segments. With the help of OADT, both the category and time boundary can be recognized simultaneously. After ensembling multiple OADT models trained from different features, our model can reach 21.28\% action mAP and ranks the 1st on the test-set of the Action detection challenge.
Cogradient Descent for Dependable Learning
Jun 20, 2021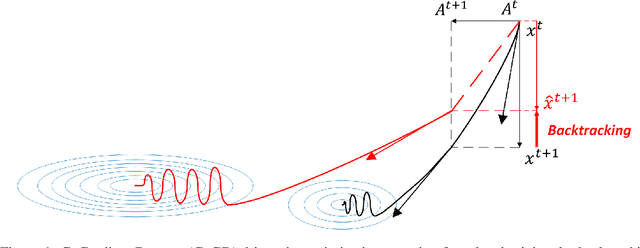
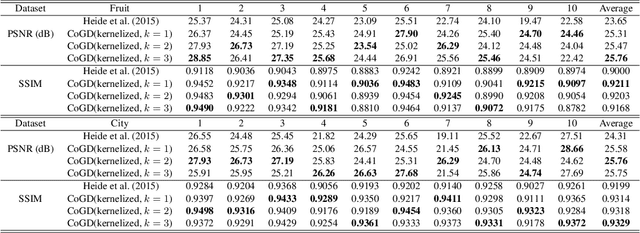
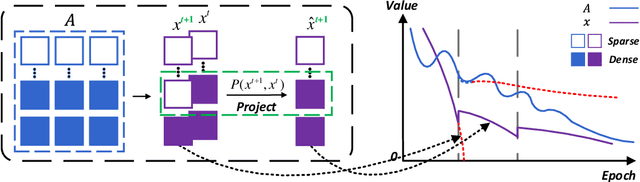
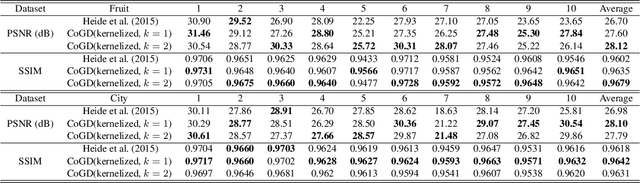
Conventional gradient descent methods compute the gradients for multiple variables through the partial derivative. Treating the coupled variables independently while ignoring the interaction, however, leads to an insufficient optimization for bilinear models. In this paper, we propose a dependable learning based on Cogradient Descent (CoGD) algorithm to address the bilinear optimization problem, providing a systematic way to coordinate the gradients of coupling variables based on a kernelized projection function. CoGD is introduced to solve bilinear problems when one variable is with sparsity constraint, as often occurs in modern learning paradigms. CoGD can also be used to decompose the association of features and weights, which further generalizes our method to better train convolutional neural networks (CNNs) and improve the model capacity. CoGD is applied in representative bilinear problems, including image reconstruction, image inpainting, network pruning and CNN training. Extensive experiments show that CoGD improves the state-of-the-arts by significant margins. Code is available at {https://github.com/bczhangbczhang/CoGD}.
Binarized Neural Architecture Search for Efficient Object Recognition
Sep 08, 2020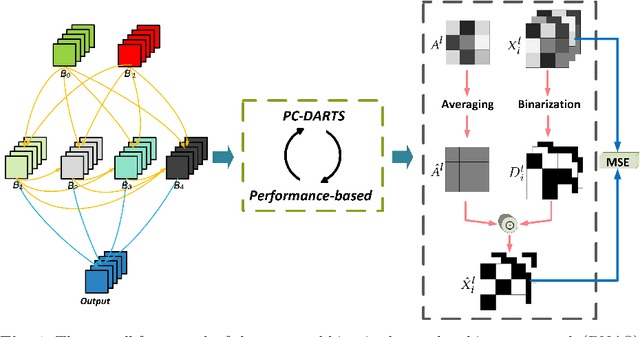

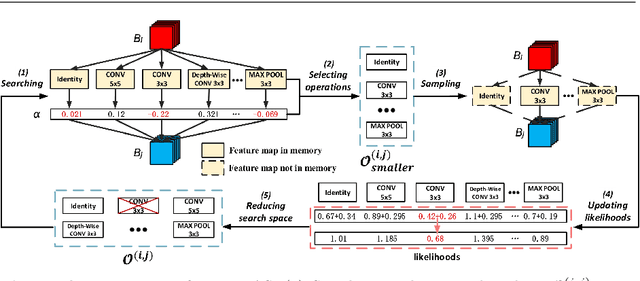
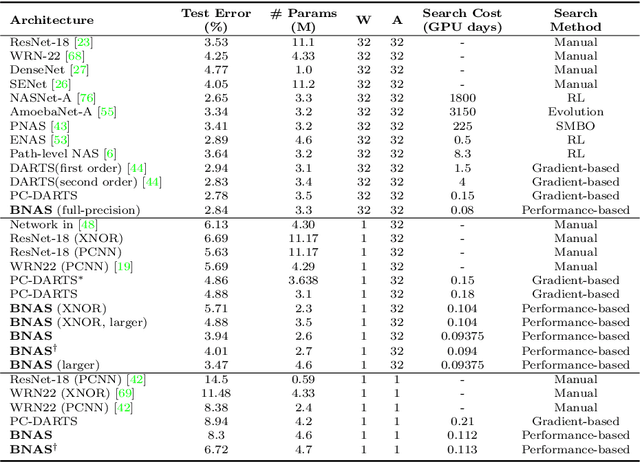
Traditional neural architecture search (NAS) has a significant impact in computer vision by automatically designing network architectures for various tasks. In this paper, binarized neural architecture search (BNAS), with a search space of binarized convolutions, is introduced to produce extremely compressed models to reduce huge computational cost on embedded devices for edge computing. The BNAS calculation is more challenging than NAS due to the learning inefficiency caused by optimization requirements and the huge architecture space, and the performance loss when handling the wild data in various computing applications. To address these issues, we introduce operation space reduction and channel sampling into BNAS to significantly reduce the cost of searching. This is accomplished through a performance-based strategy that is robust to wild data, which is further used to abandon less potential operations. Furthermore, we introduce the Upper Confidence Bound (UCB) to solve 1-bit BNAS. Two optimization methods for binarized neural networks are used to validate the effectiveness of our BNAS. Extensive experiments demonstrate that the proposed BNAS achieves a comparable performance to NAS on both CIFAR and ImageNet databases. An accuracy of $96.53\%$ vs. $97.22\%$ is achieved on the CIFAR-10 dataset, but with a significantly compressed model, and a $40\%$ faster search than the state-of-the-art PC-DARTS. On the wild face recognition task, our binarized models achieve a performance similar to their corresponding full-precision models.
Cogradient Descent for Bilinear Optimization
Jun 16, 2020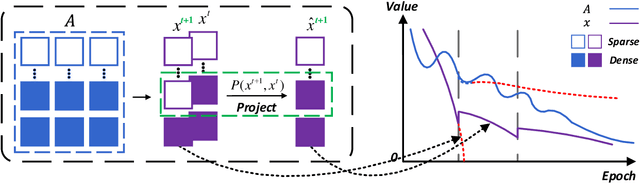
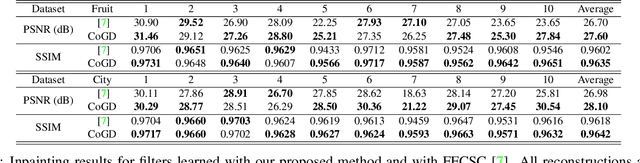
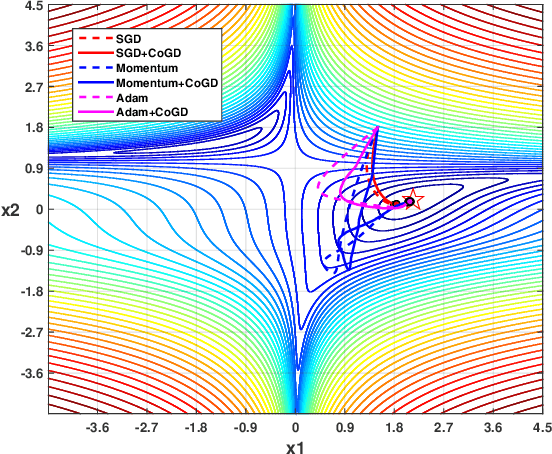
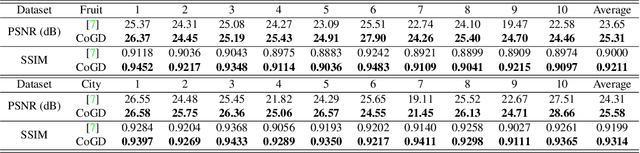
Conventional learning methods simplify the bilinear model by regarding two intrinsically coupled factors independently, which degrades the optimization procedure. One reason lies in the insufficient training due to the asynchronous gradient descent, which results in vanishing gradients for the coupled variables. In this paper, we introduce a Cogradient Descent algorithm (CoGD) to address the bilinear problem, based on a theoretical framework to coordinate the gradient of hidden variables via a projection function. We solve one variable by considering its coupling relationship with the other, leading to a synchronous gradient descent to facilitate the optimization procedure. Our algorithm is applied to solve problems with one variable under the sparsity constraint, which is widely used in the learning paradigm. We validate our CoGD considering an extensive set of applications including image reconstruction, inpainting, and network pruning. Experiments show that it improves the state-of-the-art by a significant margin.
CP-NAS: Child-Parent Neural Architecture Search for Binary Neural Networks
May 17, 2020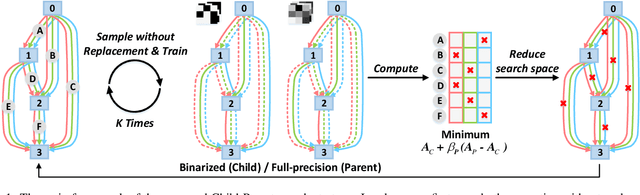
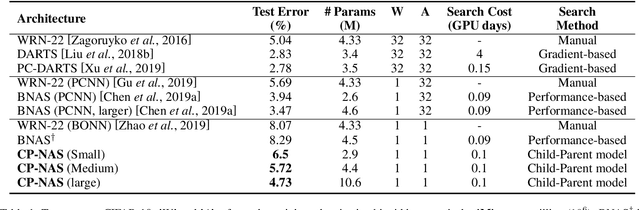
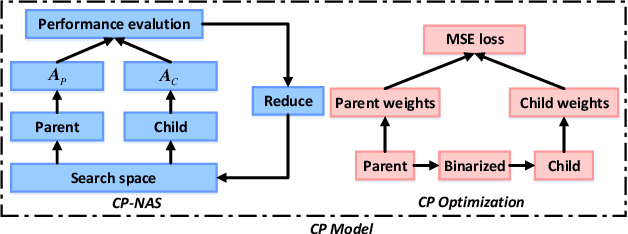
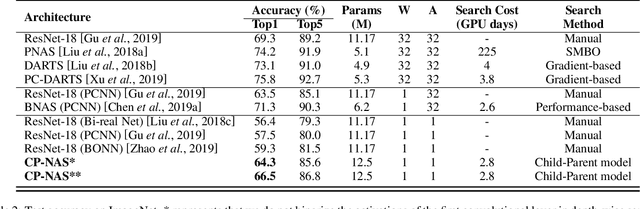
Neural architecture search (NAS) proves to be among the best approaches for many tasks by generating an application-adaptive neural architecture, which is still challenged by high computational cost and memory consumption. At the same time, 1-bit convolutional neural networks (CNNs) with binarized weights and activations show their potential for resource-limited embedded devices. One natural approach is to use 1-bit CNNs to reduce the computation and memory cost of NAS by taking advantage of the strengths of each in a unified framework. To this end, a Child-Parent (CP) model is introduced to a differentiable NAS to search the binarized architecture (Child) under the supervision of a full-precision model (Parent). In the search stage, the Child-Parent model uses an indicator generated by the child and parent model accuracy to evaluate the performance and abandon operations with less potential. In the training stage, a kernel-level CP loss is introduced to optimize the binarized network. Extensive experiments demonstrate that the proposed CP-NAS achieves a comparable accuracy with traditional NAS on both the CIFAR and ImageNet databases. It achieves the accuracy of $95.27\%$ on CIFAR-10, $64.3\%$ on ImageNet with binarized weights and activations, and a $30\%$ faster search than prior arts.
Binarized Neural Architecture Search
Nov 25, 2019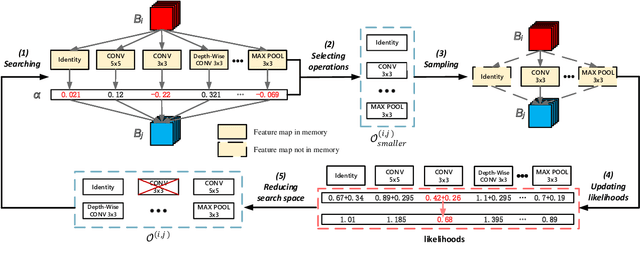
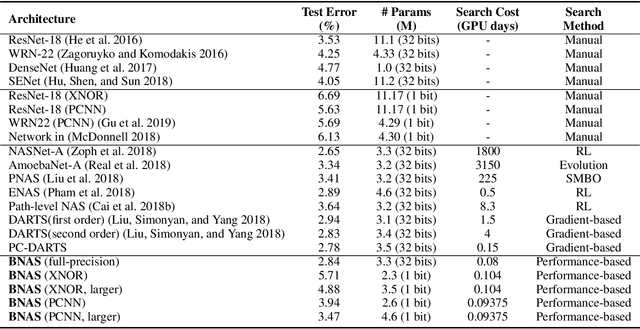
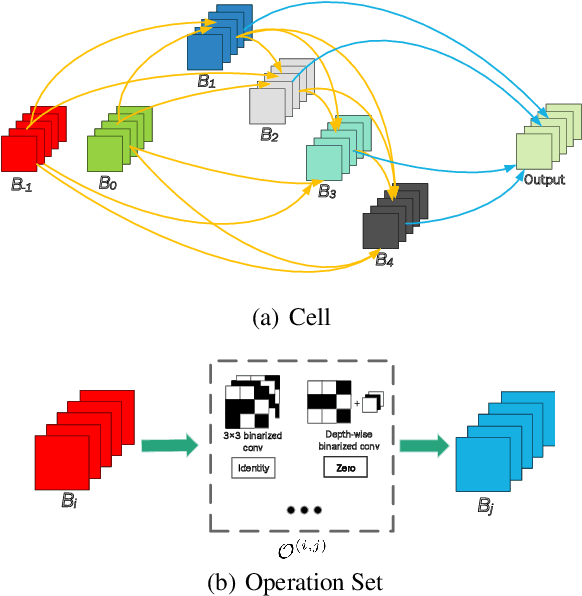
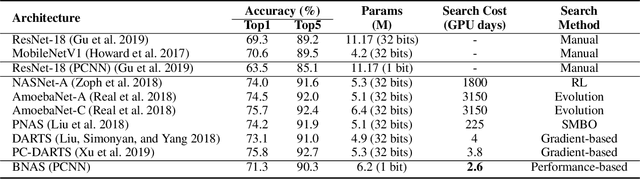
Neural architecture search (NAS) can have a significant impact in computer vision by automatically designing optimal neural network architectures for various tasks. A variant, binarized neural architecture search (BNAS), with a search space of binarized convolutions, can produce extremely compressed models. Unfortunately, this area remains largely unexplored. BNAS is more challenging than NAS due to the learning inefficiency caused by optimization requirements and the huge architecture space. To address these issues, we introduce channel sampling and operation space reduction into a differentiable NAS to significantly reduce the cost of searching. This is accomplished through a performance-based strategy used to abandon less potential operations. Two optimization methods for binarized neural networks are used to validate the effectiveness of our BNAS. Extensive experiments demonstrate that the proposed BNAS achieves a performance comparable to NAS on both CIFAR and ImageNet databases. An accuracy of $96.53\%$ vs. $97.22\%$ is achieved on the CIFAR-10 dataset, but with a significantly compressed model, and a $40\%$ faster search than the state-of-the-art PC-DARTS.