 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe MIT Supercloud Workload Classification Challenge
Apr 13, 2022

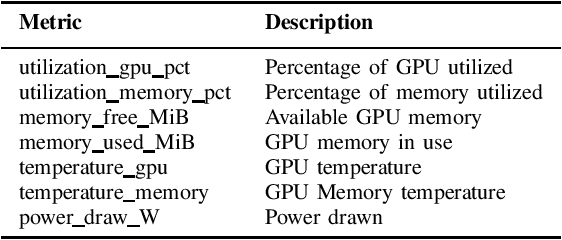
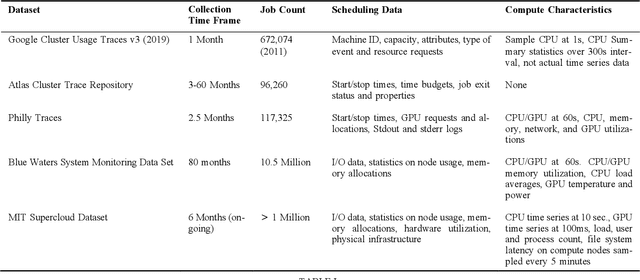
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
The MIT Supercloud Dataset
Aug 04, 2021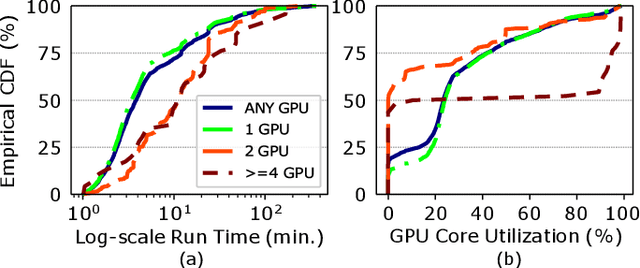
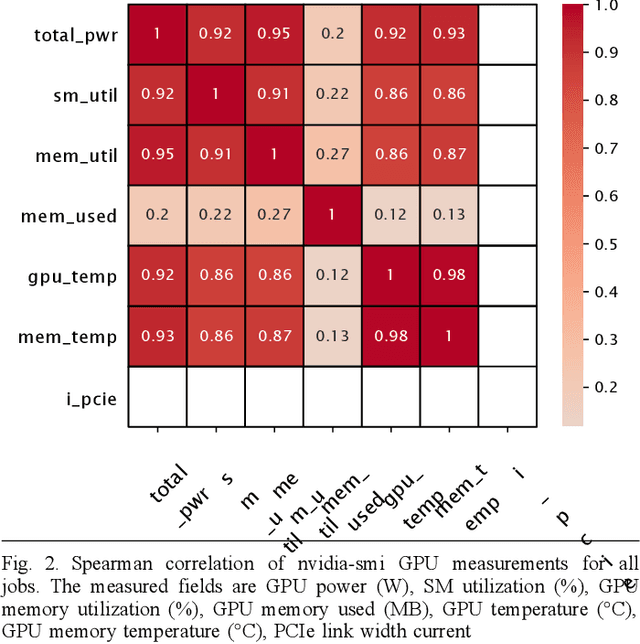

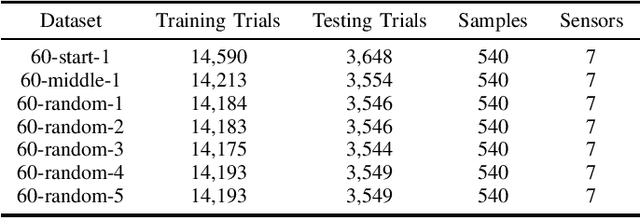
Artificial intelligence (AI) and Machine learning (ML) workloads are an increasingly larger share of the compute workloads in traditional High-Performance Computing (HPC) centers and commercial cloud systems. This has led to changes in deployment approaches of HPC clusters and the commercial cloud, as well as a new focus on approaches to optimized resource usage, allocations and deployment of new AI frame- works, and capabilities such as Jupyter notebooks to enable rapid prototyping and deployment. With these changes, there is a need to better understand cluster/datacenter operations with the goal of developing improved scheduling policies, identifying inefficiencies in resource utilization, energy/power consumption, failure prediction, and identifying policy violations. In this paper we introduce the MIT Supercloud Dataset which aims to foster innovative AI/ML approaches to the analysis of large scale HPC and datacenter/cloud operations. We provide detailed monitoring logs from the MIT Supercloud system, which include CPU and GPU usage by jobs, memory usage, file system logs, and physical monitoring data. This paper discusses the details of the dataset, collection methodology, data availability, and discusses potential challenge problems being developed using this data. Datasets and future challenge announcements will be available via https://dcc.mit.edu.
Mathematics of Digital Hyperspace
Mar 28, 2021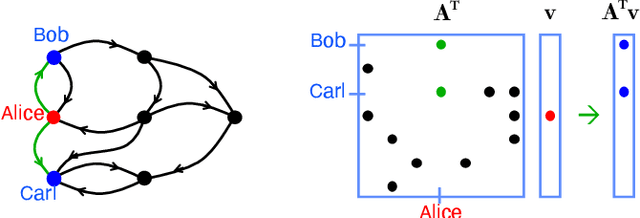
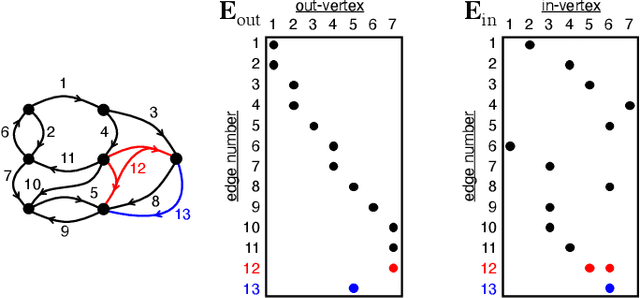
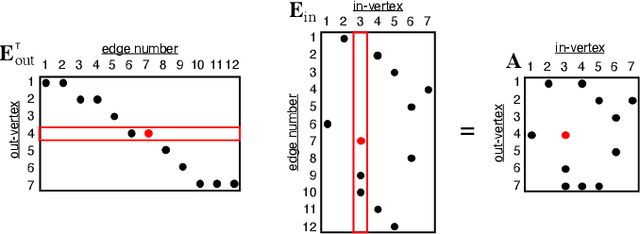
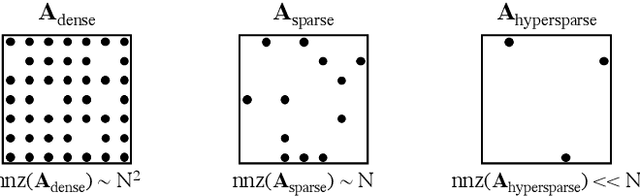
Social media, e-commerce, streaming video, e-mail, cloud documents, web pages, traffic flows, and network packets fill vast digital lakes, rivers, and oceans that we each navigate daily. This digital hyperspace is an amorphous flow of data supported by continuous streams that stretch standard concepts of type and dimension. The unstructured data of digital hyperspace can be elegantly represented, traversed, and transformed via the mathematics of hypergraphs, hypersparse matrices, and associative array algebra. This paper explores a novel mathematical concept, the semilink, that combines pairs of semirings to provide the essential operations for graph analytics, database operations, and machine learning. The GraphBLAS standard currently supports hypergraphs, hypersparse matrices, the mathematics required for semilinks, and seamlessly performs graph, network, and matrix operations. With the addition of key based indices (such as pointers to strings) and semilinks, GraphBLAS can become a richer associative array algebra and be a plug-in replacement for spreadsheets, database tables, and data centric operating systems, enhancing the navigation of unstructured data found in digital hyperspace.
Accuracy and Performance Comparison of Video Action Recognition Approaches
Aug 20, 2020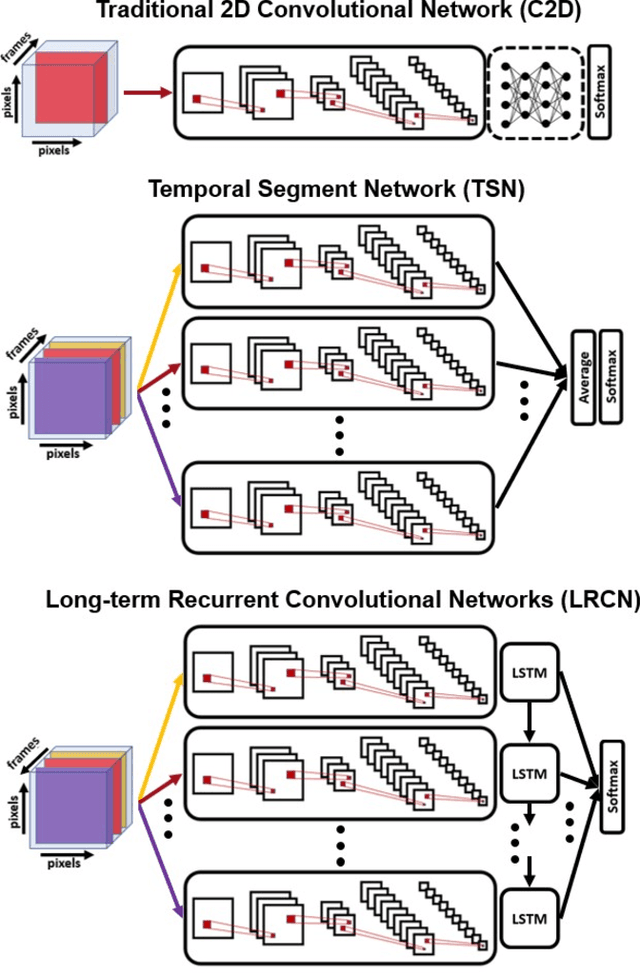
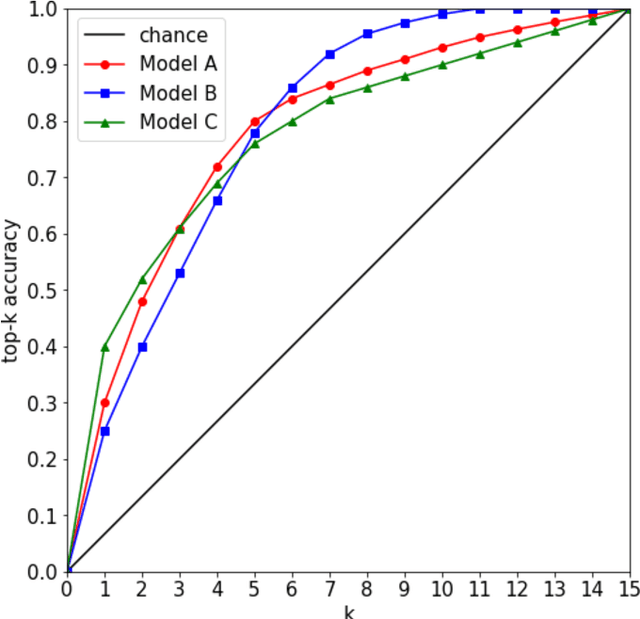
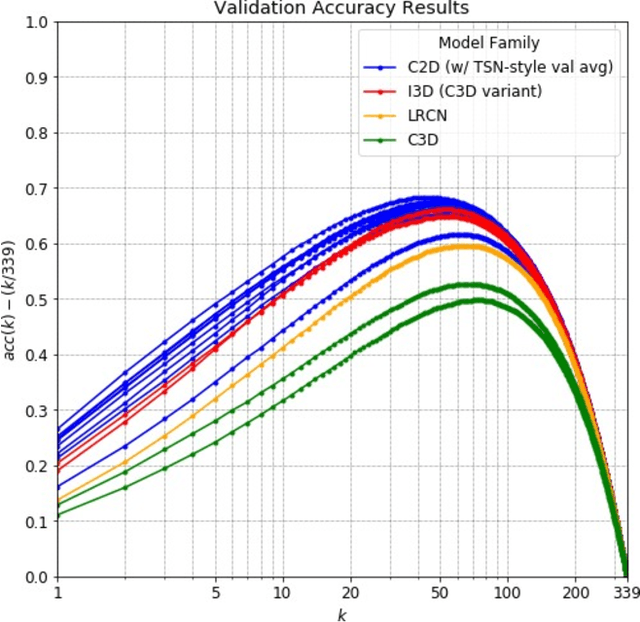
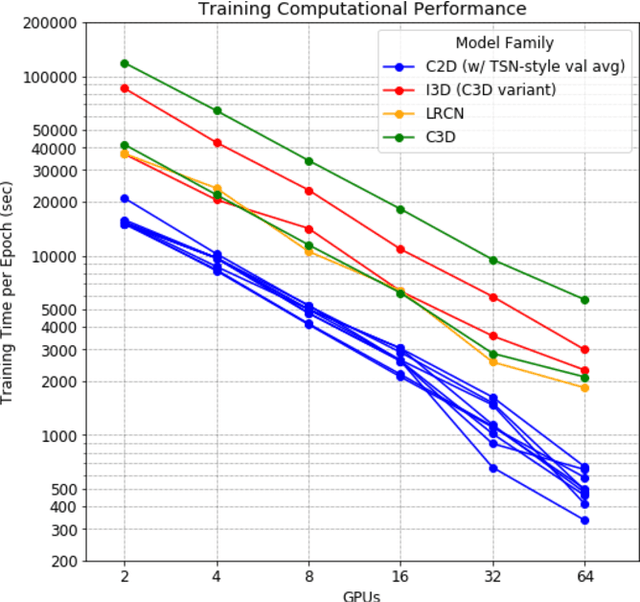
Over the past few years, there has been significant interest in video action recognition systems and models. However, direct comparison of accuracy and computational performance results remain clouded by differing training environments, hardware specifications, hyperparameters, pipelines, and inference methods. This article provides a direct comparison between fourteen off-the-shelf and state-of-the-art models by ensuring consistency in these training characteristics in order to provide readers with a meaningful comparison across different types of video action recognition algorithms. Accuracy of the models is evaluated using standard Top-1 and Top-5 accuracy metrics in addition to a proposed new accuracy metric. Additionally, we compare computational performance of distributed training from two to sixty-four GPUs on a state-of-the-art HPC system.
Benchmarking network fabrics for data distributed training of deep neural networks
Aug 18, 2020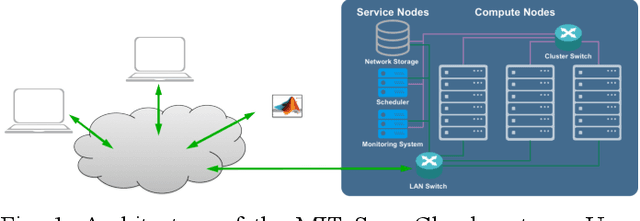
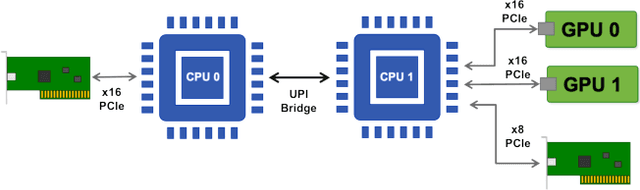
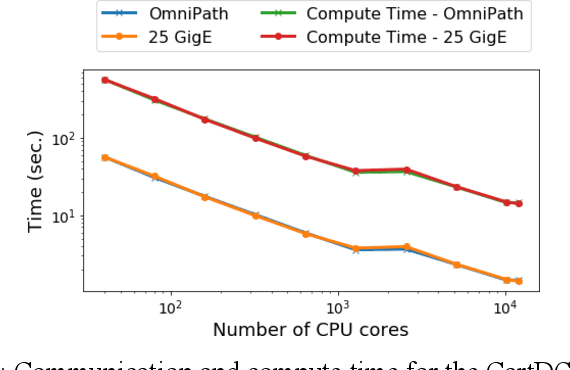

Artificial Intelligence/Machine Learning applications require the training of complex models on large amounts of labelled data. The large computational requirements for training deep models have necessitated the development of new methods for faster training. One such approach is the data parallel approach, where the training data is distributed across multiple compute nodes. This approach is simple to implement and supported by most of the commonly used machine learning frameworks. The data parallel approach leverages MPI for communicating gradients across all nodes. In this paper, we examine the effects of using different physical hardware interconnects and network-related software primitives for enabling data distributed deep learning. We compare the effect of using GPUDirect and NCCL on Ethernet and OmniPath fabrics. Our results show that using Ethernet-based networking in shared HPC systems does not have a significant effect on the training times for commonly used deep neural network architectures or traditional HPC applications such as Computational Fluid Dynamics.
GraphChallenge.org Sparse Deep Neural Network Performance
Apr 06, 2020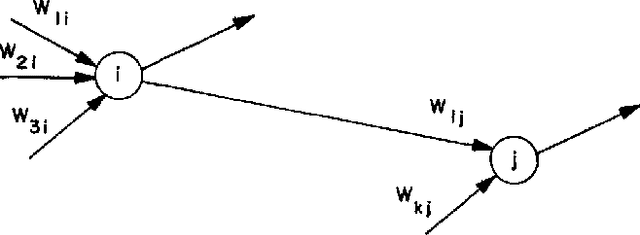
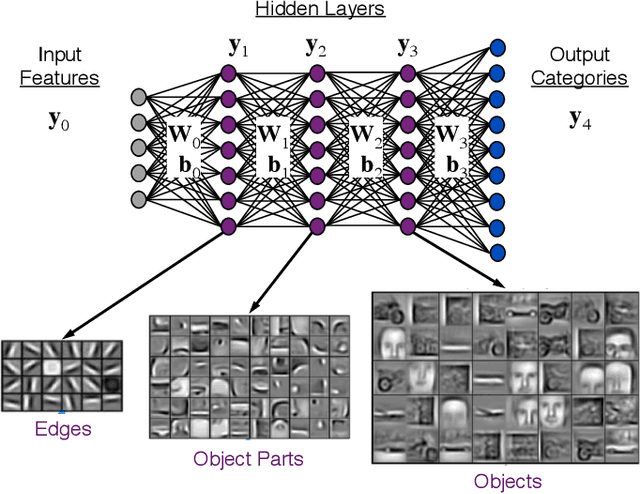
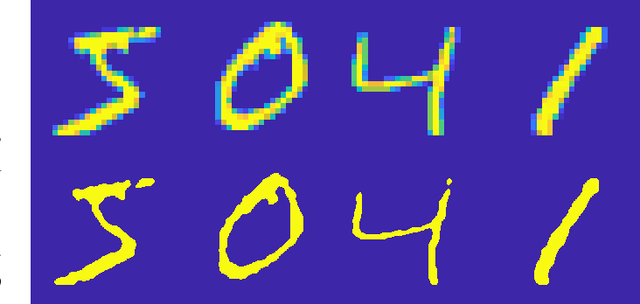
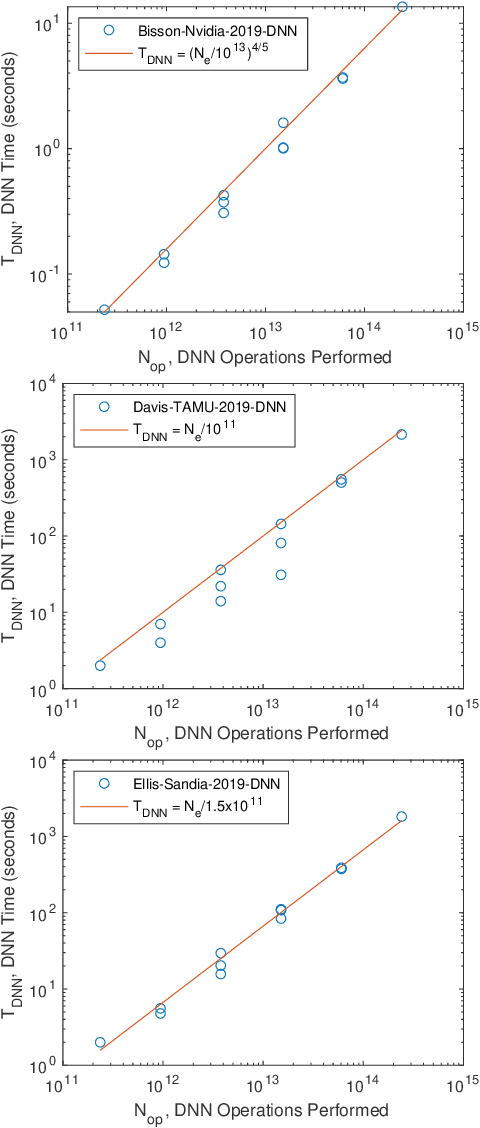
The MIT/IEEE/Amazon GraphChallenge.org encourages community approaches to developing new solutions for analyzing graphs and sparse data. Sparse AI analytics present unique scalability difficulties. The Sparse Deep Neural Network (DNN) Challenge draws upon prior challenges from machine learning, high performance computing, and visual analytics to create a challenge that is reflective of emerging sparse AI systems. The sparse DNN challenge is based on a mathematically well-defined DNN inference computation and can be implemented in any programming environment. In 2019 several sparse DNN challenge submissions were received from a wide range of authors and organizations. This paper presents a performance analysis of the best performers of these submissions. These submissions show that their state-of-the-art sparse DNN execution time, $T_{\rm DNN}$, is a strong function of the number of DNN operations performed, $N_{\rm op}$. The sparse DNN challenge provides a clear picture of current sparse DNN systems and underscores the need for new innovations to achieve high performance on very large sparse DNNs.
Sparse Deep Neural Network Graph Challenge
Sep 02, 2019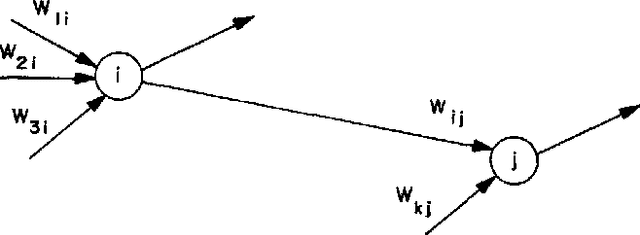
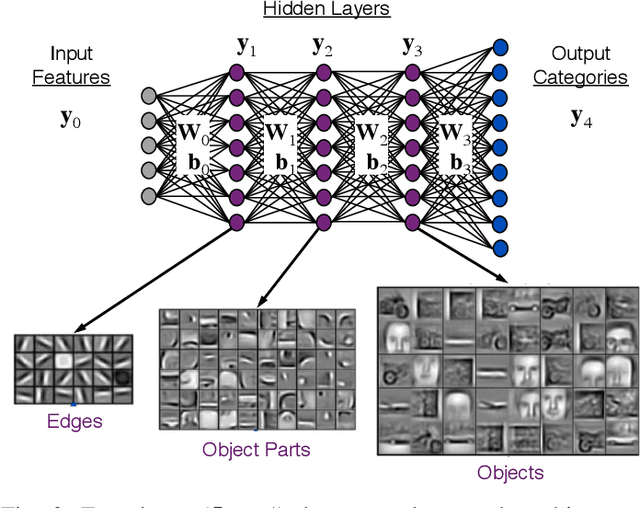
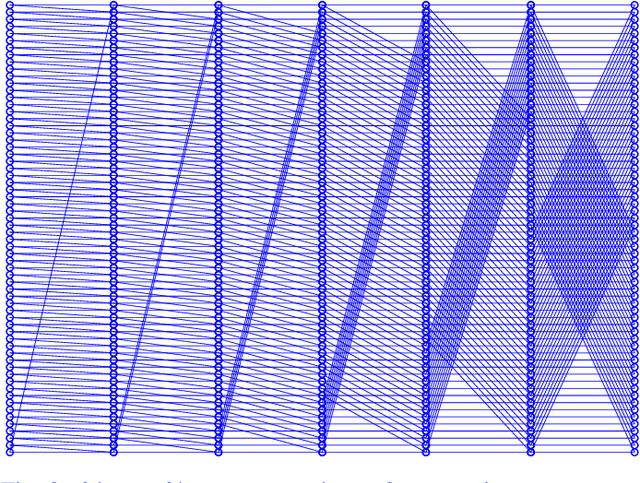
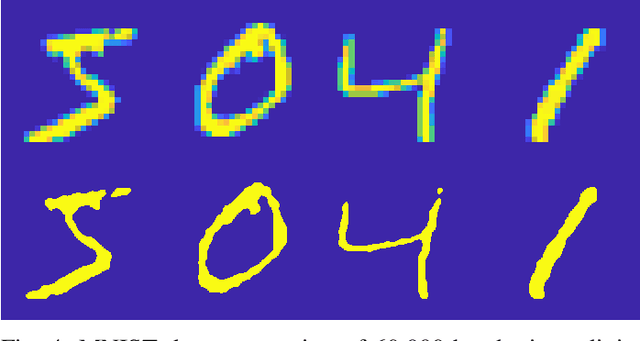
The MIT/IEEE/Amazon GraphChallenge.org encourages community approaches to developing new solutions for analyzing graphs and sparse data. Sparse AI analytics present unique scalability difficulties. The proposed Sparse Deep Neural Network (DNN) Challenge draws upon prior challenges from machine learning, high performance computing, and visual analytics to create a challenge that is reflective of emerging sparse AI systems. The Sparse DNN Challenge is based on a mathematically well-defined DNN inference computation and can be implemented in any programming environment. Sparse DNN inference is amenable to both vertex-centric implementations and array-based implementations (e.g., using the GraphBLAS.org standard). The computations are simple enough that performance predictions can be made based on simple computing hardware models. The input data sets are derived from the MNIST handwritten letters. The surrounding I/O and verification provide the context for each sparse DNN inference that allows rigorous definition of both the input and the output. Furthermore, since the proposed sparse DNN challenge is scalable in both problem size and hardware, it can be used to measure and quantitatively compare a wide range of present day and future systems. Reference implementations have been implemented and their serial and parallel performance have been measured. Specifications, data, and software are publicly available at GraphChallenge.org
Pruned and Structurally Sparse Neural Networks
Sep 30, 2018
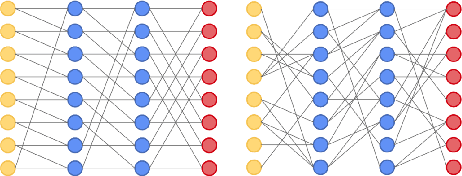
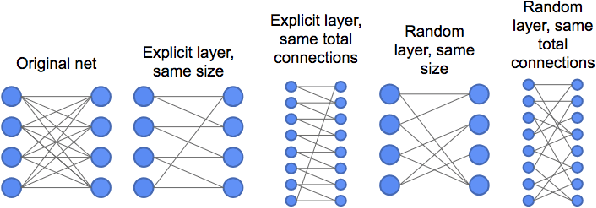
Advances in designing and training deep neural networks have led to the principle that the large and deeper a network is, the better it can perform. As a result, computational resources have become a key limiting factor in achieving better performance. One strategy to improve network capabilities while decreasing computation required is to replace dense fully-connected and convolutional layers with sparse layers. In this paper we experiment with training on sparse neural network topologies. First, we test pruning-based sparse topologies, which use a network topology obtained by initially training a dense network and then pruning low-weight connections. Second, we test RadiX-Nets, a class of sparse network structures with proven connectivity and sparsity properties. Results show that compared to dense topologies, sparse structures show promise in training potential but also can exhibit highly nonlinear convergence, which merits further study.
Sparse Deep Neural Network Exact Solutions
Jul 06, 2018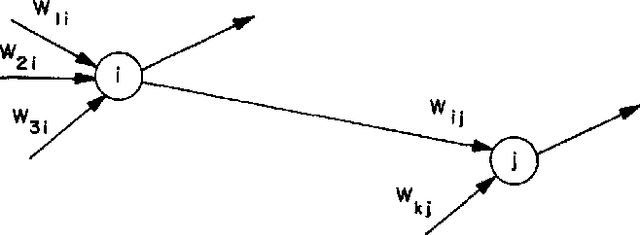
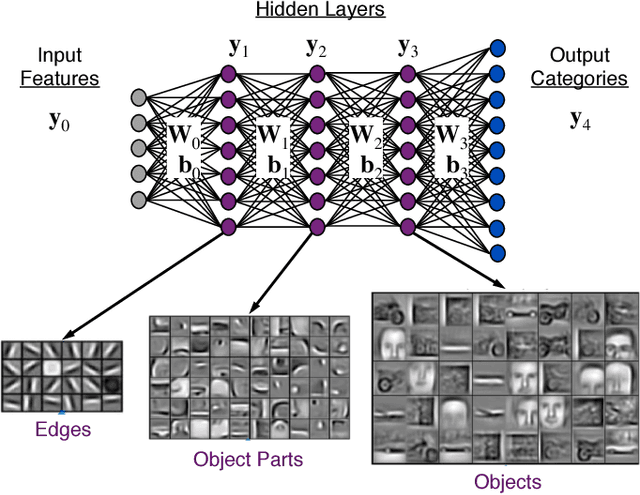
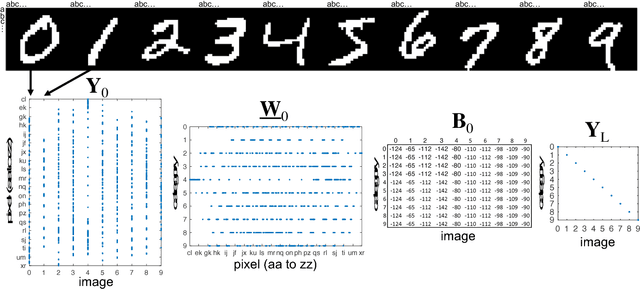
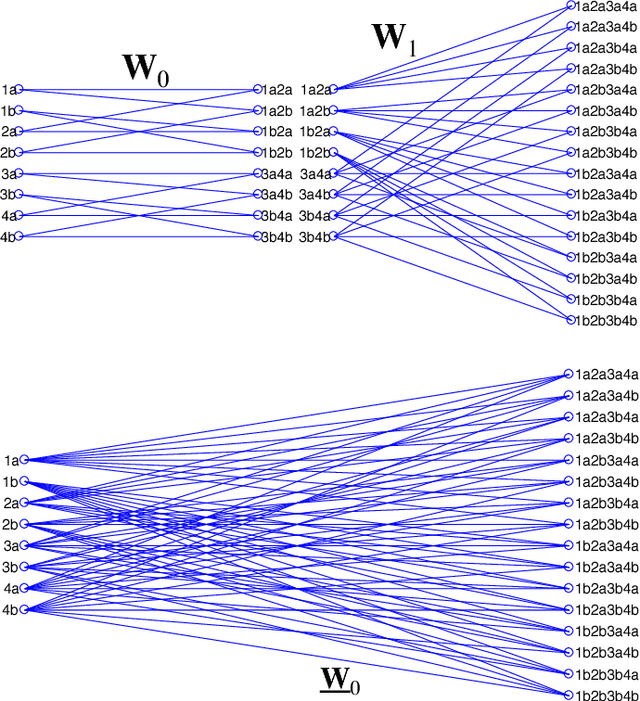
Deep neural networks (DNNs) have emerged as key enablers of machine learning. Applying larger DNNs to more diverse applications is an important challenge. The computations performed during DNN training and inference are dominated by operations on the weight matrices describing the DNN. As DNNs incorporate more layers and more neurons per layers, these weight matrices may be required to be sparse because of memory limitations. Sparse DNNs are one possible approach, but the underlying theory is in the early stages of development and presents a number of challenges, including determining the accuracy of inference and selecting nonzero weights for training. Associative array algebra has been developed by the big data community to combine and extend database, matrix, and graph/network concepts for use in large, sparse data problems. Applying this mathematics to DNNs simplifies the formulation of DNN mathematics and reveals that DNNs are linear over oscillating semirings. This work uses associative array DNNs to construct exact solutions and corresponding perturbation models to the rectified linear unit (ReLU) DNN equations that can be used to construct test vectors for sparse DNN implementations over various precisions. These solutions can be used for DNN verification, theoretical explorations of DNN properties, and a starting point for the challenge of sparse training.