 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePruned and Structurally Sparse Neural Networks
Paper and Code
Sep 30, 2018
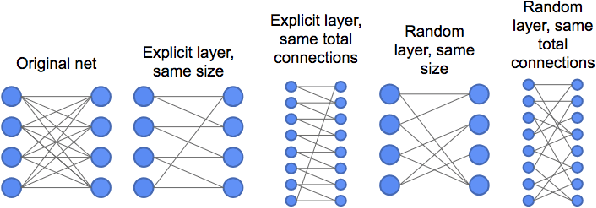
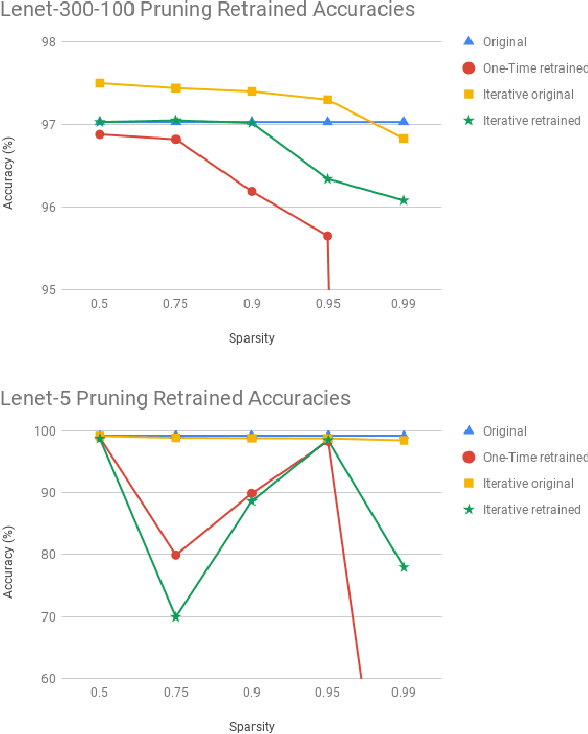
Advances in designing and training deep neural networks have led to the principle that the large and deeper a network is, the better it can perform. As a result, computational resources have become a key limiting factor in achieving better performance. One strategy to improve network capabilities while decreasing computation required is to replace dense fully-connected and convolutional layers with sparse layers. In this paper we experiment with training on sparse neural network topologies. First, we test pruning-based sparse topologies, which use a network topology obtained by initially training a dense network and then pruning low-weight connections. Second, we test RadiX-Nets, a class of sparse network structures with proven connectivity and sparsity properties. Results show that compared to dense topologies, sparse structures show promise in training potential but also can exhibit highly nonlinear convergence, which merits further study.