 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNullpointer at ArAIEval Shared Task: Arabic Propagandist Technique Detection with Token-to-Word Mapping in Sequence Tagging
Jul 01, 2024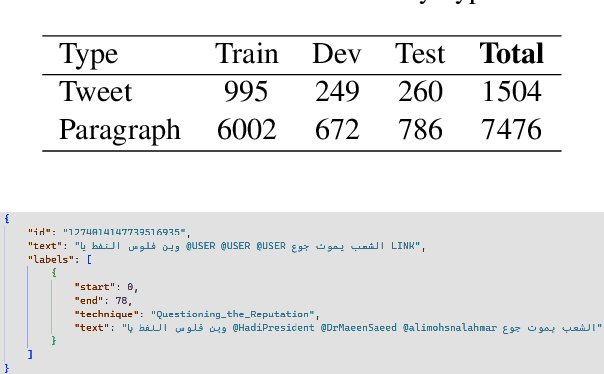
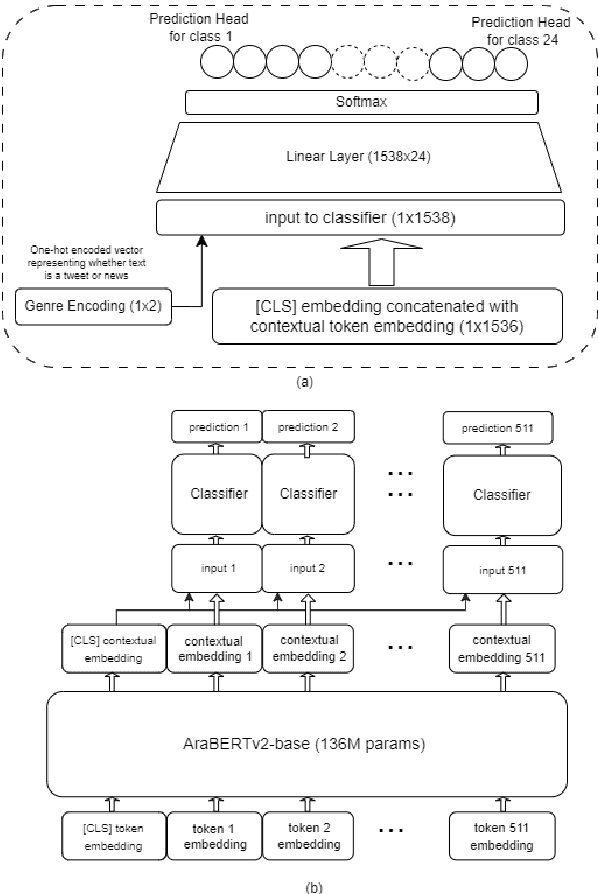
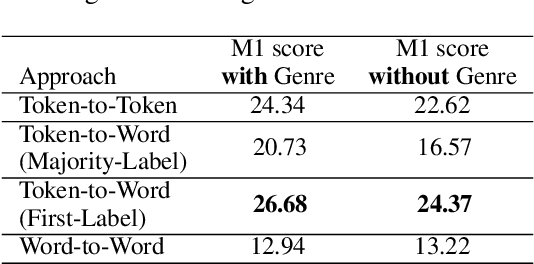
This paper investigates the optimization of propaganda technique detection in Arabic text, including tweets \& news paragraphs, from ArAIEval shared task 1. Our approach involves fine-tuning the AraBERT v2 model with a neural network classifier for sequence tagging. Experimental results show relying on the first token of the word for technique prediction produces the best performance. In addition, incorporating genre information as a feature further enhances the model's performance. Our system achieved a score of 25.41, placing us 4$^{th}$ on the leaderboard. Subsequent post-submission improvements further raised our score to 26.68.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023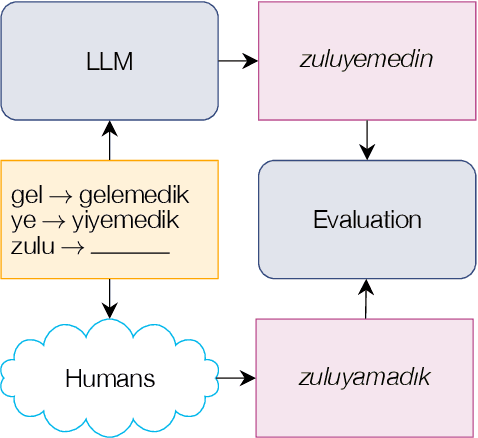
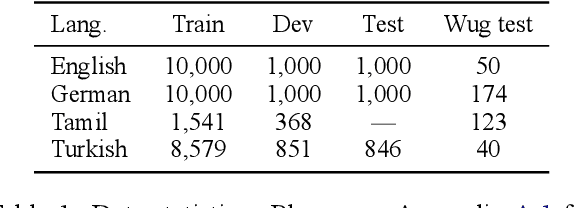
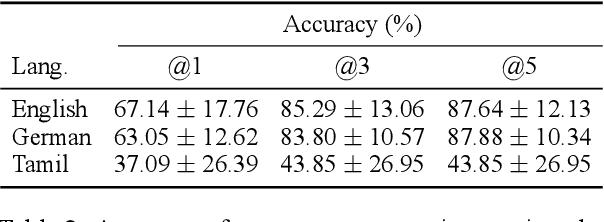
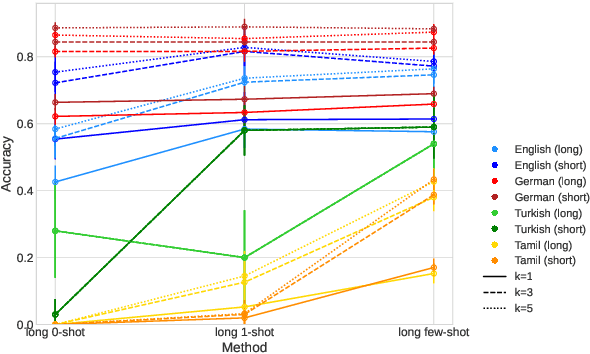
Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
Event Coreference Resolution Using Neural Network Classifiers
Oct 09, 2018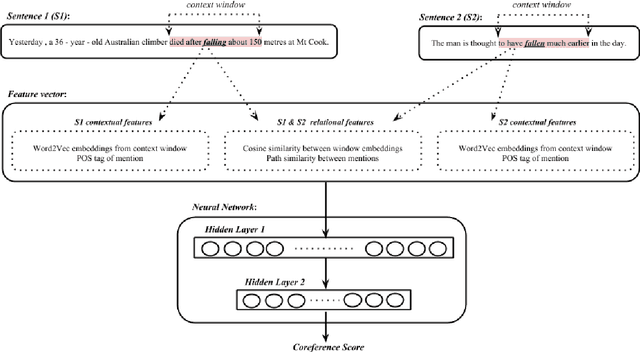
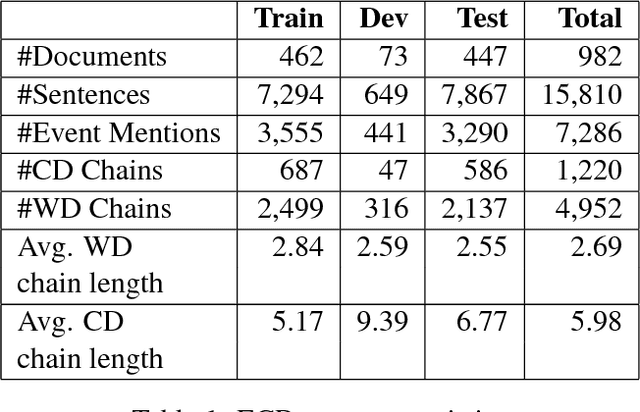
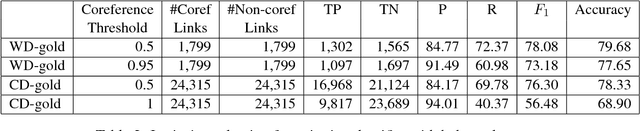
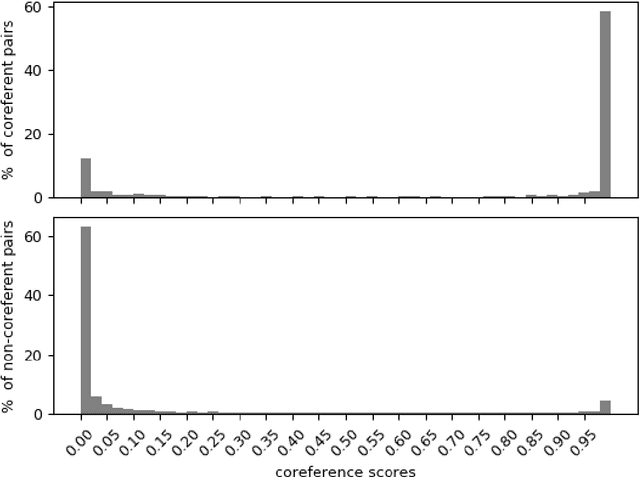
This paper presents a neural network classifier approach to detecting both within- and cross- document event coreference effectively using only event mention based features. Our approach does not (yet) rely on any event argument features such as semantic roles or spatiotemporal arguments. Experimental results on the ECB+ dataset show that our approach produces F1 scores that significantly outperform the state-of-the-art methods for both within-document and cross-document event coreference resolution when we use B3 and CEAFe evaluation measures, but gets worse F1 score with the MUC measure. However, when we use the CoNLL measure, which is the average of these three scores, our approach has slightly better F1 for within- document event coreference resolution but is significantly better for cross-document event coreference resolution.
MADARi: A Web Interface for Joint Arabic Morphological Annotation and Spelling Correction
Aug 25, 2018
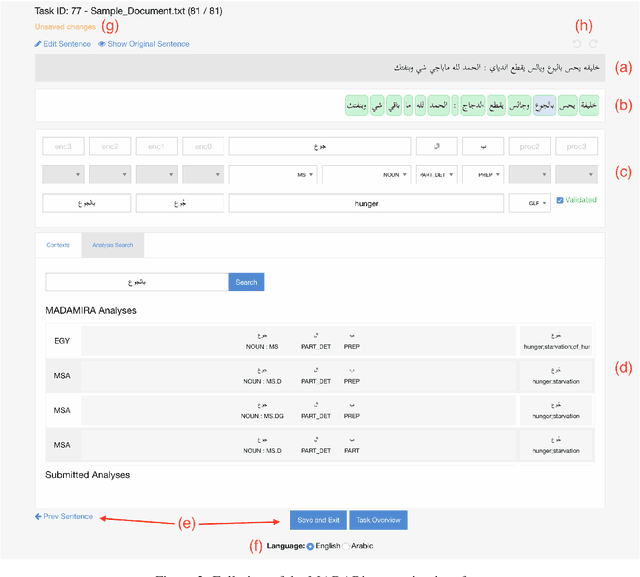
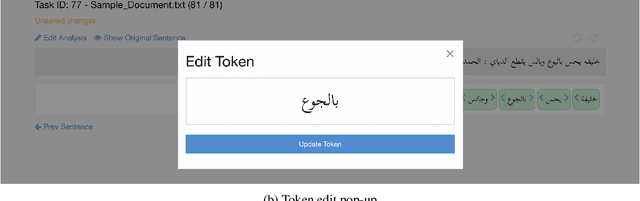
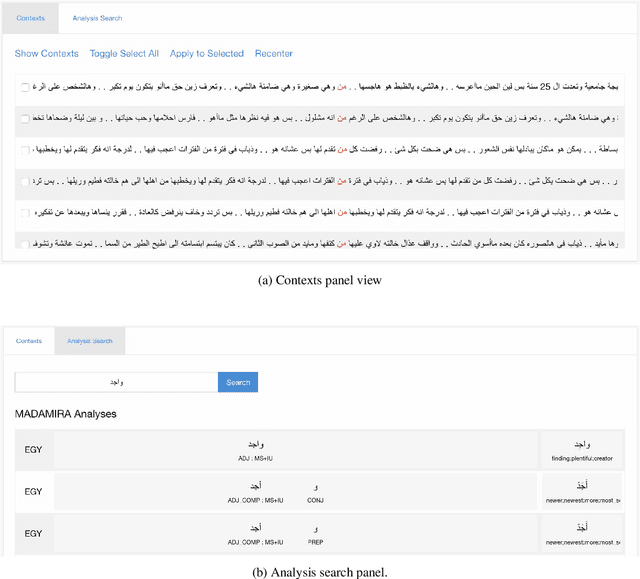
In this paper, we introduce MADARi, a joint morphological annotation and spelling correction system for texts in Standard and Dialectal Arabic. The MADARi framework provides intuitive interfaces for annotating text and managing the annotation process of a large number of sizable documents. Morphological annotation includes indicating, for a word, in context, its baseword, clitics, part-of-speech, lemma, gloss, and dialect identification. MADARi has a suite of utilities to help with annotator productivity. For example, annotators are provided with pre-computed analyses to assist them in their task and reduce the amount of work needed to complete it. MADARi also allows annotators to query a morphological analyzer for a list of possible analyses in multiple dialects or look up previously submitted analyses. The MADARi management interface enables a lead annotator to easily manage and organize the whole annotation process remotely and concurrently. We describe the motivation, design and implementation of this interface; and we present details from a user study working with this system.
Morphological Disambiguation by Voting Constraints
Apr 25, 1997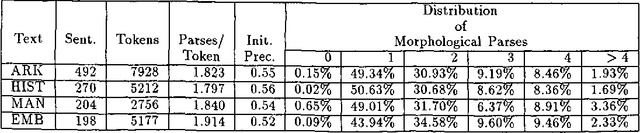

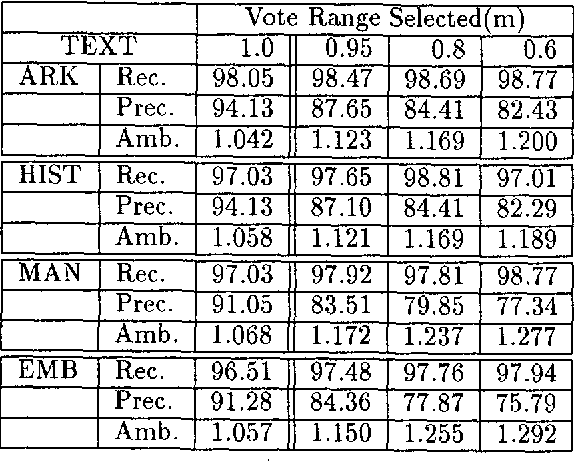
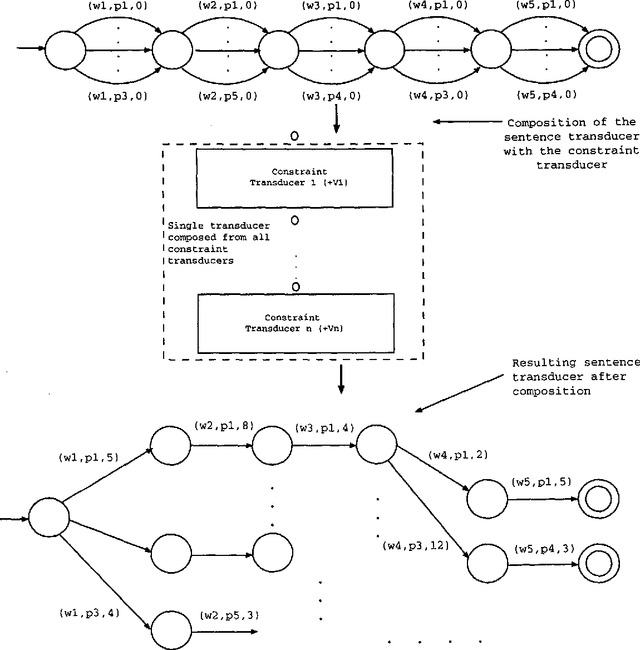
We present a constraint-based morphological disambiguation system in which individual constraints vote on matching morphological parses, and disambiguation of all the tokens in a sentence is performed at the end by selecting parses that receive the highest votes. This constraint application paradigm makes the outcome of the disambiguation independent of the rule sequence, and hence relieves the rule developer from worrying about potentially conflicting rule sequencing. Our results for disambiguating Turkish indicate that using about 500 constraint rules and some additional simple statistics, we can attain a recall of 95-96% and a precision of 94-95% with about 1.01 parses per token. Our system is implemented in Prolog and we are currently investigating an efficient implementation based on finite state transducers.
Tactical Generation in a Free Constituent Order Language
May 05, 1996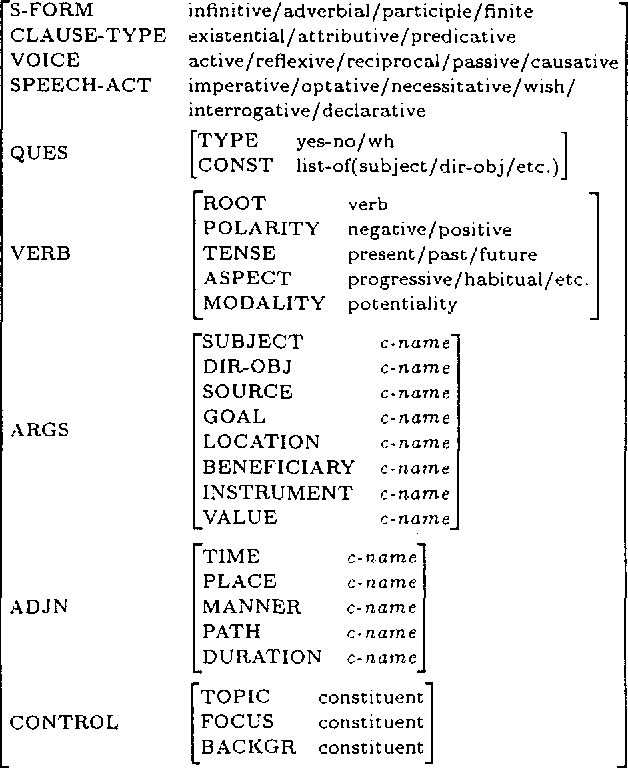
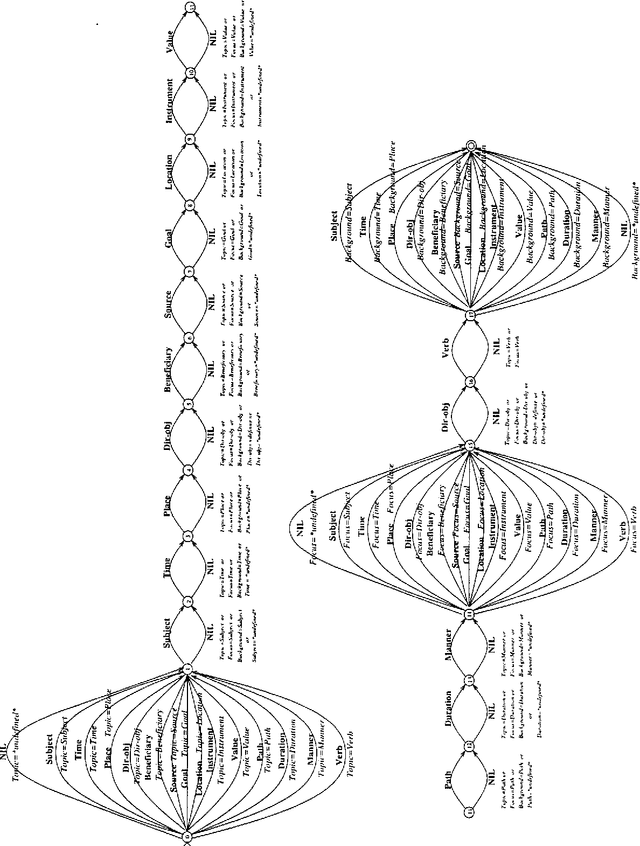
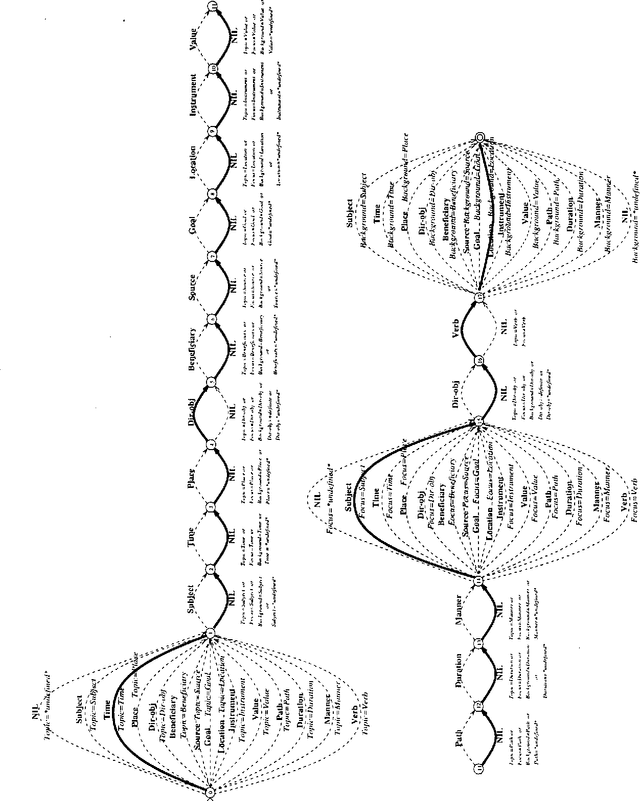
This paper describes tactical generation in Turkish, a free constituent order language, in which the order of the constituents may change according to the information structure of the sentences to be generated. In the absence of any information regarding the information structure of a sentence (i.e., topic, focus, background, etc.), the constituents of the sentence obey a default order, but the order is almost freely changeable, depending on the constraints of the text flow or discourse. We have used a recursively structured finite state machine for handling the changes in constituent order, implemented as a right-linear grammar backbone. Our implementation environment is the GenKit system, developed at Carnegie Mellon University--Center for Machine Translation. Morphological realization has been implemented using an external morphological analysis/generation component which performs concrete morpheme selection and handles morphographemic processes.
* gzipped, uuencoded postscript file
Error-tolerant Tree Matching
Apr 17, 1996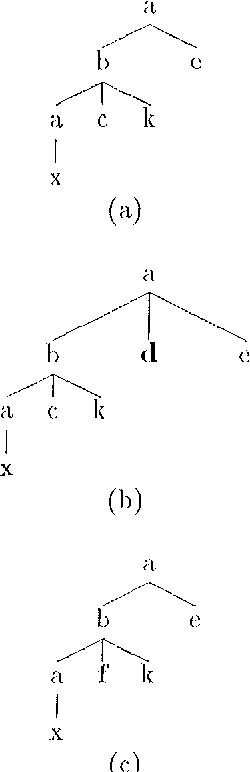
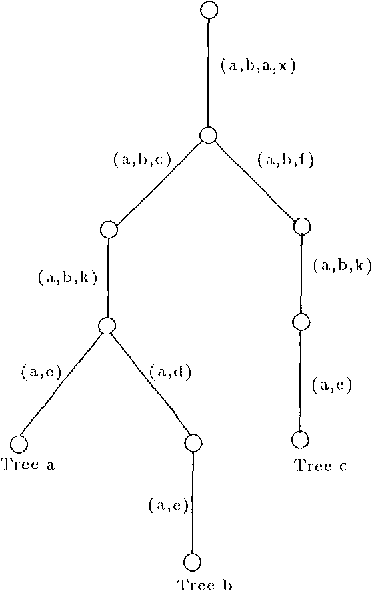

This paper presents an efficient algorithm for retrieving from a database of trees, all trees that match a given query tree approximately, that is, within a certain error tolerance. It has natural language processing applications in searching for matches in example-based translation systems, and retrieval from lexical databases containing entries of complex feature structures. The algorithm has been implemented on SparcStations, and for large randomly generated synthetic tree databases (some having tens of thousands of trees) it can associatively search for trees with a small error, in a matter of tenths of a second to few seconds.
Combining Hand-crafted Rules and Unsupervised Learning in Constraint-based Morphological Disambiguation
Apr 12, 1996
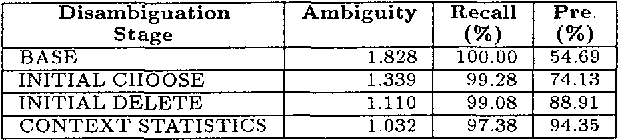
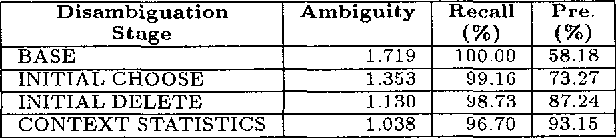
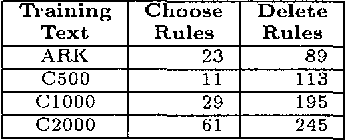
This paper presents a constraint-based morphological disambiguation approach that is applicable languages with complex morphology--specifically agglutinative languages with productive inflectional and derivational morphological phenomena. In certain respects, our approach has been motivated by Brill's recent work, but with the observation that his transformational approach is not directly applicable to languages like Turkish. Our system combines corpus independent hand-crafted constraint rules, constraint rules that are learned via unsupervised learning from a training corpus, and additional statistical information from the corpus to be morphologically disambiguated. The hand-crafted rules are linguistically motivated and tuned to improve precision without sacrificing recall. The unsupervised learning process produces two sets of rules: (i) choose rules which choose morphological parses of a lexical item satisfying constraint effectively discarding other parses, and (ii) delete rules, which delete parses satisfying a constraint. Our approach also uses a novel approach to unknown word processing by employing a secondary morphological processor which recovers any relevant inflectional and derivational information from a lexical item whose root is unknown. With this approach, well below 1 percent of the tokens remains as unknown in the texts we have experimented with. Our results indicate that by combining these hand-crafted,statistical and learned information sources, we can attain a recall of 96 to 97 percent with a corresponding precision of 93 to 94 percent, and ambiguity of 1.02 to 1.03 parses per token.
A Constraint-based Case Frame Lexicon
Apr 11, 1996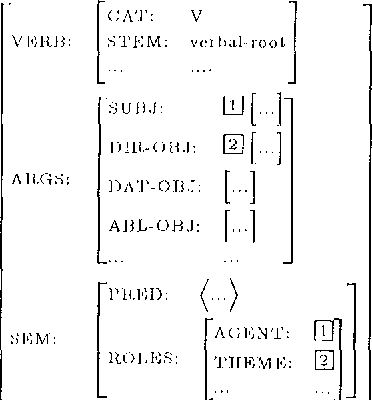
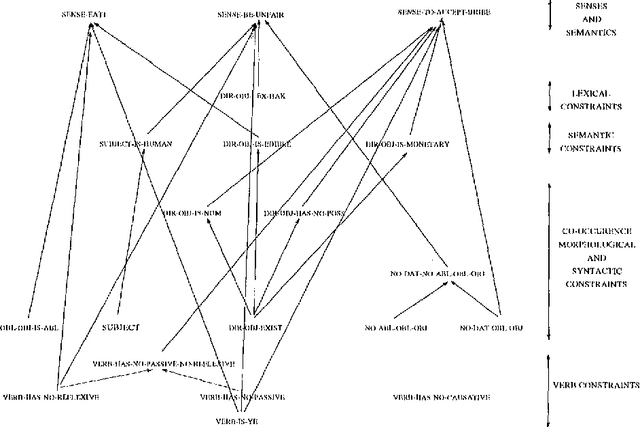
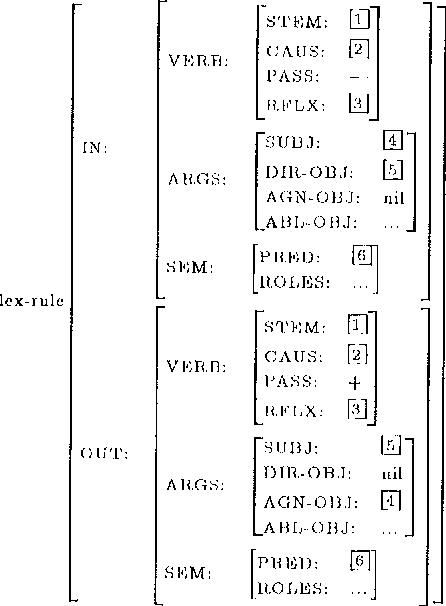
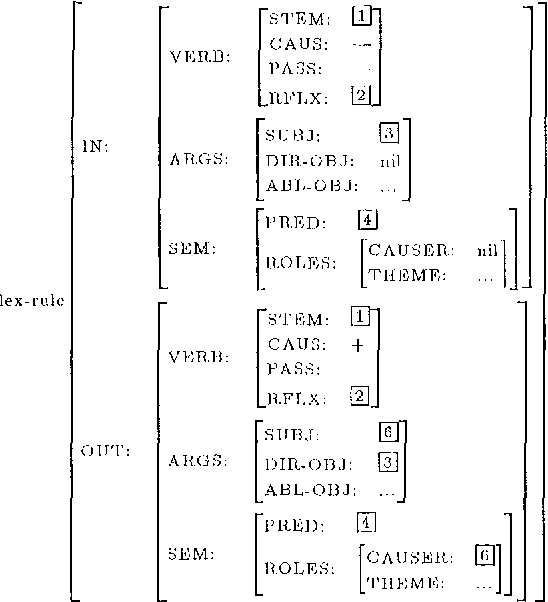
We present a constraint-based case frame lexicon architecture for bi-directional mapping between a syntactic case frame and a semantic frame. The lexicon uses a semantic sense as the basic unit and employs a multi-tiered constraint structure for the resolution of syntactic information into the appropriate senses and/or idiomatic usage. Valency changing transformations such as morphologically marked passivized or causativized forms are handled via lexical rules that manipulate case frames templates. The system has been implemented in a typed-feature system and applied to Turkish.
A Constraint-based Case Frame Lexicon Architecture
Jul 21, 1995In Turkish, (and possibly in many other languages) verbs often convey several meanings (some totally unrelated) when they are used with subjects, objects, oblique objects, adverbial adjuncts, with certain lexical, morphological, and semantic features, and co-occurrence restrictions. In addition to the usual sense variations due to selectional restrictions on verbal arguments, in most cases, the meaning conveyed by a case frame is idiomatic and not compositional, with subtle constraints. In this paper, we present an approach to building a constraint-based case frame lexicon for use in natural language processing in Turkish, whose prototype we have implemented under the TFS system developed at Univ. of Stuttgart. A number of observations that we have made on Turkish have indicated that we need something beyond the traditional transitive and intransitive distinction, and utilize a framework where verb valence is considered as the obligatory co-existence of an arbitrary subset of possible arguments along with the obligatory exclusion of certain others, relative to a verb sense. Additional morphological lexical and semantic constraints on the syntactic constituents organized as a 5-tier constraint hierarchy, are utilized to map a given syntactic structure case-fraame to a specific verb sense.