 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Hand-crafted Rules and Unsupervised Learning in Constraint-based Morphological Disambiguation
Paper and Code
Apr 12, 1996
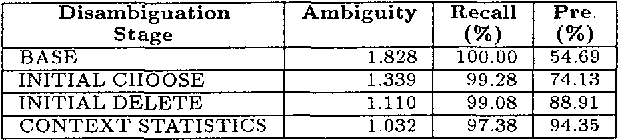
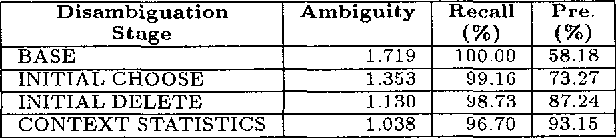
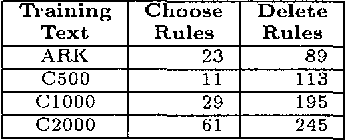
This paper presents a constraint-based morphological disambiguation approach that is applicable languages with complex morphology--specifically agglutinative languages with productive inflectional and derivational morphological phenomena. In certain respects, our approach has been motivated by Brill's recent work, but with the observation that his transformational approach is not directly applicable to languages like Turkish. Our system combines corpus independent hand-crafted constraint rules, constraint rules that are learned via unsupervised learning from a training corpus, and additional statistical information from the corpus to be morphologically disambiguated. The hand-crafted rules are linguistically motivated and tuned to improve precision without sacrificing recall. The unsupervised learning process produces two sets of rules: (i) choose rules which choose morphological parses of a lexical item satisfying constraint effectively discarding other parses, and (ii) delete rules, which delete parses satisfying a constraint. Our approach also uses a novel approach to unknown word processing by employing a secondary morphological processor which recovers any relevant inflectional and derivational information from a lexical item whose root is unknown. With this approach, well below 1 percent of the tokens remains as unknown in the texts we have experimented with. Our results indicate that by combining these hand-crafted,statistical and learned information sources, we can attain a recall of 96 to 97 percent with a corresponding precision of 93 to 94 percent, and ambiguity of 1.02 to 1.03 parses per token.