 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorphological Disambiguation by Voting Constraints
Paper and Code
Apr 25, 1997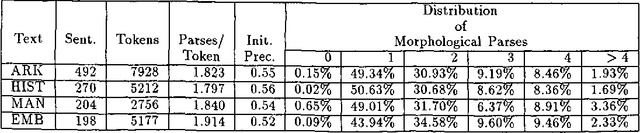

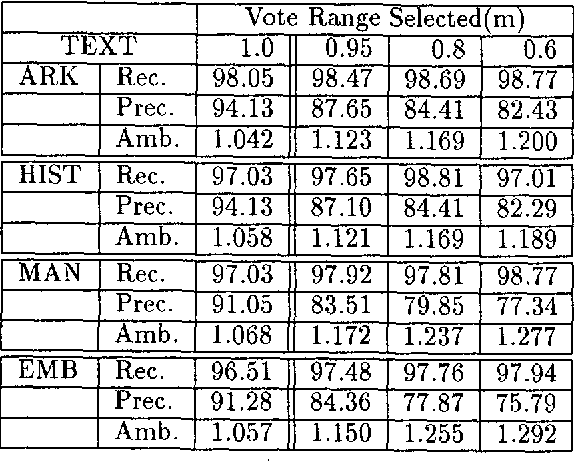
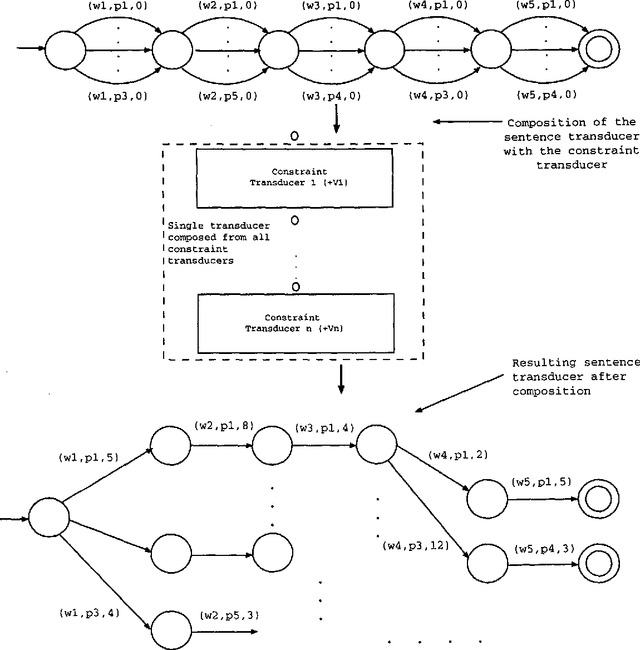
We present a constraint-based morphological disambiguation system in which individual constraints vote on matching morphological parses, and disambiguation of all the tokens in a sentence is performed at the end by selecting parses that receive the highest votes. This constraint application paradigm makes the outcome of the disambiguation independent of the rule sequence, and hence relieves the rule developer from worrying about potentially conflicting rule sequencing. Our results for disambiguating Turkish indicate that using about 500 constraint rules and some additional simple statistics, we can attain a recall of 95-96% and a precision of 94-95% with about 1.01 parses per token. Our system is implemented in Prolog and we are currently investigating an efficient implementation based on finite state transducers.