Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNullpointer at ArAIEval Shared Task: Arabic Propagandist Technique Detection with Token-to-Word Mapping in Sequence Tagging
Paper and Code
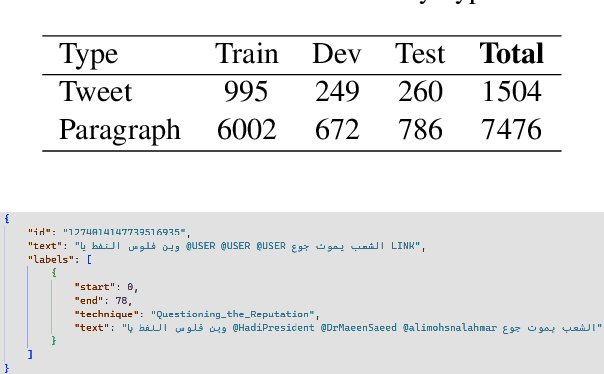
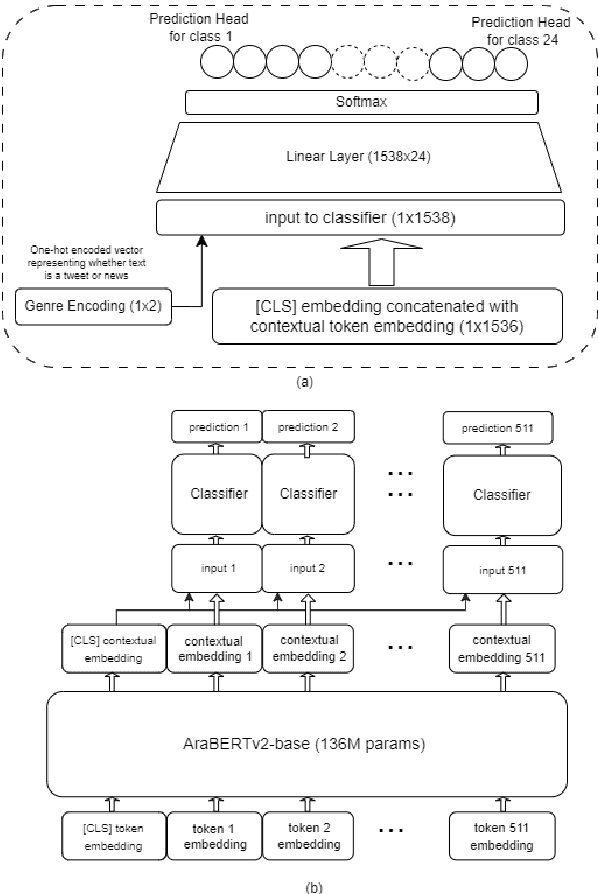
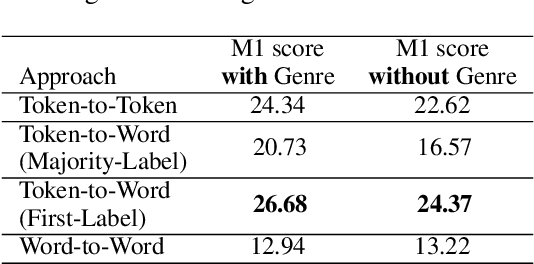
This paper investigates the optimization of propaganda technique detection in Arabic text, including tweets \& news paragraphs, from ArAIEval shared task 1. Our approach involves fine-tuning the AraBERT v2 model with a neural network classifier for sequence tagging. Experimental results show relying on the first token of the word for technique prediction produces the best performance. In addition, incorporating genre information as a feature further enhances the model's performance. Our system achieved a score of 25.41, placing us 4$^{th}$ on the leaderboard. Subsequent post-submission improvements further raised our score to 26.68.
* To appear in proceedings of 2024 Arabic NLP Conference
View paper on