 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robot Kinematics Model Estimation Using Inertial Sensors for On-Site Building Robotics
Oct 16, 2024



In order to make robots more useful in a variety of environments, they need to be highly portable so that they can be transported to wherever they are needed, and highly storable so that they can be stored when not in use. We propose "on-site robotics", which uses parts procured at the location where the robot will be active, and propose a new solution to the problem of portability and storability. In this paper, as a proof of concept for on-site robotics, we describe a method for estimating the kinematic model of a robot by using inertial measurement units (IMU) sensor module on rigid links, estimating the relative orientation between modules from angular velocity, and estimating the relative position from the measurement of centrifugal force. At the end of this paper, as an evaluation for this method, we present an experiment in which a robot made up of wooden sticks reaches a target position. In this experiment, even if the combination of the links is changed, the robot is able to reach the target position again immediately after estimation, showing that it can operate even after being reassembled. Our implementation is available on https://github.com/hiroya1224/urdf_estimation_with_imus .
Semantic Scene Difference Detection in Daily Life Patroling by Mobile Robots using Pre-Trained Large-Scale Vision-Language Model
Sep 28, 2023It is important for daily life support robots to detect changes in their environment and perform tasks. In the field of anomaly detection in computer vision, probabilistic and deep learning methods have been used to calculate the image distance. These methods calculate distances by focusing on image pixels. In contrast, this study aims to detect semantic changes in the daily life environment using the current development of large-scale vision-language models. Using its Visual Question Answering (VQA) model, we propose a method to detect semantic changes by applying multiple questions to a reference image and a current image and obtaining answers in the form of sentences. Unlike deep learning-based methods in anomaly detection, this method does not require any training or fine-tuning, is not affected by noise, and is sensitive to semantic state changes in the real world. In our experiments, we demonstrated the effectiveness of this method by applying it to a patrol task in a real-life environment using a mobile robot, Fetch Mobile Manipulator. In the future, it may be possible to add explanatory power to changes in the daily life environment through spoken language.
Foundation Model based Open Vocabulary Task Planning and Executive System for General Purpose Service Robots
Aug 07, 2023This paper describes a strategy for implementing a robotic system capable of performing General Purpose Service Robot (GPSR) tasks in robocup@home. The GPSR task is that a real robot hears a variety of commands in spoken language and executes a task in a daily life environment. To achieve the task, we integrate foundation models based inference system and a state machine task executable. The foundation models plan the task and detect objects with open vocabulary, and a state machine task executable manages each robot's actions. This system works stable, and we took first place in the RoboCup@home Japan Open 2022's GPSR with 130 points, more than 85 points ahead of the other teams.
Understanding Action Sequences based on Video Captioning for Learning-from-Observation
Dec 09, 2020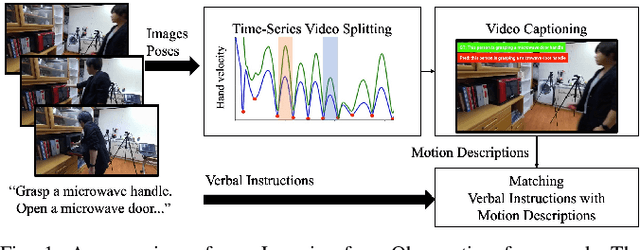

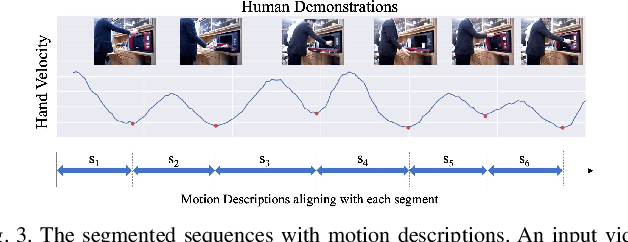

Learning actions from human demonstration video is promising for intelligent robotic systems. Extracting the exact section and re-observing the extracted video section in detail is important for imitating complex skills because human motions give valuable hints for robots. However, the general video understanding methods focus more on the understanding of the full frame,lacking consideration on extracting accurate sections and aligning them with the human's intent. We propose a Learning-from-Observation framework that splits and understands a video of a human demonstration with verbal instructions to extract accurate action sequences. The splitting is done based on local minimum points of the hand velocity, which align human daily-life actions with object-centered face contact transitions required for generating robot motion. Then, we extract a motion description on the split videos using video captioning techniques that are trained from our new daily-life action video dataset. Finally, we match the motion descriptions with the verbal instructions to understand the correct human intent and ignore the unintended actions inside the video. We evaluate the validity of hand velocity-based video splitting and demonstrate that it is effective. The experimental results on our new video captioning dataset focusing on daily-life human actions demonstrate the effectiveness of the proposed method. The source code, trained models, and the dataset will be made available.
A Learning-from-Observation Framework: One-Shot Robot Teaching for Grasp-Manipulation-Release Household Operations
Aug 24, 2020
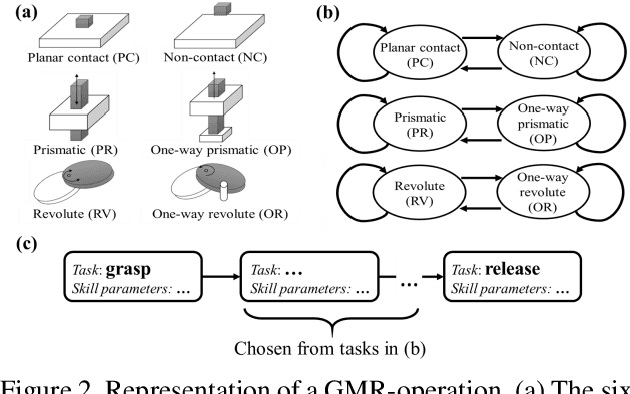


A household robot is expected to perform various manipulative operations with an understanding of the purpose of the task. To this end, robotic applications should provide an on-site robot teaching framework for non-experts. Here, we propose a Learning-from-Observation (LfO) framework for grasp-manipulation-release class household operations (GMR-operations). The framework maps human demonstrations to predefined task models through one-shot teaching. Each task model contains both high-level knowledge regarding the geometric constraints of tasks and low-level knowledge related to human postures. The key goal of this study is to design a task model that 1) covers various GMR-operations and 2) includes human postures to achieve tasks. We verify the applicability of our framework by testing the novel LfO system with a real robot. In addition, we quantify the coverage of the task model by analyzing online videos of household operations. Within the context of one-shot robot teaching, the contribution of this study is a framework that covers various GMR-operations and mimics human postures during operation.
Verbal Focus-of-Attention System for Learning-from-Demonstration
Aug 06, 2020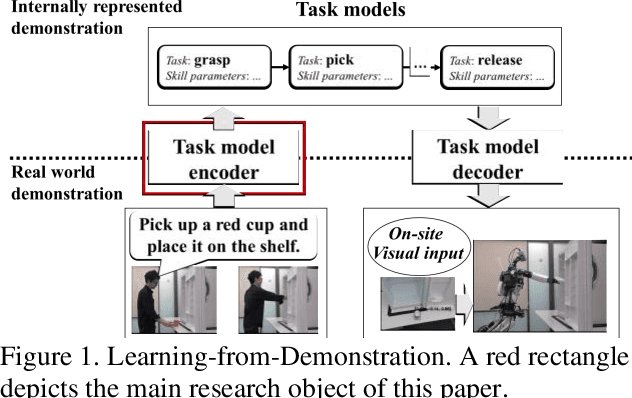
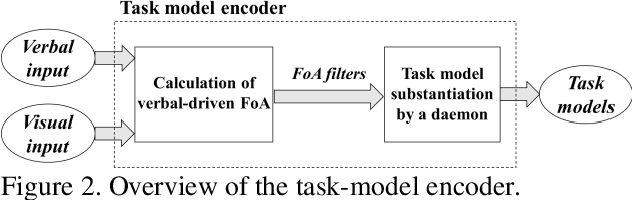
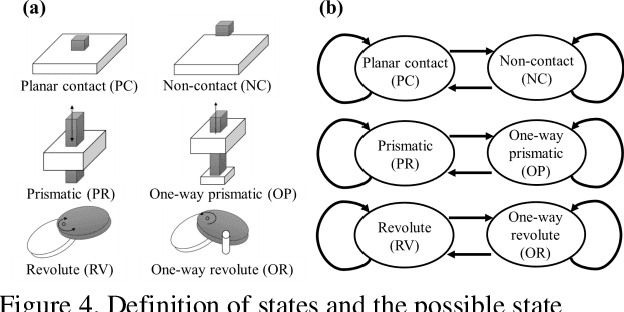
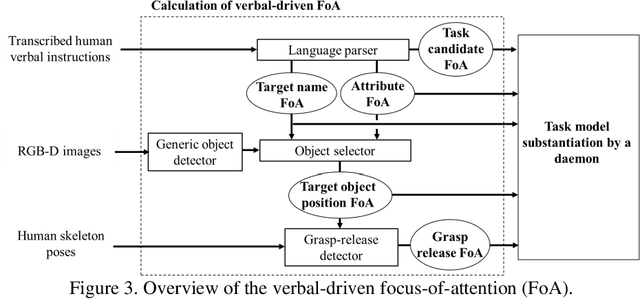
The Learning-from-Demonstration (LfD) framework aims to map human demonstrations to a robot to reduce programming effort. To this end, an LfD system encodes a human demonstration into a series of execution units for a robot, referred to as task models. Although previous research has proposed successful task-model encoders that analyze images and human body movements, the encoders have been designed in environments without noise. Therefore, there has been little discussion on how to guide a task-model encoder in a scene with spatio-temporal noises such as cluttered objects or unrelated human body movements. In human-to-human demonstrations, verbal instructions play a role in guiding an observer's visual attention. Inspired by the function of verbal instructions, we propose a verbal focus-of-attention (FoA) system (i.e., spatio-temporal filters) to guide a task-model encoder. For object manipulation, the encoder first recognizes a target-object name and its attributes from verbal instructions. The information serves as a where-to-look FoA filter to confine the areas where the target object existed in the demonstration. The encoder next detects the timings of grasp and release tasks that occur in the filtered area. The timings serve as a when-to-look FoA filter to confine the period when the demonstrator manipulated the object. Finally, the task-model encoder recognizes task models by employing the FoA filters. The contributions of this paper are: (1) to propose verbal FoA for LfD; (2) to design an algorithm to calculate FoA filters from verbal input; (3) to demonstrate the effectiveness of a verbal-driven FoA by testing an implemented LfD system in noisy environments.