 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFront Hair Styling Robot System Using Path Planning for Root-Centric Strand Adjustment
Jan 19, 2025



Hair styling is a crucial aspect of personal grooming, significantly influenced by the appearance of front hair. While brushing is commonly used both to detangle hair and for styling purposes, existing research primarily focuses on robotic systems for detangling hair, with limited exploration into robotic hair styling. This research presents a novel robotic system designed to automatically adjust front hairstyles, with an emphasis on path planning for root-centric strand adjustment. The system utilizes images to compare the current hair state with the desired target state through an orientation map of hair strands. By concentrating on the differences in hair orientation and specifically targeting adjustments at the root of each strand, the system performs detailed styling tasks. The path planning approach ensures effective alignment of the hairstyle with the target, and a closed-loop mechanism refines these adjustments to accurately evolve the hairstyle towards the desired outcome. Experimental results demonstrate that the proposed system achieves a high degree of similarity and consistency in front hair styling, showing promising results for automated, precise hairstyle adjustments.
Remote Life Support Robot Interface System for Global Task Planning and Local Action Expansion Using Foundation Models
Nov 15, 2024
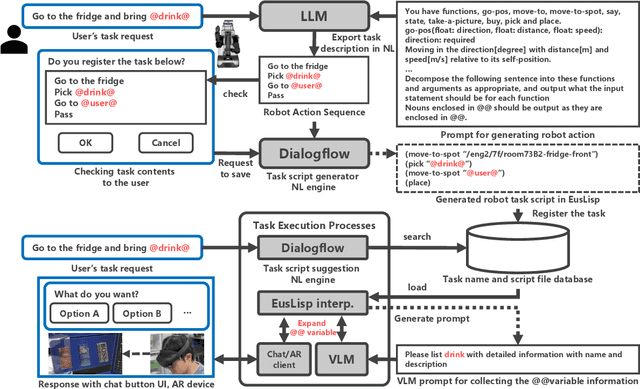
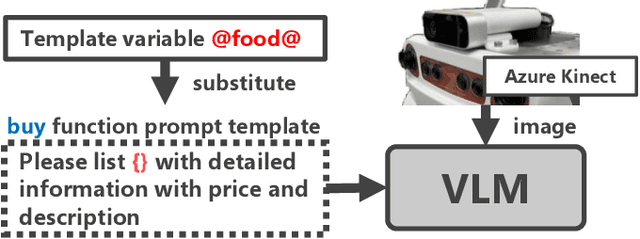
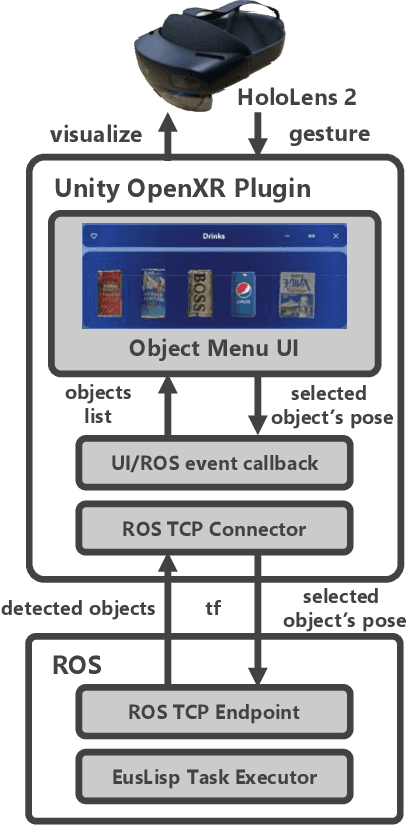
Robot systems capable of executing tasks based on language instructions have been actively researched. It is challenging to convey uncertain information that can only be determined on-site with a single language instruction to the robot. In this study, we propose a system that includes ambiguous parts as template variables in language instructions to communicate the information to be collected and the options to be presented to the robot for predictable uncertain events. This study implements prompt generation for each robot action function based on template variables to collect information, and a feedback system for presenting and selecting options based on template variables for user-to-robot communication. The effectiveness of the proposed system was demonstrated through its application to real-life support tasks performed by the robot.
Robotic State Recognition with Image-to-Text Retrieval Task of Pre-Trained Vision-Language Model and Black-Box Optimization
Oct 30, 2024State recognition of the environment and objects, such as the open/closed state of doors and the on/off of lights, is indispensable for robots that perform daily life support and security tasks. Until now, state recognition methods have been based on training neural networks from manual annotations, preparing special sensors for the recognition, or manually programming to extract features from point clouds or raw images. In contrast, we propose a robotic state recognition method using a pre-trained vision-language model, which is capable of Image-to-Text Retrieval (ITR) tasks. We prepare several kinds of language prompts in advance, calculate the similarity between these prompts and the current image by ITR, and perform state recognition. By applying the optimal weighting to each prompt using black-box optimization, state recognition can be performed with higher accuracy. Experiments show that this theory enables a variety of state recognitions by simply preparing multiple prompts without retraining neural networks or manual programming. In addition, since only prompts and their weights need to be prepared for each recognizer, there is no need to prepare multiple models, which facilitates resource management. It is possible to recognize the open/closed state of transparent doors, the state of whether water is running or not from a faucet, and even the qualitative state of whether a kitchen is clean or not, which have been challenging so far, through language.
Real-World Cooking Robot System from Recipes Based on Food State Recognition Using Foundation Models and PDDL
Oct 07, 2024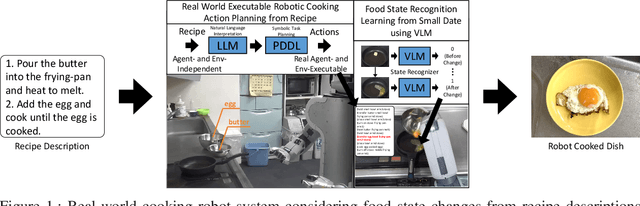



Although there is a growing demand for cooking behaviours as one of the expected tasks for robots, a series of cooking behaviours based on new recipe descriptions by robots in the real world has not yet been realised. In this study, we propose a robot system that integrates real-world executable robot cooking behaviour planning using the Large Language Model (LLM) and classical planning of PDDL descriptions, and food ingredient state recognition learning from a small number of data using the Vision-Language model (VLM). We succeeded in experiments in which PR2, a dual-armed wheeled robot, performed cooking from arranged new recipes in a real-world environment, and confirmed the effectiveness of the proposed system.
Robotic Environmental State Recognition with Pre-Trained Vision-Language Models and Black-Box Optimization
Sep 26, 2024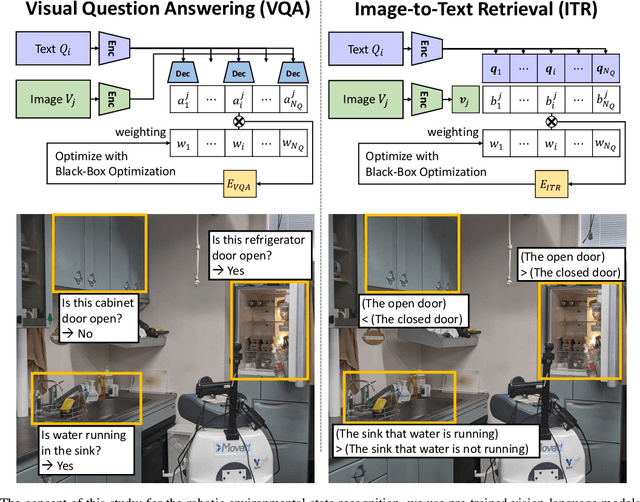


In order for robots to autonomously navigate and operate in diverse environments, it is essential for them to recognize the state of their environment. On the other hand, the environmental state recognition has traditionally involved distinct methods tailored to each state to be recognized. In this study, we perform a unified environmental state recognition for robots through the spoken language with pre-trained large-scale vision-language models. We apply Visual Question Answering and Image-to-Text Retrieval, which are tasks of Vision-Language Models. We show that with our method, it is possible to recognize not only whether a room door is open/closed, but also whether a transparent door is open/closed and whether water is running in a sink, without training neural networks or manual programming. In addition, the recognition accuracy can be improved by selecting appropriate texts from the set of prepared texts based on black-box optimization. For each state recognition, only the text set and its weighting need to be changed, eliminating the need to prepare multiple different models and programs, and facilitating the management of source code and computer resource. We experimentally demonstrate the effectiveness of our method and apply it to the recognition behavior on a mobile robot, Fetch.
Reflex-Based Open-Vocabulary Navigation without Prior Knowledge Using Omnidirectional Camera and Multiple Vision-Language Models
Aug 21, 2024Various robot navigation methods have been developed, but they are mainly based on Simultaneous Localization and Mapping (SLAM), reinforcement learning, etc., which require prior map construction or learning. In this study, we consider the simplest method that does not require any map construction or learning, and execute open-vocabulary navigation of robots without any prior knowledge to do this. We applied an omnidirectional camera and pre-trained vision-language models to the robot. The omnidirectional camera provides a uniform view of the surroundings, thus eliminating the need for complicated exploratory behaviors including trajectory generation. By applying multiple pre-trained vision-language models to this omnidirectional image and incorporating reflective behaviors, we show that navigation becomes simple and does not require any prior setup. Interesting properties and limitations of our method are discussed based on experiments with the mobile robot Fetch.
Self-Supervised Learning of Visual Servoing for Low-Rigidity Robots Considering Temporal Body Changes
May 20, 2024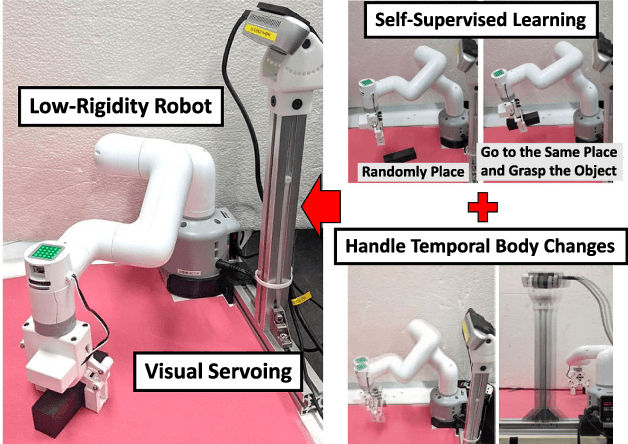
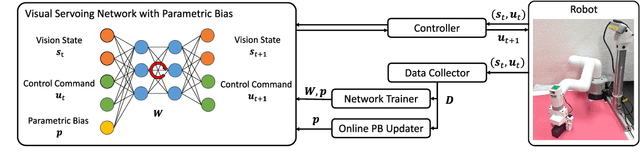
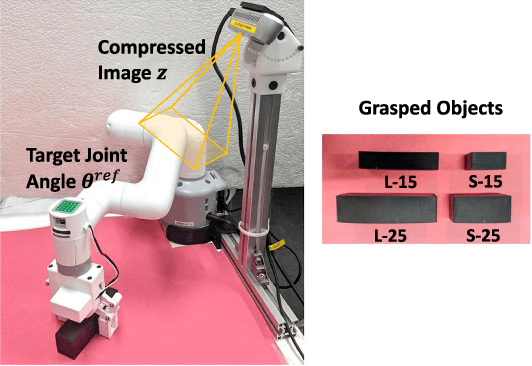

In this study, we investigate object grasping by visual servoing in a low-rigidity robot. It is difficult for a low-rigidity robot to handle its own body as intended compared to a rigid robot, and calibration between vision and body takes some time. In addition, the robot must constantly adapt to changes in its body, such as the change in camera position and change in joints due to aging. Therefore, we develop a method for a low-rigidity robot to autonomously learn visual servoing of its body. We also develop a mechanism that can adaptively change its visual servoing according to temporal body changes. We apply our method to a low-rigidity 6-axis arm, MyCobot, and confirm its effectiveness by conducting object grasping experiments based on visual servoing.
Learning-Based Wiping Behavior of Low-Rigidity Robots Considering Various Surface Materials and Task Definitions
Mar 17, 2024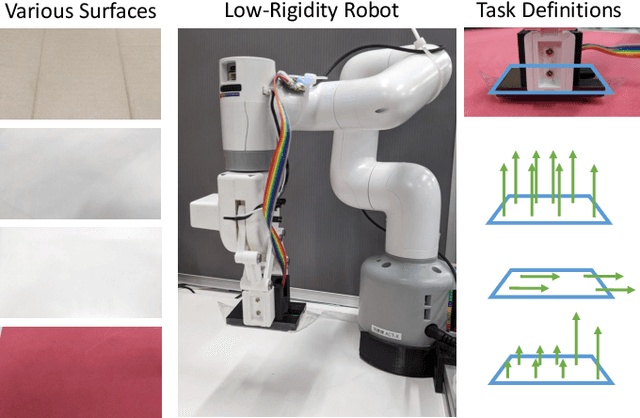
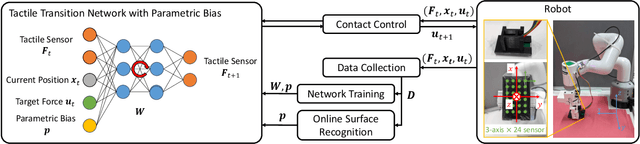

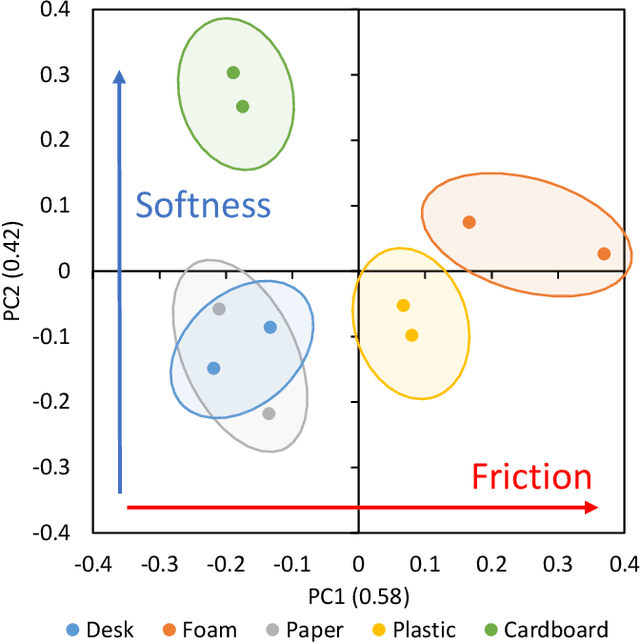
Wiping behavior is a task of tracing the surface of an object while feeling the force with the palm of the hand. It is necessary to adjust the force and posture appropriately considering the various contact conditions felt by the hand. Several studies have been conducted on the wiping motion, however, these studies have only dealt with a single surface material, and have only considered the application of the amount of appropriate force, lacking intelligent movements to ensure that the force is applied either evenly to the entire surface or to a certain area. Depending on the surface material, the hand posture and pressing force should be varied appropriately, and this is highly dependent on the definition of the task. Also, most of the movements are executed by high-rigidity robots that are easy to model, and few movements are executed by robots that are low-rigidity but therefore have a small risk of damage due to excessive contact. So, in this study, we develop a method of motion generation based on the learned prediction of contact force during the wiping motion of a low-rigidity robot. We show that MyCobot, which is made of low-rigidity resin, can appropriately perform wiping behaviors on a plane with multiple surface materials based on various task definitions.
Continuous Object State Recognition for Cooking Robots Using Pre-Trained Vision-Language Models and Black-box Optimization
Mar 13, 2024



The state recognition of the environment and objects by robots is generally based on the judgement of the current state as a classification problem. On the other hand, state changes of food in cooking happen continuously and need to be captured not only at a certain time point but also continuously over time. In addition, the state changes of food are complex and cannot be easily described by manual programming. Therefore, we propose a method to recognize the continuous state changes of food for cooking robots through the spoken language using pre-trained large-scale vision-language models. By using models that can compute the similarity between images and texts continuously over time, we can capture the state changes of food while cooking. We also show that by adjusting the weighting of each text prompt based on fitting the similarity changes to a sigmoid function and then performing black-box optimization, more accurate and robust continuous state recognition can be achieved. We demonstrate the effectiveness and limitations of this method by performing the recognition of water boiling, butter melting, egg cooking, and onion stir-frying.
* accepted at IEEE Robotics and Automation Letters (RA-L), website - https://haraduka.github.io/continuous-state-recognition/
Daily Assistive View Control Learning of Low-Cost Low-Rigidity Robot via Large-Scale Vision-Language Model
Dec 12, 2023



In this study, we develop a simple daily assistive robot that controls its own vision according to linguistic instructions. The robot performs several daily tasks such as recording a user's face, hands, or screen, and remotely capturing images of desired locations. To construct such a robot, we combine a pre-trained large-scale vision-language model with a low-cost low-rigidity robot arm. The correlation between the robot's physical and visual information is learned probabilistically using a neural network, and changes in the probability distribution based on changes in time and environment are considered by parametric bias, which is a learnable network input variable. We demonstrate the effectiveness of this learning method by open-vocabulary view control experiments with an actual robot arm, MyCobot.