 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerbal Focus-of-Attention System for Learning-from-Demonstration
Paper and Code
Aug 06, 2020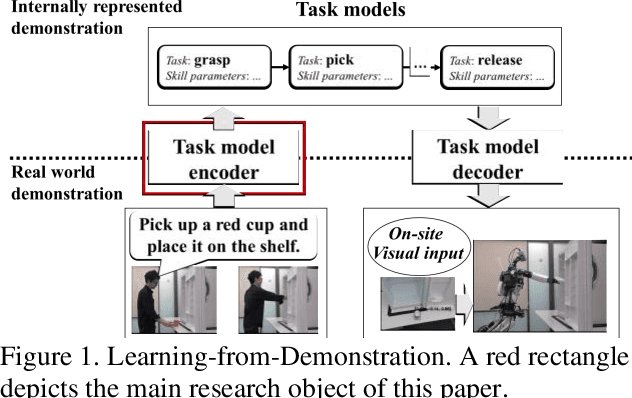
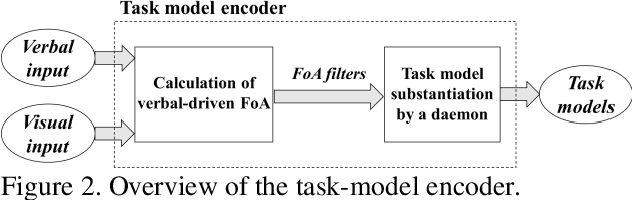
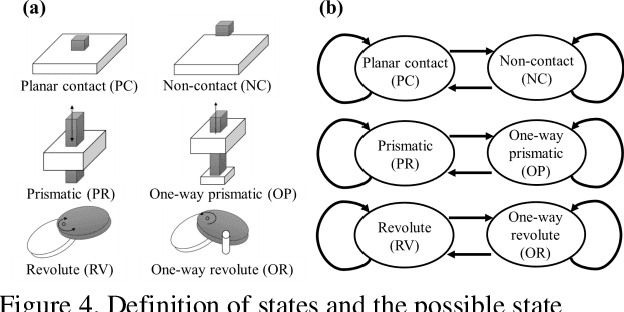
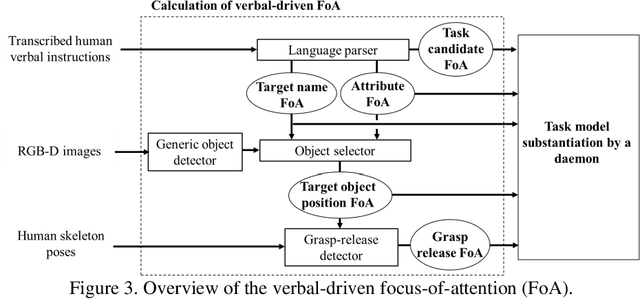
The Learning-from-Demonstration (LfD) framework aims to map human demonstrations to a robot to reduce programming effort. To this end, an LfD system encodes a human demonstration into a series of execution units for a robot, referred to as task models. Although previous research has proposed successful task-model encoders that analyze images and human body movements, the encoders have been designed in environments without noise. Therefore, there has been little discussion on how to guide a task-model encoder in a scene with spatio-temporal noises such as cluttered objects or unrelated human body movements. In human-to-human demonstrations, verbal instructions play a role in guiding an observer's visual attention. Inspired by the function of verbal instructions, we propose a verbal focus-of-attention (FoA) system (i.e., spatio-temporal filters) to guide a task-model encoder. For object manipulation, the encoder first recognizes a target-object name and its attributes from verbal instructions. The information serves as a where-to-look FoA filter to confine the areas where the target object existed in the demonstration. The encoder next detects the timings of grasp and release tasks that occur in the filtered area. The timings serve as a when-to-look FoA filter to confine the period when the demonstrator manipulated the object. Finally, the task-model encoder recognizes task models by employing the FoA filters. The contributions of this paper are: (1) to propose verbal FoA for LfD; (2) to design an algorithm to calculate FoA filters from verbal input; (3) to demonstrate the effectiveness of a verbal-driven FoA by testing an implemented LfD system in noisy environments.