 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Action Sequences based on Video Captioning for Learning-from-Observation
Paper and Code
Dec 09, 2020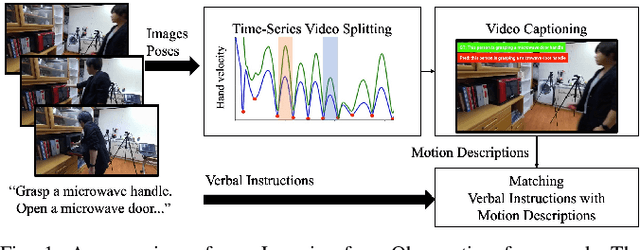

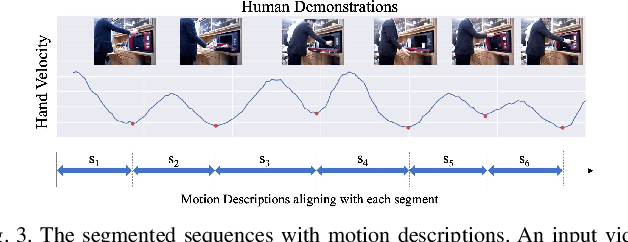

Learning actions from human demonstration video is promising for intelligent robotic systems. Extracting the exact section and re-observing the extracted video section in detail is important for imitating complex skills because human motions give valuable hints for robots. However, the general video understanding methods focus more on the understanding of the full frame,lacking consideration on extracting accurate sections and aligning them with the human's intent. We propose a Learning-from-Observation framework that splits and understands a video of a human demonstration with verbal instructions to extract accurate action sequences. The splitting is done based on local minimum points of the hand velocity, which align human daily-life actions with object-centered face contact transitions required for generating robot motion. Then, we extract a motion description on the split videos using video captioning techniques that are trained from our new daily-life action video dataset. Finally, we match the motion descriptions with the verbal instructions to understand the correct human intent and ignore the unintended actions inside the video. We evaluate the validity of hand velocity-based video splitting and demonstrate that it is effective. The experimental results on our new video captioning dataset focusing on daily-life human actions demonstrate the effectiveness of the proposed method. The source code, trained models, and the dataset will be made available.