 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxelGen: Generating Proteins as 3D Densities
Jun 24, 2025We develop ProxelGen, a protein structure generative model that operates on 3D densities as opposed to the prevailing 3D point cloud representations. Representing proteins as voxelized densities, or proxels, enables new tasks and conditioning capabilities. We generate proteins encoded as proxels via a 3D CNN-based VAE in conjunction with a diffusion model operating on its latent space. Compared to state-of-the-art models, ProxelGen's samples achieve higher novelty, better FID scores, and the same level of designability as the training set. ProxelGen's advantages are demonstrated in a standard motif scaffolding benchmark, and we show how 3D density-based generation allows for more flexible shape conditioning.
ET-Flow: Equivariant Flow-Matching for Molecular Conformer Generation
Oct 29, 2024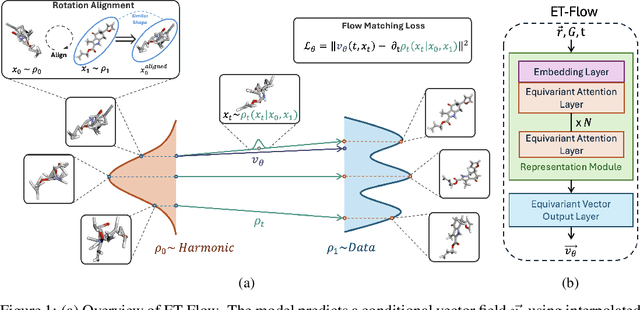
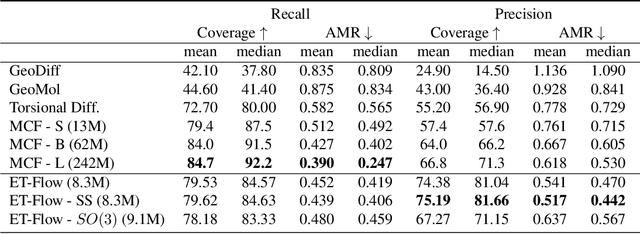
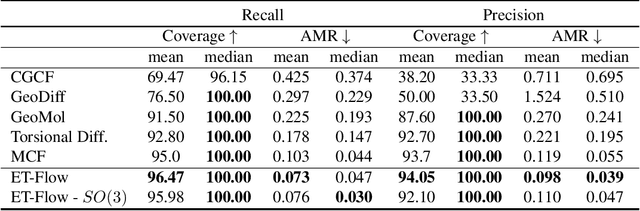
Predicting low-energy molecular conformations given a molecular graph is an important but challenging task in computational drug discovery. Existing state-of-the-art approaches either resort to large scale transformer-based models that diffuse over conformer fields, or use computationally expensive methods to generate initial structures and diffuse over torsion angles. In this work, we introduce Equivariant Transformer Flow (ET-Flow). We showcase that a well-designed flow matching approach with equivariance and harmonic prior alleviates the need for complex internal geometry calculations and large architectures, contrary to the prevailing methods in the field. Our approach results in a straightforward and scalable method that directly operates on all-atom coordinates with minimal assumptions. With the advantages of equivariance and flow matching, ET-Flow significantly increases the precision and physical validity of the generated conformers, while being a lighter model and faster at inference. Code is available https://github.com/shenoynikhil/ETFlow.
CodonMPNN for Organism Specific and Codon Optimal Inverse Folding
Sep 25, 2024



Generating protein sequences conditioned on protein structures is an impactful technique for protein engineering. When synthesizing engineered proteins, they are commonly translated into DNA and expressed in an organism such as yeast. One difficulty in this process is that the expression rates can be low due to suboptimal codon sequences for expressing a protein in a host organism. We propose CodonMPNN, which generates a codon sequence conditioned on a protein backbone structure and an organism label. If naturally occurring DNA sequences are close to codon optimality, CodonMPNN could learn to generate codon sequences with higher expression yields than heuristic codon choices for generated amino acid sequences. Experiments show that CodonMPNN retains the performance of previous inverse folding approaches and recovers wild-type codons more frequently than baselines. Furthermore, CodonMPNN has a higher likelihood of generating high-fitness codon sequences than low-fitness codon sequences for the same protein sequence. Code is available at https://github.com/HannesStark/CodonMPNN.
Dirichlet Flow Matching with Applications to DNA Sequence Design
Feb 08, 2024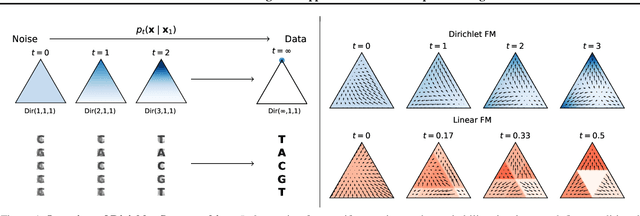

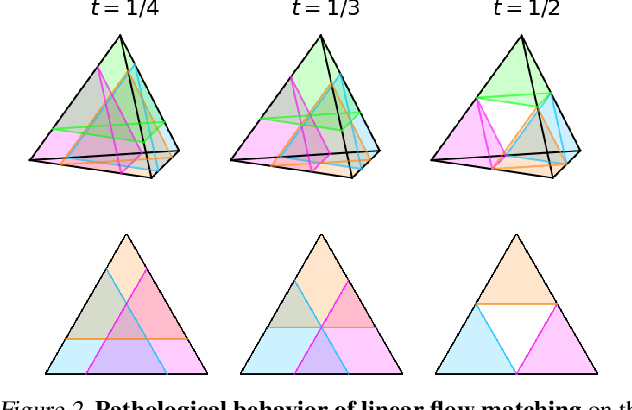
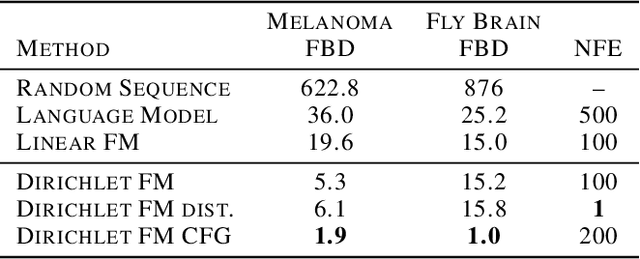
Discrete diffusion or flow models could enable faster and more controllable sequence generation than autoregressive models. We show that na\"ive linear flow matching on the simplex is insufficient toward this goal since it suffers from discontinuities in the training target and further pathologies. To overcome this, we develop Dirichlet flow matching on the simplex based on mixtures of Dirichlet distributions as probability paths. In this framework, we derive a connection between the mixtures' scores and the flow's vector field that allows for classifier and classifier-free guidance. Further, we provide distilled Dirichlet flow matching, which enables one-step sequence generation with minimal performance hits, resulting in $O(L)$ speedups compared to autoregressive models. On complex DNA sequence generation tasks, we demonstrate superior performance compared to all baselines in distributional metrics and in achieving desired design targets for generated sequences. Finally, we show that our classifier-free guidance approach improves unconditional generation and is effective for generating DNA that satisfies design targets. Code is available at https://github.com/HannesStark/dirichlet-flow-matching.