 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Assisted Adaptive Sharpening Scheme Considering Bitrate and Quality Tradeoff
Aug 12, 2025Sharpening is a widely adopted technique to improve video quality, which can effectively emphasize textures and alleviate blurring. However, increasing the sharpening level comes with a higher video bitrate, resulting in degraded Quality of Service (QoS). Furthermore, the video quality does not necessarily improve with increasing sharpening levels, leading to issues such as over-sharpening. Clearly, it is essential to figure out how to boost video quality with a proper sharpening level while also controlling bandwidth costs effectively. This paper thus proposes a novel Frequency-assisted Sharpening level Prediction model (FreqSP). We first label each video with the sharpening level correlating to the optimal bitrate and quality tradeoff as ground truth. Then taking uncompressed source videos as inputs, the proposed FreqSP leverages intricate CNN features and high-frequency components to estimate the optimal sharpening level. Extensive experiments demonstrate the effectiveness of our method.
CaRDiff: Video Salient Object Ranking Chain of Thought Reasoning for Saliency Prediction with Diffusion
Aug 21, 2024Video saliency prediction aims to identify the regions in a video that attract human attention and gaze, driven by bottom-up features from the video and top-down processes like memory and cognition. Among these top-down influences, language plays a crucial role in guiding attention by shaping how visual information is interpreted. Existing methods primarily focus on modeling perceptual information while neglecting the reasoning process facilitated by language, where ranking cues are crucial outcomes of this process and practical guidance for saliency prediction. In this paper, we propose CaRDiff (Caption, Rank, and generate with Diffusion), a framework that imitates the process by integrating a multimodal large language model (MLLM), a grounding module, and a diffusion model, to enhance video saliency prediction. Specifically, we introduce a novel prompting method VSOR-CoT (Video Salient Object Ranking Chain of Thought), which utilizes an MLLM with a grounding module to caption video content and infer salient objects along with their rankings and positions. This process derives ranking maps that can be sufficiently leveraged by the diffusion model to decode the saliency maps for the given video accurately. Extensive experiments show the effectiveness of VSOR-CoT in improving the performance of video saliency prediction. The proposed CaRDiff performs better than state-of-the-art models on the MVS dataset and demonstrates cross-dataset capabilities on the DHF1k dataset through zero-shot evaluation.
NTIRE 2022 Challenge on High Dynamic Range Imaging: Methods and Results
May 25, 2022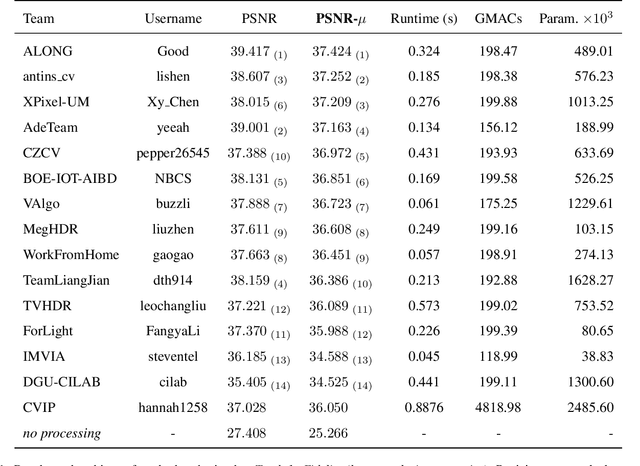
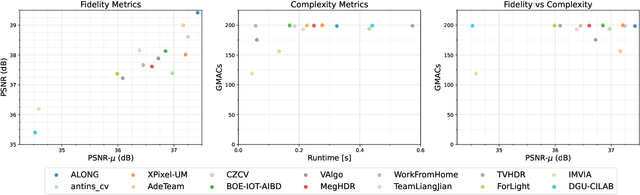
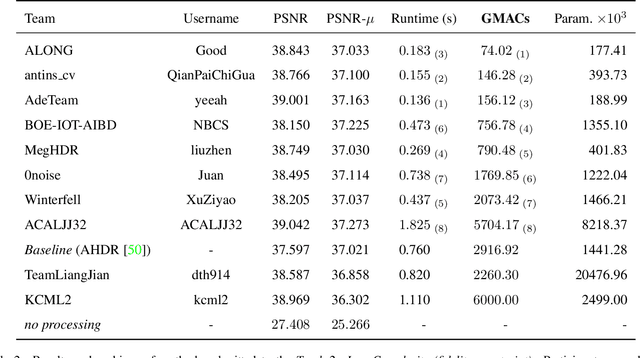
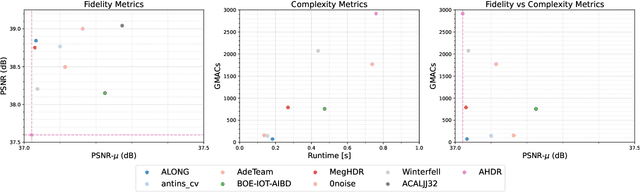
This paper reviews the challenge on constrained high dynamic range (HDR) imaging that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2022. This manuscript focuses on the competition set-up, datasets, the proposed methods and their results. The challenge aims at estimating an HDR image from multiple respective low dynamic range (LDR) observations, which might suffer from under- or over-exposed regions and different sources of noise. The challenge is composed of two tracks with an emphasis on fidelity and complexity constraints: In Track 1, participants are asked to optimize objective fidelity scores while imposing a low-complexity constraint (i.e. solutions can not exceed a given number of operations). In Track 2, participants are asked to minimize the complexity of their solutions while imposing a constraint on fidelity scores (i.e. solutions are required to obtain a higher fidelity score than the prescribed baseline). Both tracks use the same data and metrics: Fidelity is measured by means of PSNR with respect to a ground-truth HDR image (computed both directly and with a canonical tonemapping operation), while complexity metrics include the number of Multiply-Accumulate (MAC) operations and runtime (in seconds).
* CVPR Workshops 2022. 15 pages, 21 figures, 2 tables
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021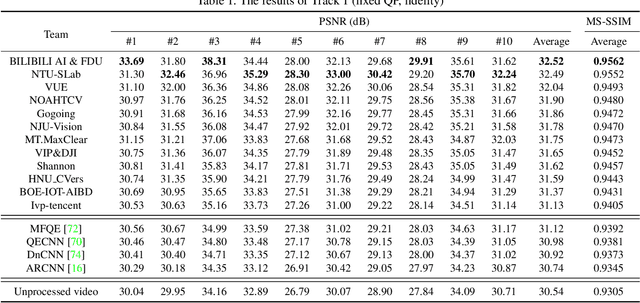
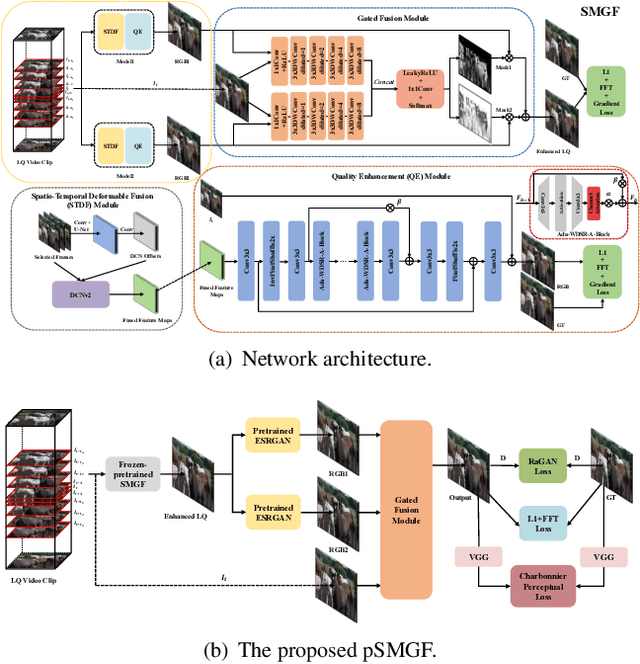
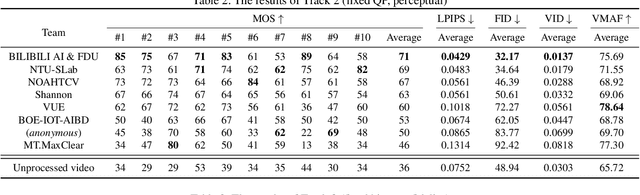
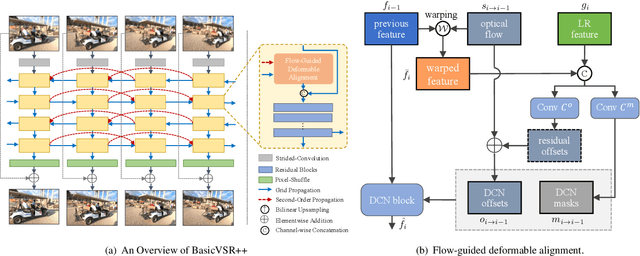
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh