 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Script is All You Need: An Agentic Framework for Long-Horizon Dialogue-to-Cinematic Video Generation
Jan 27, 2026Recent advances in video generation have produced models capable of synthesizing stunning visual content from simple text prompts. However, these models struggle to generate long-form, coherent narratives from high-level concepts like dialogue, revealing a ``semantic gap'' between a creative idea and its cinematic execution. To bridge this gap, we introduce a novel, end-to-end agentic framework for dialogue-to-cinematic-video generation. Central to our framework is ScripterAgent, a model trained to translate coarse dialogue into a fine-grained, executable cinematic script. To enable this, we construct ScriptBench, a new large-scale benchmark with rich multimodal context, annotated via an expert-guided pipeline. The generated script then guides DirectorAgent, which orchestrates state-of-the-art video models using a cross-scene continuous generation strategy to ensure long-horizon coherence. Our comprehensive evaluation, featuring an AI-powered CriticAgent and a new Visual-Script Alignment (VSA) metric, shows our framework significantly improves script faithfulness and temporal fidelity across all tested video models. Furthermore, our analysis uncovers a crucial trade-off in current SOTA models between visual spectacle and strict script adherence, providing valuable insights for the future of automated filmmaking.
MSR: Making Self-supervised learning Robust to Aggressive Augmentations
Jun 04, 2022

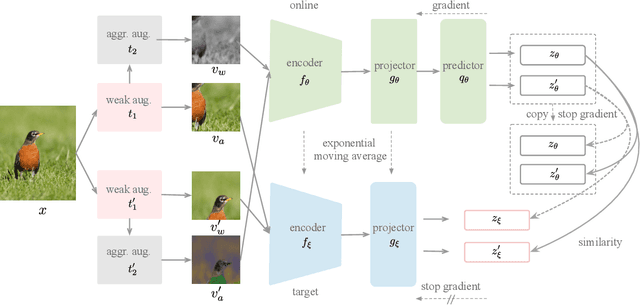

Most recent self-supervised learning methods learn visual representation by contrasting different augmented views of images. Compared with supervised learning, more aggressive augmentations have been introduced to further improve the diversity of training pairs. However, aggressive augmentations may distort images' structures leading to a severe semantic shift problem that augmented views of the same image may not share the same semantics, thus degrading the transfer performance. To address this problem, we propose a new SSL paradigm, which counteracts the impact of semantic shift by balancing the role of weak and aggressively augmented pairs. Specifically, semantically inconsistent pairs are of minority and we treat them as noisy pairs. Note that deep neural networks (DNNs) have a crucial memorization effect that DNNs tend to first memorize clean (majority) examples before overfitting to noisy (minority) examples. Therefore, we set a relatively large weight for aggressively augmented data pairs at the early learning stage. With the training going on, the model begins to overfit noisy pairs. Accordingly, we gradually reduce the weights of aggressively augmented pairs. In doing so, our method can better embrace the aggressive augmentations and neutralize the semantic shift problem. Experiments show that our model achieves 73.1% top-1 accuracy on ImageNet-1K with ResNet-50 for 200 epochs, which is a 2.5% improvement over BYOL. Moreover, experiments also demonstrate that the learned representations can transfer well for various downstream tasks.
Understanding and Improving Early Stopping for Learning with Noisy Labels
Jun 30, 2021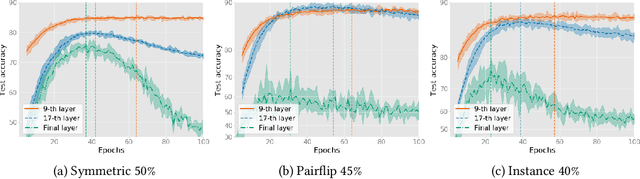

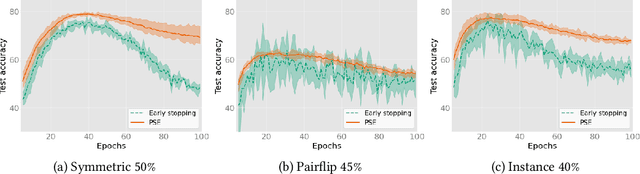

The memorization effect of deep neural network (DNN) plays a pivotal role in many state-of-the-art label-noise learning methods. To exploit this property, the early stopping trick, which stops the optimization at the early stage of training, is usually adopted. Current methods generally decide the early stopping point by considering a DNN as a whole. However, a DNN can be considered as a composition of a series of layers, and we find that the latter layers in a DNN are much more sensitive to label noise, while their former counterparts are quite robust. Therefore, selecting a stopping point for the whole network may make different DNN layers antagonistically affected each other, thus degrading the final performance. In this paper, we propose to separate a DNN into different parts and progressively train them to address this problem. Instead of the early stopping, which trains a whole DNN all at once, we initially train former DNN layers by optimizing the DNN with a relatively large number of epochs. During training, we progressively train the latter DNN layers by using a smaller number of epochs with the preceding layers fixed to counteract the impact of noisy labels. We term the proposed method as progressive early stopping (PES). Despite its simplicity, compared with the early stopping, PES can help to obtain more promising and stable results. Furthermore, by combining PES with existing approaches on noisy label training, we achieve state-of-the-art performance on image classification benchmarks.
Estimating Instance-dependent Label-noise Transition Matrix using DNNs
May 27, 2021
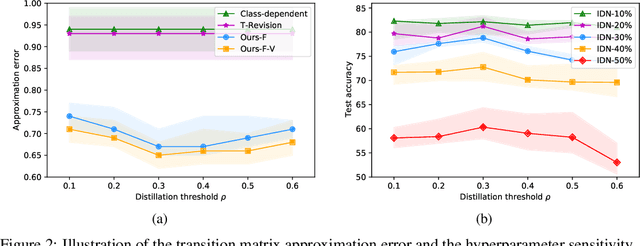


In label-noise learning, estimating the transition matrix is a hot topic as the matrix plays an important role in building statistically consistent classifiers. Traditionally, the transition from clean distribution to noisy distribution (i.e., clean label transition matrix) has been widely exploited to learn a clean label classifier by employing the noisy data. Motivated by that classifiers mostly output Bayes optimal labels for prediction, in this paper, we study to directly model the transition from Bayes optimal distribution to noisy distribution (i.e., Bayes label transition matrix) and learn a Bayes optimal label classifier. Note that given only noisy data, it is ill-posed to estimate either the clean label transition matrix or the Bayes label transition matrix. But favorably, Bayes optimal labels are less uncertain compared with the clean labels, i.e., the class posteriors of Bayes optimal labels are one-hot vectors while those of clean labels are not. This enables two advantages to estimate the Bayes label transition matrix, i.e., (a) we could theoretically recover a set of Bayes optimal labels under mild conditions; (b) the feasible solution space is much smaller. By exploiting the advantages, we estimate the Bayes label transition matrix by employing a deep neural network in a parameterized way, leading to better generalization and superior classification performance.
DistillHash: Unsupervised Deep Hashing by Distilling Data Pairs
May 09, 2019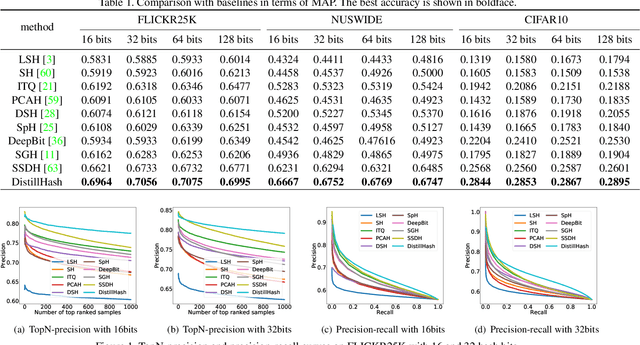
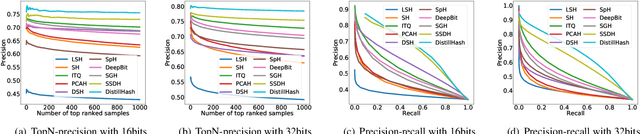

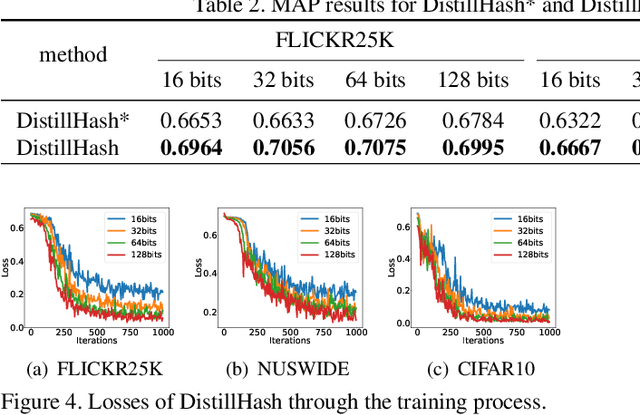
Due to the high storage and search efficiency, hashing has become prevalent for large-scale similarity search. Particularly, deep hashing methods have greatly improved the search performance under supervised scenarios. In contrast, unsupervised deep hashing models can hardly achieve satisfactory performance due to the lack of reliable supervisory similarity signals. To address this issue, we propose a novel deep unsupervised hashing model, dubbed DistillHash, which can learn a distilled data set consisted of data pairs, which have confidence similarity signals. Specifically, we investigate the relationship between the initial noisy similarity signals learned from local structures and the semantic similarity labels assigned by a Bayes optimal classifier. We show that under a mild assumption, some data pairs, of which labels are consistent with those assigned by the Bayes optimal classifier, can be potentially distilled. Inspired by this fact, we design a simple yet effective strategy to distill data pairs automatically and further adopt a Bayesian learning framework to learn hash functions from the distilled data set. Extensive experimental results on three widely used benchmark datasets show that the proposed DistillHash consistently accomplishes the state-of-the-art search performance.
Shared Predictive Cross-Modal Deep Quantization
Apr 16, 2019


With explosive growth of data volume and ever-increasing diversity of data modalities, cross-modal similarity search, which conducts nearest neighbor search across different modalities, has been attracting increasing interest. This paper presents a deep compact code learning solution for efficient cross-modal similarity search. Many recent studies have proven that quantization-based approaches perform generally better than hashing-based approaches on single-modal similarity search. In this paper, we propose a deep quantization approach, which is among the early attempts of leveraging deep neural networks into quantization-based cross-modal similarity search. Our approach, dubbed shared predictive deep quantization (SPDQ), explicitly formulates a shared subspace across different modalities and two private subspaces for individual modalities, and representations in the shared subspace and the private subspaces are learned simultaneously by embedding them to a reproducing kernel Hilbert space, where the mean embedding of different modality distributions can be explicitly compared. In addition, in the shared subspace, a quantizer is learned to produce the semantics preserving compact codes with the help of label alignment. Thanks to this novel network architecture in cooperation with supervised quantization training, SPDQ can preserve intramodal and intermodal similarities as much as possible and greatly reduce quantization error. Experiments on two popular benchmarks corroborate that our approach outperforms state-of-the-art methods.