 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Instance-dependent Label-noise Transition Matrix using DNNs
Paper and Code
May 27, 2021
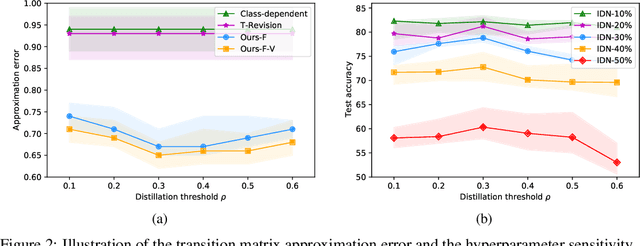


In label-noise learning, estimating the transition matrix is a hot topic as the matrix plays an important role in building statistically consistent classifiers. Traditionally, the transition from clean distribution to noisy distribution (i.e., clean label transition matrix) has been widely exploited to learn a clean label classifier by employing the noisy data. Motivated by that classifiers mostly output Bayes optimal labels for prediction, in this paper, we study to directly model the transition from Bayes optimal distribution to noisy distribution (i.e., Bayes label transition matrix) and learn a Bayes optimal label classifier. Note that given only noisy data, it is ill-posed to estimate either the clean label transition matrix or the Bayes label transition matrix. But favorably, Bayes optimal labels are less uncertain compared with the clean labels, i.e., the class posteriors of Bayes optimal labels are one-hot vectors while those of clean labels are not. This enables two advantages to estimate the Bayes label transition matrix, i.e., (a) we could theoretically recover a set of Bayes optimal labels under mild conditions; (b) the feasible solution space is much smaller. By exploiting the advantages, we estimate the Bayes label transition matrix by employing a deep neural network in a parameterized way, leading to better generalization and superior classification performance.