 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatticeVision: Image to Image Networks for Modeling Non-Stationary Spatial Data
May 14, 2025



In many scientific and industrial applications, we are given a handful of instances (a 'small ensemble') of a spatially distributed quantity (a 'field') but would like to acquire many more. For example, a large ensemble of global temperature sensitivity fields from a climate model can help farmers, insurers, and governments plan appropriately. When acquiring more data is prohibitively expensive -- as is the case with climate models -- statistical emulation offers an efficient alternative for simulating synthetic yet realistic fields. However, parameter inference using maximum likelihood estimation (MLE) is computationally prohibitive, especially for large, non-stationary fields. Thus, many recent works train neural networks to estimate parameters given spatial fields as input, sidestepping MLE completely. In this work we focus on a popular class of parametric, spatially autoregressive (SAR) models. We make a simple yet impactful observation; because the SAR parameters can be arranged on a regular grid, both inputs (spatial fields) and outputs (model parameters) can be viewed as images. Using this insight, we demonstrate that image-to-image (I2I) networks enable faster and more accurate parameter estimation for a class of non-stationary SAR models with unprecedented complexity.
On Logical Extrapolation for Mazes with Recurrent and Implicit Networks
Oct 03, 2024



Recent work has suggested that certain neural network architectures-particularly recurrent neural networks (RNNs) and implicit neural networks (INNs) are capable of logical extrapolation. That is, one may train such a network on easy instances of a specific task and then apply it successfully to more difficult instances of the same task. In this paper, we revisit this idea and show that (i) The capacity for extrapolation is less robust than previously suggested. Specifically, in the context of a maze-solving task, we show that while INNs (and some RNNs) are capable of generalizing to larger maze instances, they fail to generalize along axes of difficulty other than maze size. (ii) Models that are explicitly trained to converge to a fixed point (e.g. the INN we test) are likely to do so when extrapolating, while models that are not (e.g. the RNN we test) may exhibit more exotic limiting behaviour such as limit cycles, even when they correctly solve the problem. Our results suggest that (i) further study into why such networks extrapolate easily along certain axes of difficulty yet struggle with others is necessary, and (ii) analyzing the dynamics of extrapolation may yield insights into designing more efficient and interpretable logical extrapolators.
Fermat Distances: Metric Approximation, Spectral Convergence, and Clustering Algorithms
Jul 07, 2023



We analyze the convergence properties of Fermat distances, a family of density-driven metrics defined on Riemannian manifolds with an associated probability measure. Fermat distances may be defined either on discrete samples from the underlying measure, in which case they are random, or in the continuum setting, in which they are induced by geodesics under a density-distorted Riemannian metric. We prove that discrete, sample-based Fermat distances converge to their continuum analogues in small neighborhoods with a precise rate that depends on the intrinsic dimensionality of the data and the parameter governing the extent of density weighting in Fermat distances. This is done by leveraging novel geometric and statistical arguments in percolation theory that allow for non-uniform densities and curved domains. Our results are then used to prove that discrete graph Laplacians based on discrete, sample-driven Fermat distances converge to corresponding continuum operators. In particular, we show the discrete eigenvalues and eigenvectors converge to their continuum analogues at a dimension-dependent rate, which allows us to interpret the efficacy of discrete spectral clustering using Fermat distances in terms of the resulting continuum limit. The perspective afforded by our discrete-to-continuum Fermat distance analysis leads to new clustering algorithms for data and related insights into efficient computations associated to density-driven spectral clustering. Our theoretical analysis is supported with numerical simulations and experiments on synthetic and real image data.
It begins with a boundary: A geometric view on probabilistically robust learning
May 30, 2023Although deep neural networks have achieved super-human performance on many classification tasks, they often exhibit a worrying lack of robustness towards adversarially generated examples. Thus, considerable effort has been invested into reformulating Empirical Risk Minimization (ERM) into an adversarially robust framework. Recently, attention has shifted towards approaches which interpolate between the robustness offered by adversarial training and the higher clean accuracy and faster training times of ERM. In this paper, we take a fresh and geometric view on one such method -- Probabilistically Robust Learning (PRL) (Robey et al., ICML, 2022). We propose a geometric framework for understanding PRL, which allows us to identify a subtle flaw in its original formulation and to introduce a family of probabilistic nonlocal perimeter functionals to address this. We prove existence of solutions using novel relaxation methods and study properties as well as local limits of the introduced perimeters.
Faster Predict-and-Optimize with Three-Operator Splitting
Jan 31, 2023


In many practical settings, a combinatorial problem must be repeatedly solved with similar, but distinct parameters w. Yet, w is not directly observed; only contextual data d that correlates with w is available. It is tempting to use a neural network to predict w given d, but training such a model requires reconciling the discrete nature of combinatorial optimization with the gradient-based frameworks used to train neural networks. One approach to overcoming this issue is to consider a continuous relaxation of the combinatorial problem. While existing such approaches have shown to be highly effective on small problems (10-100 variables) they do not scale well to large problems. In this work, we show how recent results in operator splitting can be used to design such a system which is easy to train and scales effortlessly to problems with thousands of variables.
Curvature-Aware Derivative-Free Optimization
Sep 27, 2021

We propose a new line-search method, coined Curvature-Aware Random Search (CARS), for derivative-free optimization. CARS exploits approximate curvature information to estimate the optimal step-size given a search direction. We prove that for strongly convex objective functions, CARS converges linearly if the search direction is drawn from a distribution satisfying very mild conditions. We also explore a variant, CARS-NQ, which uses Numerical Quadrature instead of a Monte Carlo method when approximating curvature along the search direction. We show CARS-NQ is effective on highly non-convex problems of the form $f = f_{\mathrm{cvx}} + f_{\mathrm{osc}}$ where $f_{\mathrm{cvx}}$ is strongly convex and $f_{\mathrm{osc}}$ is rapidly oscillating. Experimental results show that CARS and CARS-NQ match or exceed the state-of-the-arts on benchmark problem sets.
Learn to Predict Equilibria via Fixed Point Networks
Jun 02, 2021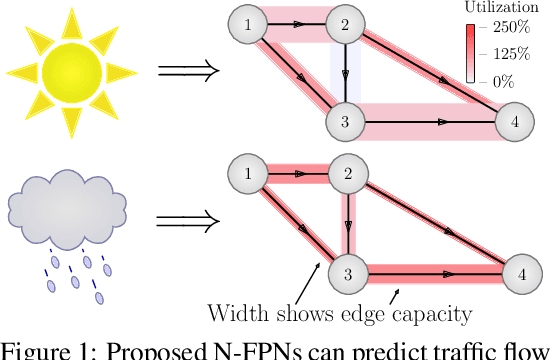

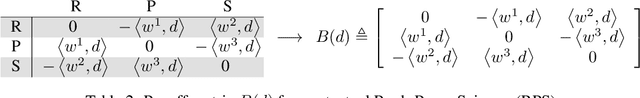
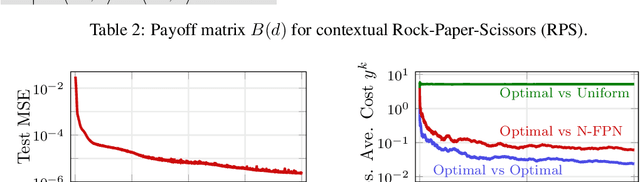
Systems of interacting agents can often be modeled as contextual games, where the context encodes additional information, beyond the control of any agent (e.g. weather for traffic and fiscal policy for market economies). In such systems, the most likely outcome is given by a Nash equilibrium. In many practical settings, only game equilibria are observed, while the optimal parameters for a game model are unknown. This work introduces Nash Fixed Point Networks (N-FPNs), a class of implicit-depth neural networks that output Nash equilibria of contextual games. The N-FPN architecture fuses data-driven modeling with provided constraints. Given equilibrium observations of a contextual game, N-FPN parameters are learnt to predict equilibria outcomes given only the context. We present an end-to-end training scheme for N-FPNs that is simple and memory efficient to implement with existing autodifferentiation tools. N-FPNs also exploit a novel constraint decoupling scheme to avoid costly projections. Provided numerical examples show the efficacy of N-FPNs on atomic and non-atomic games (e.g. traffic routing).
Fixed Point Networks: Implicit Depth Models with Jacobian-Free Backprop
Mar 23, 2021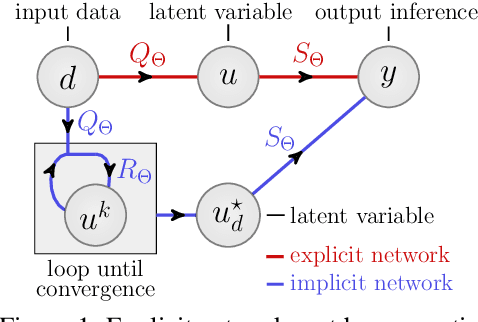
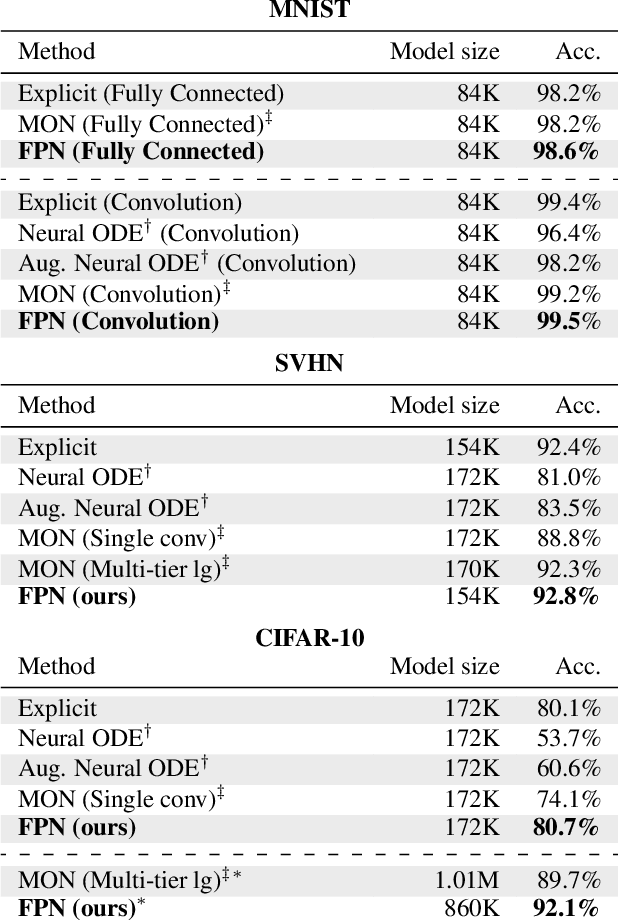
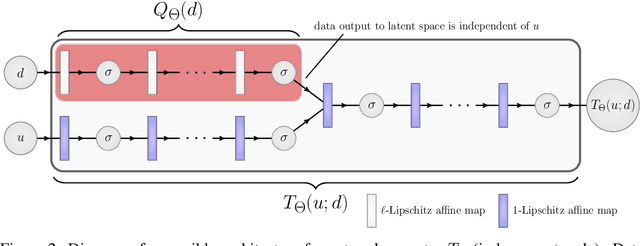
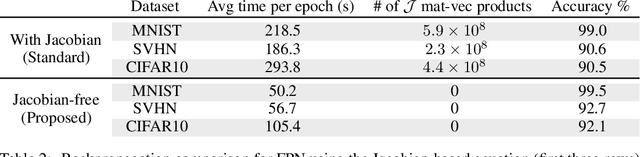
A growing trend in deep learning replaces fixed depth models by approximations of the limit as network depth approaches infinity. This approach uses a portion of network weights to prescribe behavior by defining a limit condition. This makes network depth implicit, varying based on the provided data and an error tolerance. Moreover, existing implicit models can be implemented and trained with fixed memory costs in exchange for additional computational costs. In particular, backpropagation through implicit depth models requires solving a Jacobian-based equation arising from the implicit function theorem. We propose fixed point networks (FPNs), a simple setup for implicit depth learning that guarantees convergence of forward propagation to a unique limit defined by network weights and input data. Our key contribution is to provide a new Jacobian-free backpropagation (JFB) scheme that circumvents the need to solve Jacobian-based equations while maintaining fixed memory costs. This makes FPNs much cheaper to train and easy to implement. Our numerical examples yield state of the art classification results for implicit depth models and outperform corresponding explicit models.
A Zeroth-Order Block Coordinate Descent Algorithm for Huge-Scale Black-Box Optimization
Feb 21, 2021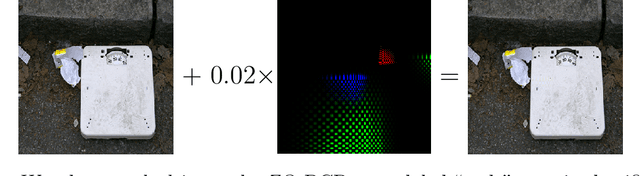
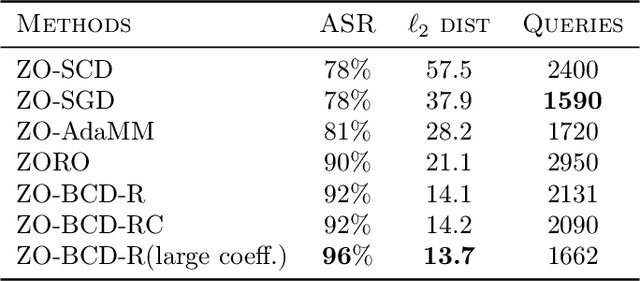
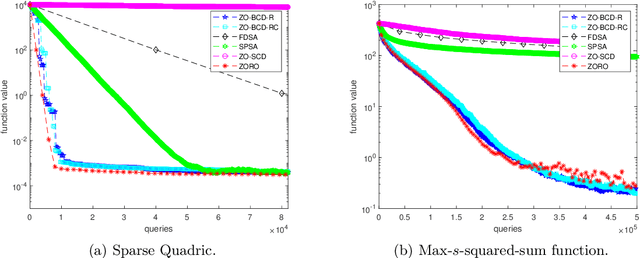
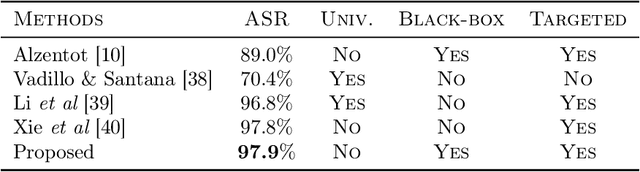
We consider the zeroth-order optimization problem in the huge-scale setting, where the dimension of the problem is so large that performing even basic vector operations on the decision variables is infeasible. In this paper, we propose a novel algorithm, coined ZO-BCD, that exhibits favorable overall query complexity and has a much smaller per-iteration computational complexity. In addition, we discuss how the memory footprint of ZO-BCD can be reduced even further by the clever use of circulant measurement matrices. As an application of our new method, we propose the idea of crafting adversarial attacks on neural network based classifiers in a wavelet domain, which can result in problem dimensions of over 1.7 million. In particular, we show that crafting adversarial examples to audio classifiers in a wavelet domain can achieve the state-of-the-art attack success rate of 97.9%.
Balancing Geometry and Density: Path Distances on High-Dimensional Data
Dec 17, 2020
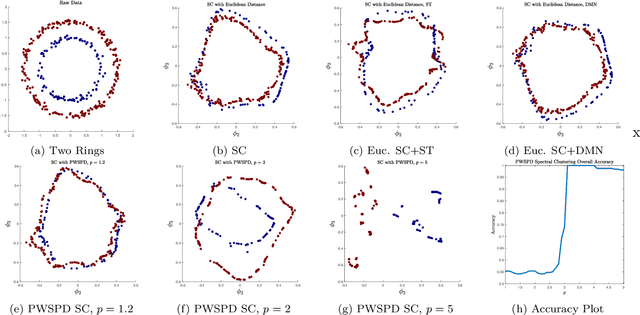
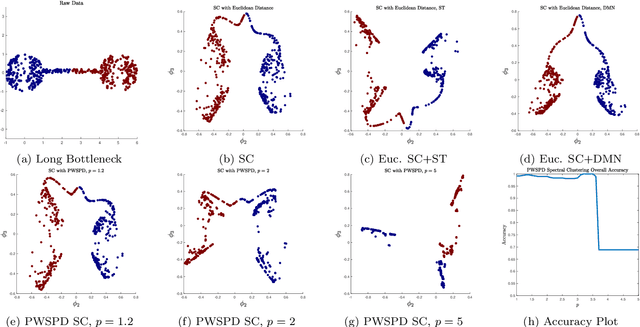
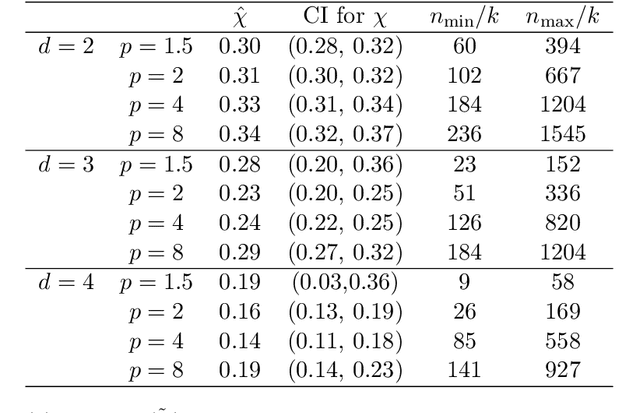
New geometric and computational analyses of power-weighted shortest-path distances (PWSPDs) are presented. By illuminating the way these metrics balance density and geometry in the underlying data, we clarify their key parameters and discuss how they may be chosen in practice. Comparisons are made with related data-driven metrics, which illustrate the broader role of density in kernel-based unsupervised and semi-supervised machine learning. Computationally, we relate PWSPDs on complete weighted graphs to their analogues on weighted nearest neighbor graphs, providing high probability guarantees on their equivalence that are near-optimal. Connections with percolation theory are developed to establish estimates on the bias and variance of PWSPDs in the finite sample setting. The theoretical results are bolstered by illustrative experiments, demonstrating the versatility of PWSPDs for a wide range of data settings. Throughout the paper, our results require only that the underlying data is sampled from a low-dimensional manifold, and depend crucially on the intrinsic dimension of this manifold, rather than its ambient dimension.