 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODE-CNN: Omnidirectional Depth Extension Networks
Jul 03, 2020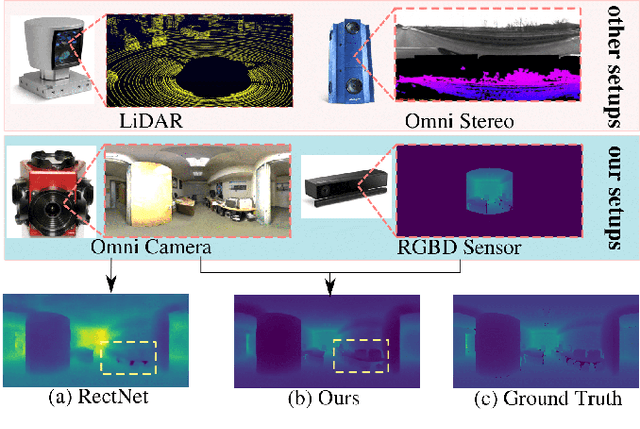
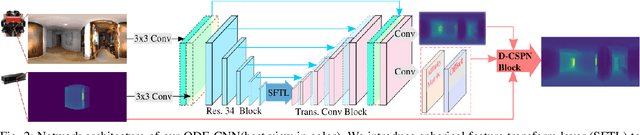
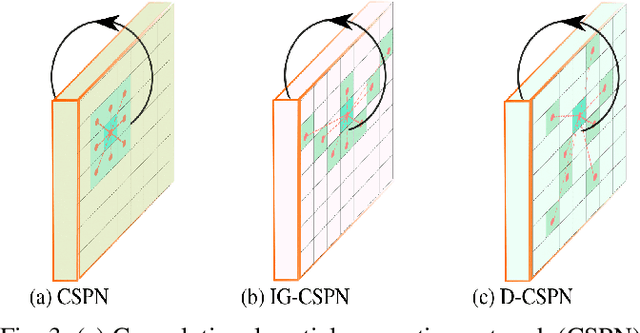

Omnidirectional 360{\deg} camera proliferates rapidly for autonomous robots since it significantly enhances the perception ability by widening the field of view(FoV). However, corresponding 360{\deg} depth sensors, which are also critical for the perception system, are still difficult or expensive to have. In this paper, we propose a low-cost 3D sensing system that combines an omnidirectional camera with a calibrated projective depth camera, where the depth from the limited FoV can be automatically extended to the rest of the recorded omnidirectional image. To accurately recover the missing depths, we design an omnidirectional depth extension convolutional neural network(ODE-CNN), in which a spherical feature transform layer(SFTL) is embedded at the end of feature encoding layers, and a deformable convolutional spatial propagation network(D-CSPN) is appended at the end of feature decoding layers. The former resamples the neighborhood of each pixel in the omnidirectional coordination to the projective coordination, which reduces the difficulty of feature learning, and the later automatically finds a proper context to well align the structures in the estimated depths via CNN w.r.t. the reference image, which significantly improves the visual quality. Finally, we demonstrate the effectiveness of proposed ODE-CNN over the popular 360D dataset and show that ODE-CNN significantly outperforms (relatively 33% reduction in-depth error) other state-of-the-art (SoTA) methods.
LiDAR-based Online 3D Video Object Detection with Graph-based Message Passing and Spatiotemporal Transformer Attention
Apr 03, 2020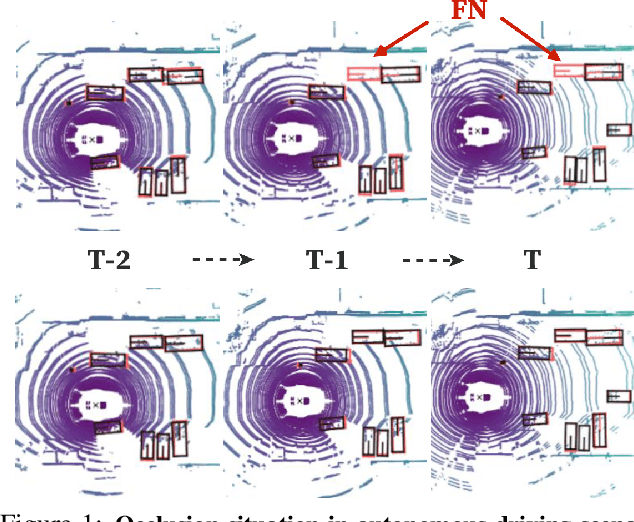
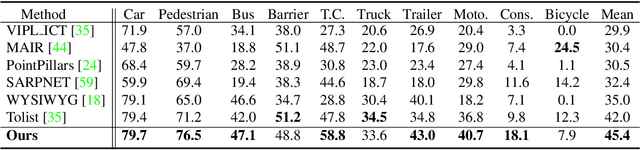
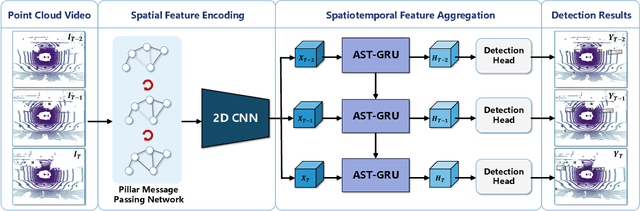
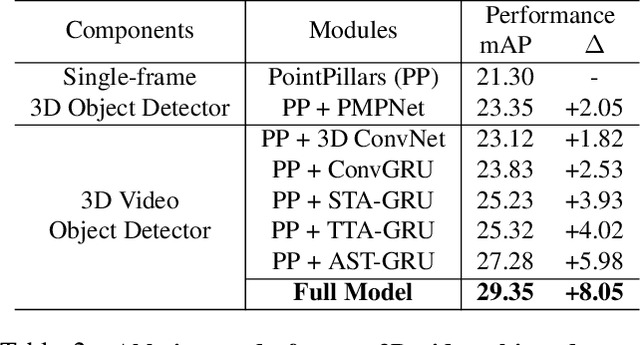
Existing LiDAR-based 3D object detectors usually focus on the single-frame detection, while ignoring the spatiotemporal information in consecutive point cloud frames. In this paper, we propose an end-to-end online 3D video object detector that operates on point cloud sequences. The proposed model comprises a spatial feature encoding component and a spatiotemporal feature aggregation component. In the former component, a novel Pillar Message Passing Network (PMPNet) is proposed to encode each discrete point cloud frame. It adaptively collects information for a pillar node from its neighbors by iterative message passing, which effectively enlarges the receptive field of the pillar feature. In the latter component, we propose an Attentive Spatiotemporal Transformer GRU (AST-GRU) to aggregate the spatiotemporal information, which enhances the conventional ConvGRU with an attentive memory gating mechanism. AST-GRU contains a Spatial Transformer Attention (STA) module and a Temporal Transformer Attention (TTA) module, which can emphasize the foreground objects and align the dynamic objects, respectively. Experimental results demonstrate that the proposed 3D video object detector achieves state-of-the-art performance on the large-scale nuScenes benchmark.
AutoRemover: Automatic Object Removal for Autonomous Driving Videos
Nov 28, 2019
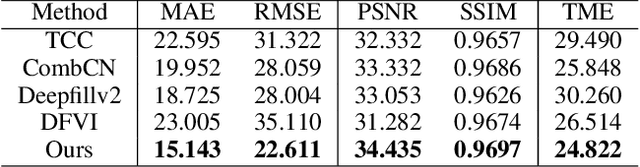
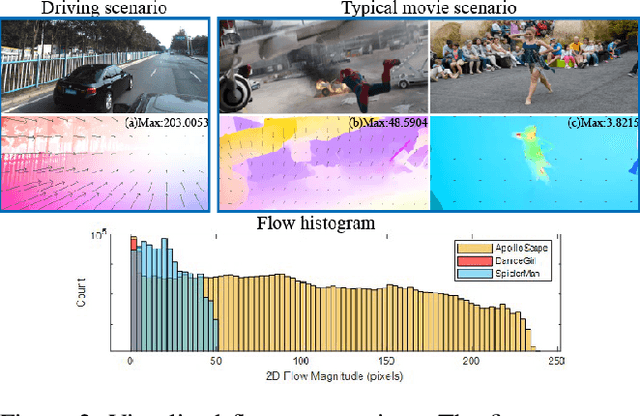
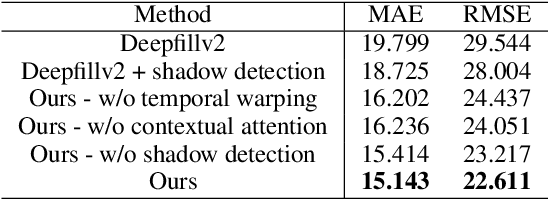
Motivated by the need for photo-realistic simulation in autonomous driving, in this paper we present a video inpainting algorithm \emph{AutoRemover}, designed specifically for generating street-view videos without any moving objects. In our setup we have two challenges: the first is the shadow, shadows are usually unlabeled but tightly coupled with the moving objects. The second is the large ego-motion in the videos. To deal with shadows, we build up an autonomous driving shadow dataset and design a deep neural network to detect shadows automatically. To deal with large ego-motion, we take advantage of the multi-source data, in particular the 3D data, in autonomous driving. More specifically, the geometric relationship between frames is incorporated into an inpainting deep neural network to produce high-quality structurally consistent video output. Experiments show that our method outperforms other state-of-the-art (SOTA) object removal algorithms, reducing the RMSE by over $19\%$.
CSPN++: Learning Context and Resource Aware Convolutional Spatial Propagation Networks for Depth Completion
Nov 22, 2019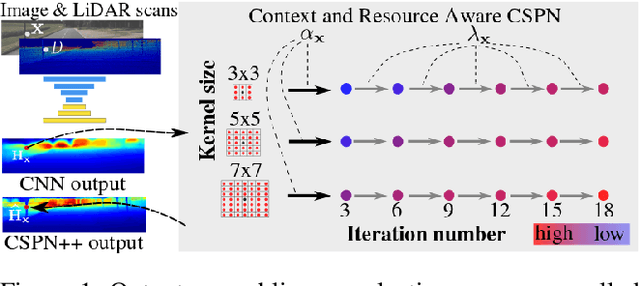

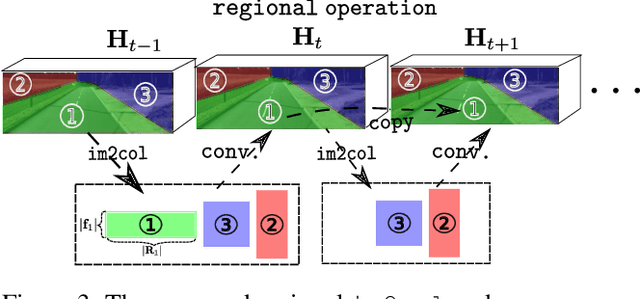
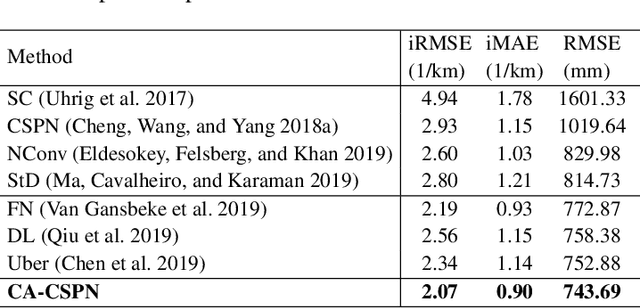
Depth Completion deals with the problem of converting a sparse depth map to a dense one, given the corresponding color image. Convolutional spatial propagation network (CSPN) is one of the state-of-the-art (SoTA) methods of depth completion, which recovers structural details of the scene. In this paper, we propose CSPN++, which further improves its effectiveness and efficiency by learning adaptive convolutional kernel sizes and the number of iterations for the propagation, thus the context and computational resources needed at each pixel could be dynamically assigned upon requests. Specifically, we formulate the learning of the two hyper-parameters as an architecture selection problem where various configurations of kernel sizes and numbers of iterations are first defined, and then a set of soft weighting parameters are trained to either properly assemble or select from the pre-defined configurations at each pixel. In our experiments, we find weighted assembling can lead to significant accuracy improvements, which we referred to as "context-aware CSPN", while weighted selection, "resource-aware CSPN" can reduce the computational resource significantly with similar or better accuracy. Besides, the resource needed for CSPN++ can be adjusted w.r.t. the computational budget automatically. Finally, to avoid the side effects of noise or inaccurate sparse depths, we embed a gated network inside CSPN++, which further improves the performance. We demonstrate the effectiveness of CSPN++on the KITTI depth completion benchmark, where it significantly improves over CSPN and other SoTA methods.
IoU Loss for 2D/3D Object Detection
Aug 11, 2019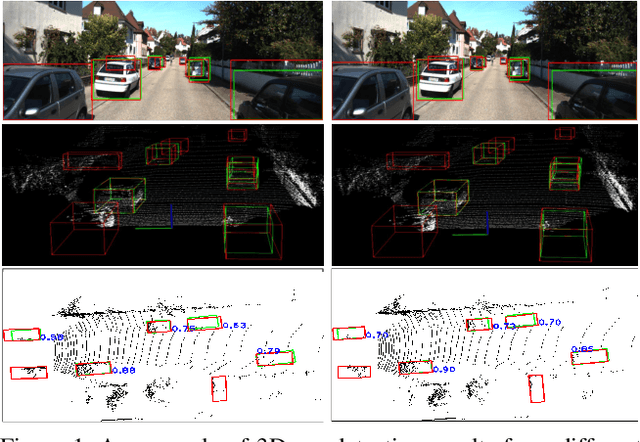


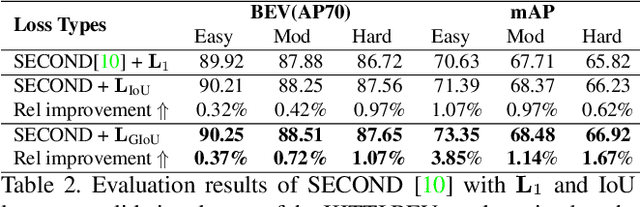
In 2D/3D object detection task, Intersection-over-Union (IoU) has been widely employed as an evaluation metric to evaluate the performance of different detectors in the testing stage. However, during the training stage, the common distance loss (\eg, $L_1$ or $L_2$) is often adopted as the loss function to minimize the discrepancy between the predicted and ground truth Bounding Box (Bbox). To eliminate the performance gap between training and testing, the IoU loss has been introduced for 2D object detection in \cite{yu2016unitbox} and \cite{rezatofighi2019generalized}. Unfortunately, all these approaches only work for axis-aligned 2D Bboxes, which cannot be applied for more general object detection task with rotated Bboxes. To resolve this issue, we investigate the IoU computation for two rotated Bboxes first and then implement a unified framework, IoU loss layer for both 2D and 3D object detection tasks. By integrating the implemented IoU loss into several state-of-the-art 3D object detectors, consistent improvements have been achieved for both bird-eye-view 2D detection and point cloud 3D detection on the public KITTI benchmark.
ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving
Nov 30, 2018

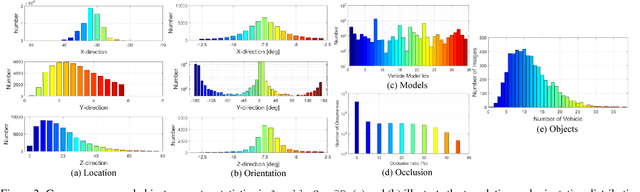
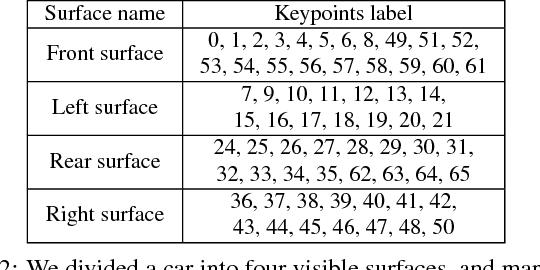
Autonomous driving has attracted remarkable attention from both industry and academia. An important task is to estimate 3D properties(e.g.translation, rotation and shape) of a moving or parked vehicle on the road. This task, while critical, is still under-researched in the computer vision community - partially owing to the lack of large scale and fully-annotated 3D car database suitable for autonomous driving research. In this paper, we contribute the first large-scale database suitable for 3D car instance understanding - ApolloCar3D. The dataset contains 5,277 driving images and over 60K car instances, where each car is fitted with an industry-grade 3D CAD model with absolute model size and semantically labelled keypoints. This dataset is above 20 times larger than PASCAL3D+ and KITTI, the current state-of-the-art. To enable efficient labelling in 3D, we build a pipeline by considering 2D-3D keypoint correspondences for a single instance and 3D relationship among multiple instances. Equipped with such dataset, we build various baseline algorithms with the state-of-the-art deep convolutional neural networks. Specifically, we first segment each car with a pre-trained Mask R-CNN, and then regress towards its 3D pose and shape based on a deformable 3D car model with or without using semantic keypoints. We show that using keypoints significantly improves fitting performance. Finally, we develop a new 3D metric jointly considering 3D pose and 3D shape, allowing for comprehensive evaluation and ablation study. By comparing with human performance we suggest several future directions for further improvements.