 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatching MRI outliers: unsupervised detection and localization of MRI artefacts and clinical anomalies using deep learning
May 23, 2026Artificial intelligence is increasingly integrated into radiotherapy workflows, yet such pipelines remain vulnerable to out-of-distribution image data that may introduce unexpected behavior in clinical tasks. Deep learning-based anomaly detection for pelvic magnetic resonance imaging (MRI) remains largely unexplored, and transparent evaluation of its feasibility for full automation is limited. We developed and evaluated a fully automated, unsupervised anomaly-detection framework for pelvic and brain MRI. A two-stage framework was trained on reference images from public datasets: LUND-PROBE for pelvic MRI, and IXI, fastMRI, and fastMRI+ for brain MRI. In the first stage, MRI slices were compressed into discrete tokens; in the second, the distribution of normal tokens was modeled. Anomaly evidence was estimated by combining perceptual image differences with token-surprisal scores based on negative log-likelihood. Automated detection was evaluated on pelvic MRI with synthetic global and real clinical anomalies, and on brain MRI with clinically annotated fastMRI+ abnormalities. Sensitivity, specificity, area under the receiver operating characteristic curve (AUC), and false-positive behavior in held-out normal cases were assessed. The framework achieved robust detection across hidden evaluation cohorts, with AUCs of 0.97 (95% CI, 0.95-0.98) and 0.81 (95% CI, 0.74-0.87) for pelvic and brain MRI, respectively. Heatmap analysis showed strong spatial agreement between detected anomalies and ground-truth locations, supporting localization accuracy and interpretability. These results support the potential of unsupervised anomaly detection as an automated MRI quality-control layer for radiotherapy workflows, with transparent visualization of image regions likely to compromise downstream AI-based tasks.
Automated Real-time Assessment of Intracranial Hemorrhage Detection AI Using an Ensembled Monitoring Model (EMM)
May 16, 2025Artificial intelligence (AI) tools for radiology are commonly unmonitored once deployed. The lack of real-time case-by-case assessments of AI prediction confidence requires users to independently distinguish between trustworthy and unreliable AI predictions, which increases cognitive burden, reduces productivity, and potentially leads to misdiagnoses. To address these challenges, we introduce Ensembled Monitoring Model (EMM), a framework inspired by clinical consensus practices using multiple expert reviews. Designed specifically for black-box commercial AI products, EMM operates independently without requiring access to internal AI components or intermediate outputs, while still providing robust confidence measurements. Using intracranial hemorrhage detection as our test case on a large, diverse dataset of 2919 studies, we demonstrate that EMM successfully categorizes confidence in the AI-generated prediction, suggesting different actions and helping improve the overall performance of AI tools to ultimately reduce cognitive burden. Importantly, we provide key technical considerations and best practices for successfully translating EMM into clinical settings.
Spectral Graph Sample Weighting for Interpretable Sub-cohort Analysis in Predictive Models for Neuroimaging
Oct 01, 2024Recent advancements in medicine have confirmed that brain disorders often comprise multiple subtypes of mechanisms, developmental trajectories, or severity levels. Such heterogeneity is often associated with demographic aspects (e.g., sex) or disease-related contributors (e.g., genetics). Thus, the predictive power of machine learning models used for symptom prediction varies across subjects based on such factors. To model this heterogeneity, one can assign each training sample a factor-dependent weight, which modulates the subject's contribution to the overall objective loss function. To this end, we propose to model the subject weights as a linear combination of the eigenbases of a spectral population graph that captures the similarity of factors across subjects. In doing so, the learned weights smoothly vary across the graph, highlighting sub-cohorts with high and low predictability. Our proposed sample weighting scheme is evaluated on two tasks. First, we predict initiation of heavy alcohol drinking in young adulthood from imaging and neuropsychological measures from the National Consortium on Alcohol and NeuroDevelopment in Adolescence (NCANDA). Next, we detect Dementia vs. Mild Cognitive Impairment (MCI) using imaging and demographic measurements in subjects from the Alzheimer's Disease Neuroimaging Initiative (ADNI). Compared to existing sample weighting schemes, our sample weights improve interpretability and highlight sub-cohorts with distinct characteristics and varying model accuracy.
Unlocking Robust Segmentation Across All Age Groups via Continual Learning
Apr 19, 2024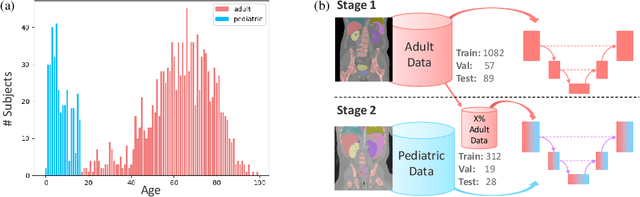

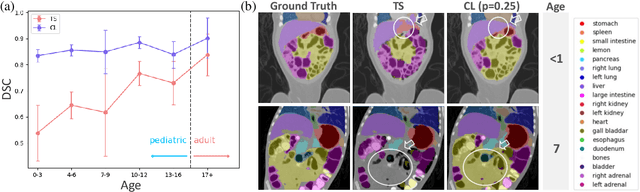
Most deep learning models in medical imaging are trained on adult data with unclear performance on pediatric images. In this work, we aim to address this challenge in the context of automated anatomy segmentation in whole-body Computed Tomography (CT). We evaluate the performance of CT organ segmentation algorithms trained on adult data when applied to pediatric CT volumes and identify substantial age-dependent underperformance. We subsequently propose and evaluate strategies, including data augmentation and continual learning approaches, to achieve good segmentation accuracy across all age groups. Our best-performing model, trained using continual learning, achieves high segmentation accuracy on both adult and pediatric data (Dice scores of 0.90 and 0.84 respectively).
Jointly Exploring Client Drift and Catastrophic Forgetting in Dynamic Learning
Sep 01, 2023



Federated and Continual Learning have emerged as potential paradigms for the robust and privacy-aware use of Deep Learning in dynamic environments. However, Client Drift and Catastrophic Forgetting are fundamental obstacles to guaranteeing consistent performance. Existing work only addresses these problems separately, which neglects the fact that the root cause behind both forms of performance deterioration is connected. We propose a unified analysis framework for building a controlled test environment for Client Drift -- by perturbing a defined ratio of clients -- and Catastrophic Forgetting -- by shifting all clients with a particular strength. Our framework further leverages this new combined analysis by generating a 3D landscape of the combined performance impact from both. We demonstrate that the performance drop through Client Drift, caused by a certain share of shifted clients, is correlated to the drop from Catastrophic Forgetting resulting from a corresponding shift strength. Correlation tests between both problems for Computer Vision (CelebA) and Medical Imaging (PESO) support this new perspective, with an average Pearson rank correlation coefficient of over 0.94. Our framework's novel ability of combined spatio-temporal shift analysis allows us to investigate how both forms of distribution shift behave in mixed scenarios, opening a new pathway for better generalization. We show that a combination of moderate Client Drift and Catastrophic Forgetting can even improve the performance of the resulting model (causing a "Generalization Bump") compared to when only one of the shifts occurs individually. We apply a simple and commonly used method from Continual Learning in the federated setting and observe this phenomenon to be reoccurring, leveraging the ability of our framework to analyze existing and novel methods for Federated and Continual Learning.
Distance-based detection of out-of-distribution silent failures for Covid-19 lung lesion segmentation
Aug 05, 2022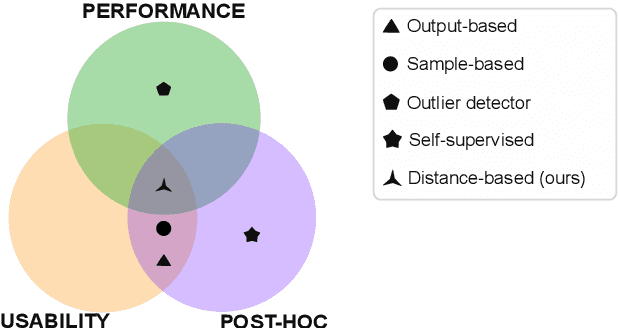

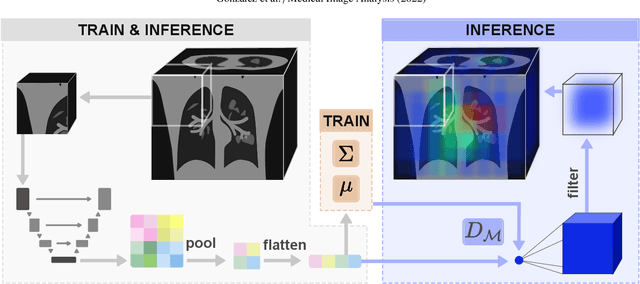
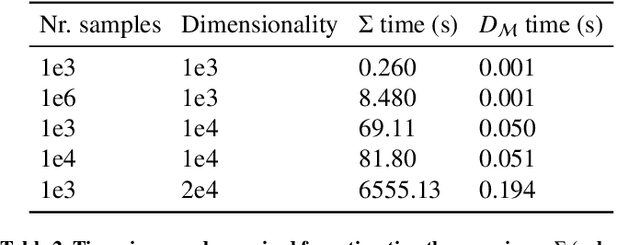
Automatic segmentation of ground glass opacities and consolidations in chest computer tomography (CT) scans can potentially ease the burden of radiologists during times of high resource utilisation. However, deep learning models are not trusted in the clinical routine due to failing silently on out-of-distribution (OOD) data. We propose a lightweight OOD detection method that leverages the Mahalanobis distance in the feature space and seamlessly integrates into state-of-the-art segmentation pipelines. The simple approach can even augment pre-trained models with clinically relevant uncertainty quantification. We validate our method across four chest CT distribution shifts and two magnetic resonance imaging applications, namely segmentation of the hippocampus and the prostate. Our results show that the proposed method effectively detects far- and near-OOD samples across all explored scenarios.
Task-agnostic Continual Hippocampus Segmentation for Smooth Population Shifts
Aug 05, 2022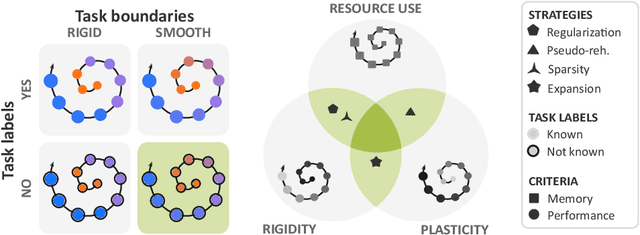
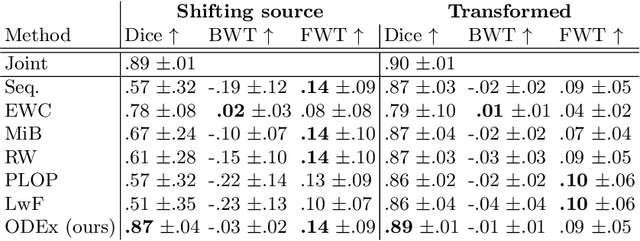


Most continual learning methods are validated in settings where task boundaries are clearly defined and task identity information is available during training and testing. We explore how such methods perform in a task-agnostic setting that more closely resembles dynamic clinical environments with gradual population shifts. We propose ODEx, a holistic solution that combines out-of-distribution detection with continual learning techniques. Validation on two scenarios of hippocampus segmentation shows that our proposed method reliably maintains performance on earlier tasks without losing plasticity.
Quality monitoring of federated Covid-19 lesion segmentation
Dec 16, 2021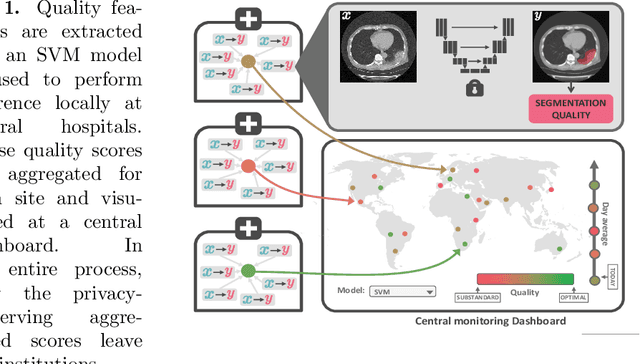
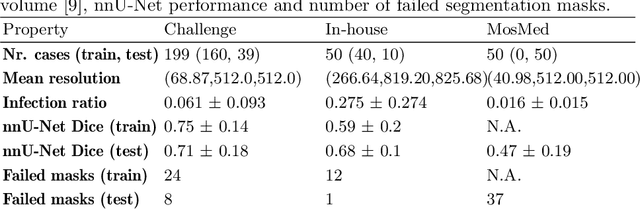
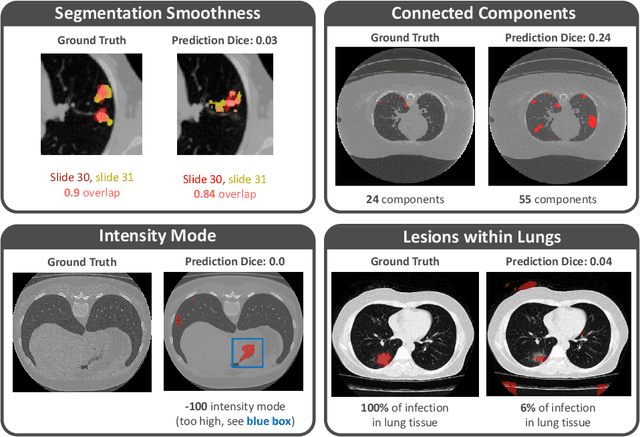
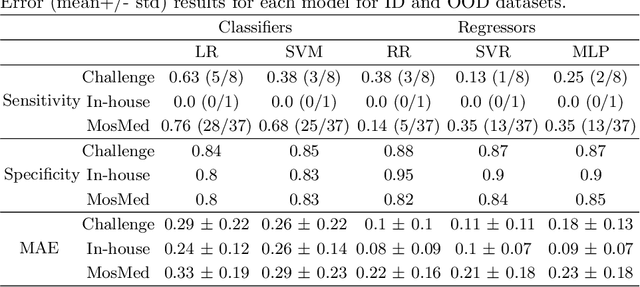
Federated Learning is the most promising way to train robust Deep Learning models for the segmentation of Covid-19-related findings in chest CTs. By learning in a decentralized fashion, heterogeneous data can be leveraged from a variety of sources and acquisition protocols whilst ensuring patient privacy. It is, however, crucial to continuously monitor the performance of the model. Yet when it comes to the segmentation of diffuse lung lesions, a quick visual inspection is not enough to assess the quality, and thorough monitoring of all network outputs by expert radiologists is not feasible. In this work, we present an array of lightweight metrics that can be calculated locally in each hospital and then aggregated for central monitoring of a federated system. Our linear model detects over 70% of low-quality segmentations on an out-of-distribution dataset and thus reliably signals a decline in model performance.
How Reliable Are Out-of-Distribution Generalization Methods for Medical Image Segmentation?
Sep 03, 2021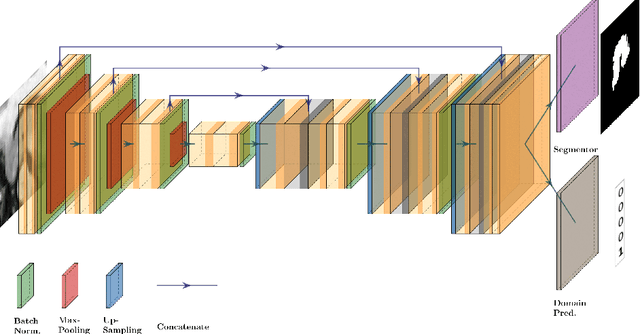

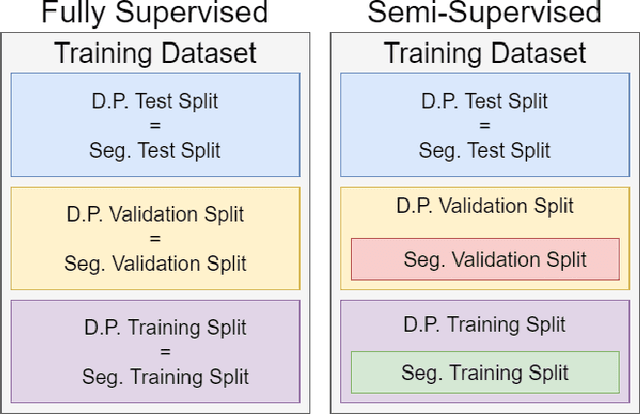

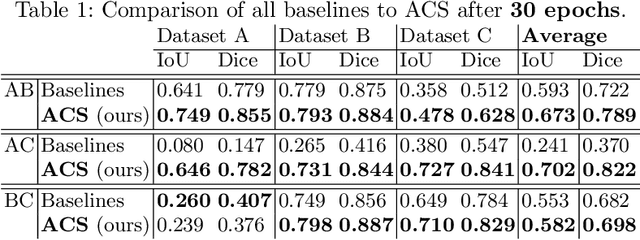
The recent achievements of Deep Learning rely on the test data being similar in distribution to the training data. In an ideal case, Deep Learning models would achieve Out-of-Distribution (OoD) Generalization, i.e. reliably make predictions on out-of-distribution data. Yet in practice, models usually fail to generalize well when facing a shift in distribution. Several methods were thereby designed to improve the robustness of the features learned by a model through Regularization- or Domain-Prediction-based schemes. Segmenting medical images such as MRIs of the hippocampus is essential for the diagnosis and treatment of neuropsychiatric disorders. But these brain images often suffer from distribution shift due to the patient's age and various pathologies affecting the shape of the organ. In this work, we evaluate OoD Generalization solutions for the problem of hippocampus segmentation in MR data using both fully- and semi-supervised training. We find that no method performs reliably in all experiments. Only the V-REx loss stands out as it remains easy to tune, while it outperforms a standard U-Net in most cases.
Adversarial Continual Learning for Multi-Domain Hippocampal Segmentation
Jul 25, 2021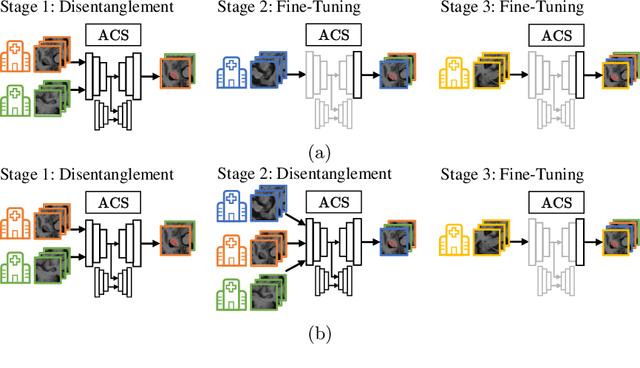
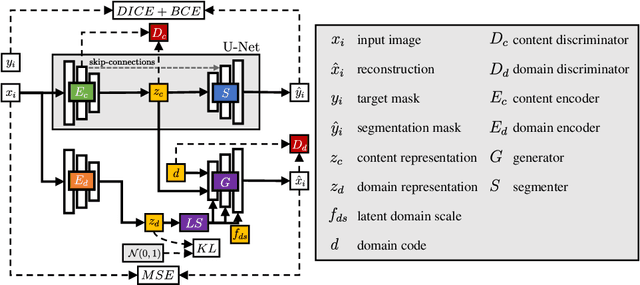
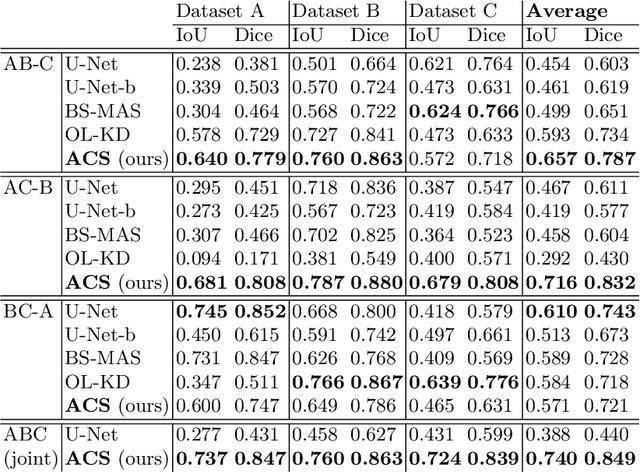
Deep learning for medical imaging suffers from temporal and privacy-related restrictions on data availability. To still obtain viable models, continual learning aims to train in sequential order, as and when data is available. The main challenge that continual learning methods face is to prevent catastrophic forgetting, i.e., a decrease in performance on the data encountered earlier. This issue makes continuous training of segmentation models for medical applications extremely difficult. Yet, often, data from at least two different domains is available which we can exploit to train the model in a way that it disregards domain-specific information. We propose an architecture that leverages the simultaneous availability of two or more datasets to learn a disentanglement between the content and domain in an adversarial fashion. The domain-invariant content representation then lays the base for continual semantic segmentation. Our approach takes inspiration from domain adaptation and combines it with continual learning for hippocampal segmentation in brain MRI. We showcase that our method reduces catastrophic forgetting and outperforms state-of-the-art continual learning methods.