 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA functional approach for curve alignment and shape analysis
Mar 07, 2025


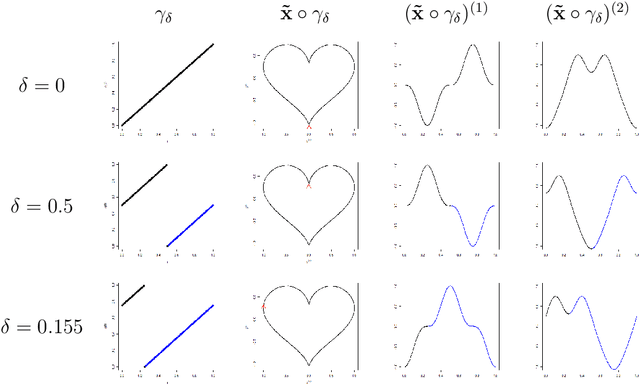
The shape $\tilde{\mathbf{X}}$ of a random planar curve $\mathbf{X}$ is what remains after removing deformation effects such as scaling, rotation, translation, and parametrization. Previous studies in statistical shape analysis have focused on analyzing $\tilde{\bf X}$ through discrete observations of the curve ${\bf X}$. While this approach has some computational advantages, it overlooks the continuous nature of both ${\bf X}$ and its shape $\tilde{\bf X}$. It also ignores potential dependencies among the deformation variables and their effect on $\tilde{ \bf X}$, which may result in information loss and reduced interpretability. In this paper, we introduce a novel framework for analyzing $\bf X$ in the context of Functional Data Analysis (FDA). Basis expansion techniques are employed to derive analytic solutions for estimating the deformation variables such as rotation and reparametrization, thereby achieving shape alignment. The generative model of $\bf X$ is then investigated using a joint-principal component analysis approach. Numerical experiments on simulated data and the \textit{MPEG-7} database demonstrate that our new approach successfully identifies the deformation parameters and captures the underlying distribution of planar curves in situations where traditional FDA methods fail to do so.
Constructing Ancestral Recombination Graphs through Reinforcement Learning
Jun 17, 2024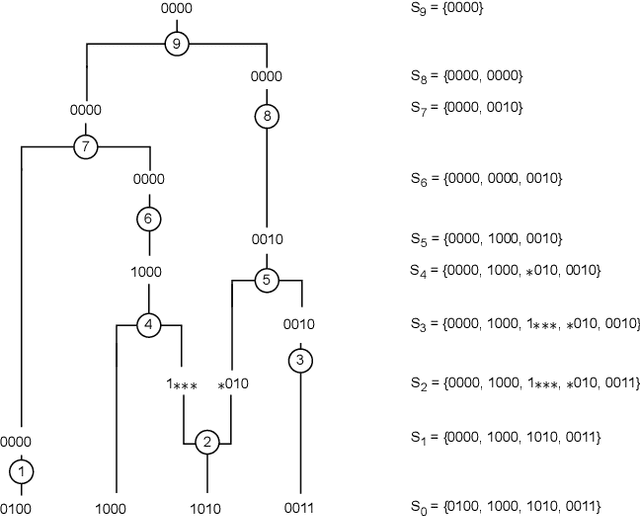

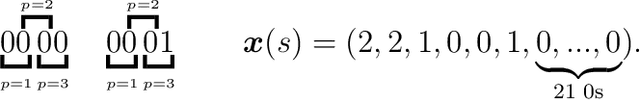
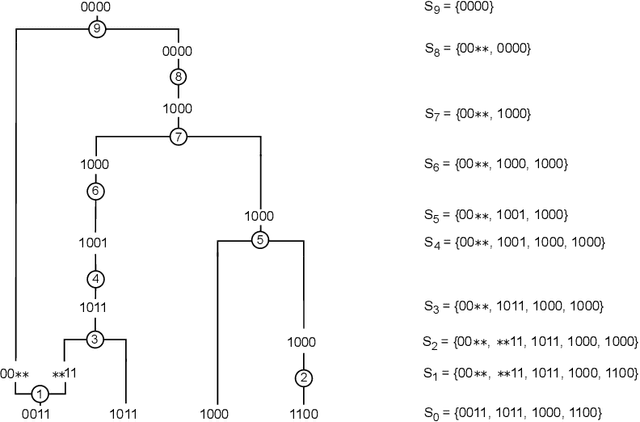
Over the years, many approaches have been proposed to build ancestral recombination graphs (ARGs), graphs used to represent the genetic relationship between individuals. Among these methods, many rely on the assumption that the most likely graph is among the shortest ones. In this paper, we propose a new approach to build short ARGs: Reinforcement Learning (RL). We exploit the similarities between finding the shortest path between a set of genetic sequences and their most recent common ancestor and finding the shortest path between the entrance and exit of a maze, a classic RL problem. In the maze problem, the learner, called the agent, must learn the directions to take in order to escape as quickly as possible, whereas in our problem, the agent must learn the actions to take between coalescence, mutation, and recombination in order to reach the most recent common ancestor as quickly as possible. Our results show that RL can be used to build ARGs as short as those built with a heuristic algorithm optimized to build short ARGs, and sometimes even shorter. Moreover, our method allows to build a distribution of short ARGs for a given sample, and can also generalize learning to new samples not used during the learning process.
Functional Autoencoder for Smoothing and Representation Learning
Jan 17, 2024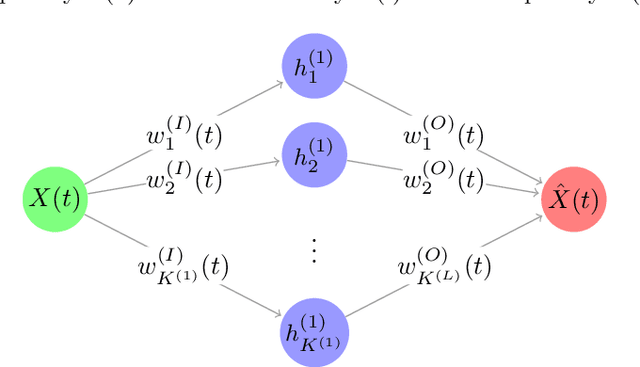
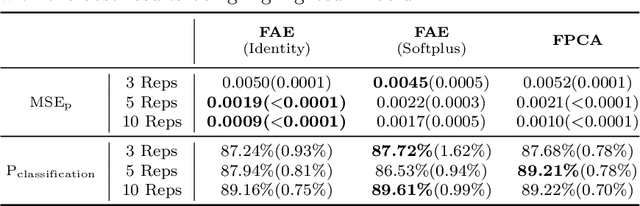
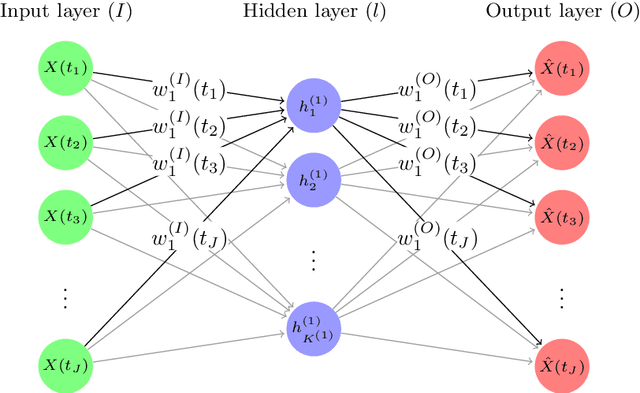
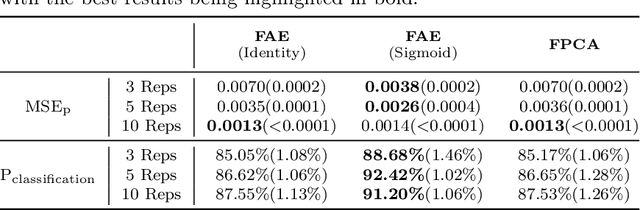
A common pipeline in functional data analysis is to first convert the discretely observed data to smooth functions, and then represent the functions by a finite-dimensional vector of coefficients summarizing the information. Existing methods for data smoothing and dimensional reduction mainly focus on learning the linear mappings from the data space to the representation space, however, learning only the linear representations may not be sufficient. In this study, we propose to learn the nonlinear representations of functional data using neural network autoencoders designed to process data in the form it is usually collected without the need of preprocessing. We design the encoder to employ a projection layer computing the weighted inner product of the functional data and functional weights over the observed timestamp, and the decoder to apply a recovery layer that maps the finite-dimensional vector extracted from the functional data back to functional space using a set of predetermined basis functions. The developed architecture can accommodate both regularly and irregularly spaced data. Our experiments demonstrate that the proposed method outperforms functional principal component analysis in terms of prediction and classification, and maintains superior smoothing ability and better computational efficiency in comparison to the conventional autoencoders under both linear and nonlinear settings.
Neural Networks for Scalar Input and Functional Output
Aug 10, 2022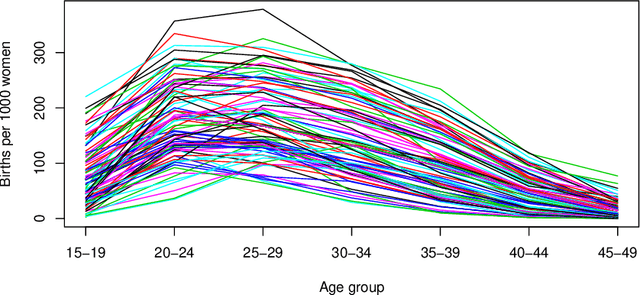
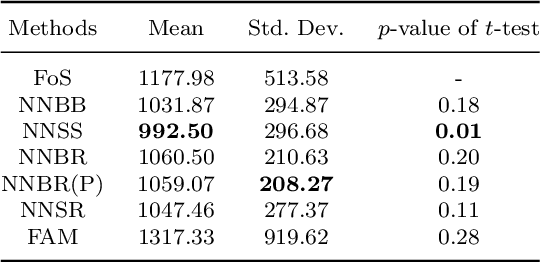
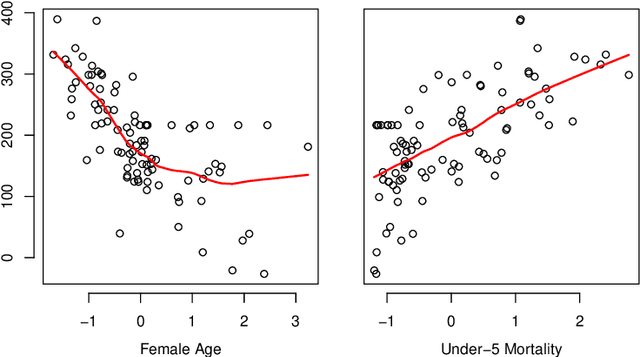
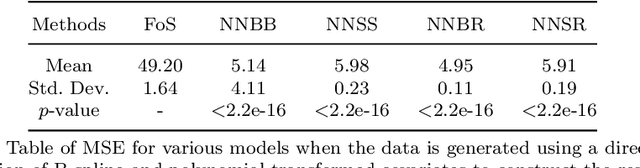
The regression of a functional response on a set of scalar predictors can be a challenging task, especially if there is a large number of predictors, these predictors have interaction effects, or the relationship between those predictors and the response is nonlinear. In this work, we propose a solution to this problem: a feed-forward neural network (NN) designed to predict a functional response using scalar inputs. First, we transform the functional response to a finite-dimension representation and then we construct a NN that outputs this representation. We proposed different objective functions to train the NN. The proposed models are suited for both regularly and irregularly spaced data and also provide multiple ways to apply a roughness penalty to control the smoothness of the predicted curve. The difficulty in implementing both those features lies in the definition of objective functions that can be back-propagated. In our experiments, we demonstrate that our model outperforms the conventional function-on-scalar regression model in multiple scenarios while computationally scaling better with the dimension of the predictors.
Predicting Time-to-conversion for Dementia of Alzheimer's Type using Multi-modal Deep Survival Analysis
May 02, 2022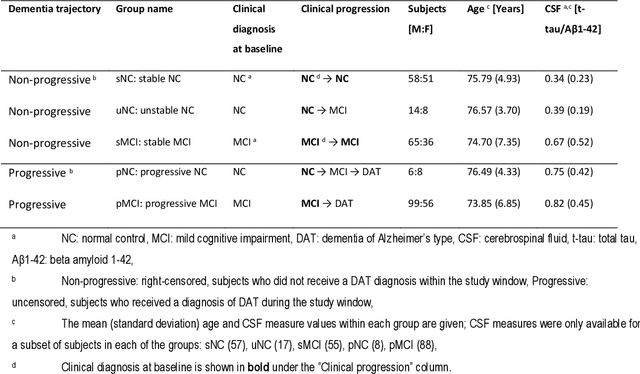

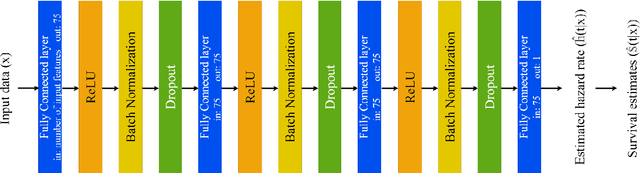
Dementia of Alzheimer's Type (DAT) is a complex disorder influenced by numerous factors, but it is unclear how each factor contributes to disease progression. An in-depth examination of these factors may yield an accurate estimate of time-to-conversion to DAT for patients at various disease stages. We used 401 subjects with 63 features from MRI, genetic, and CDC (Cognitive tests, Demographic, and CSF) data modalities in the Alzheimer's Disease Neuroimaging Initiative (ADNI) database. We used a deep learning-based survival analysis model that extends the classic Cox regression model to predict time-to-conversion to DAT. Our findings showed that genetic features contributed the least to survival analysis, while CDC features contributed the most. Combining MRI and genetic features improved survival prediction over using either modality alone, but adding CDC to any combination of features only worked as well as using only CDC features. Consequently, our study demonstrated that using the current clinical procedure, which includes gathering cognitive test results, can outperform survival analysis results produced using costly genetic or CSF data.
Analysis of a high-resolution hand-written digits data set with writer characteristics
Nov 04, 2020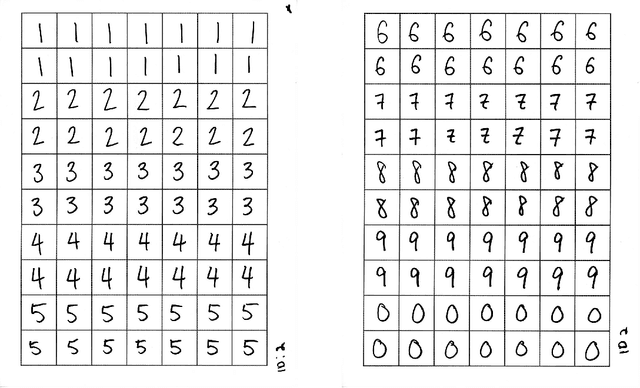
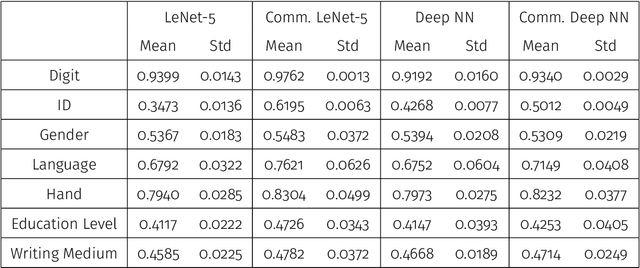

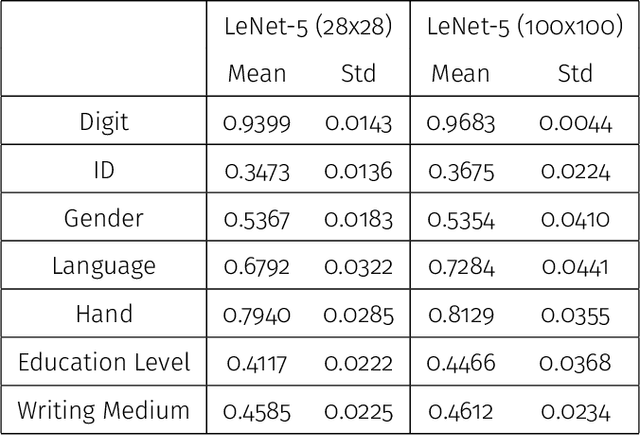
The contributions in this article are two-fold. First, we introduce a new hand-written digit data set that we collected. It contains high-resolution images of hand-written digits together with various writer characteristics which are not available in the well-known MNIST database. The data set is publicly available and is designed to create new research opportunities. Second, we perform a first analysis of this new data set. We begin with simple supervised tasks. We assess the predictability of the writer characteristics gathered, the effect of using some of those characteristics as predictors in classification task and the effect of higher resolution images on classification accuracy. We also explore semi-supervised applications; we can leverage the high quantity of hand-written digits data sets already existing online to improve the accuracy of various classifications task with noticeable success. Finally, we also demonstrate the generative perspective offered by this new data set; we are able to generate images that mimics the writing style of specific writers. The data set provides new research opportunities and our analysis establishes benchmarks and showcases some of the new opportunities made possible with this new data set.
An evaluation of machine learning techniques to predict the outcome of children treated for Hodgkin-Lymphoma on the AHOD0031 trial: A report from the Children's Oncology Group
Jan 15, 2020
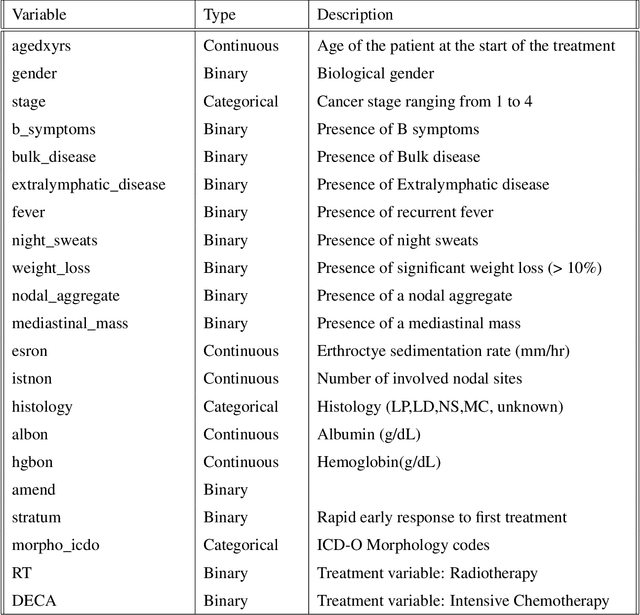
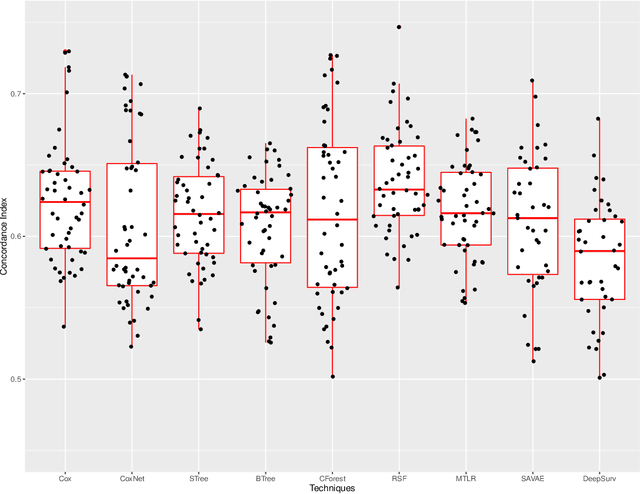
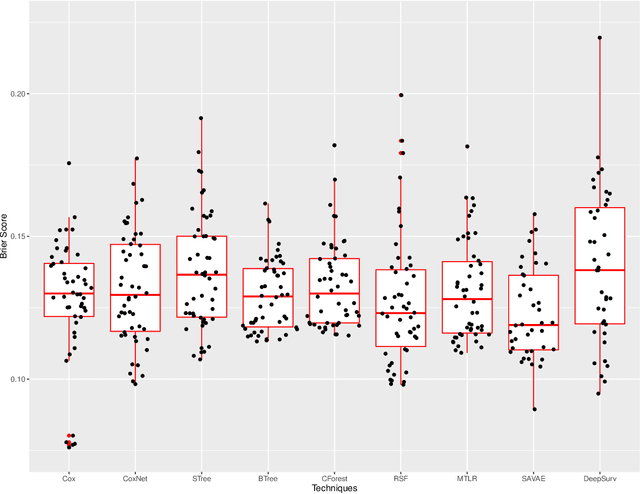
In this manuscript we analyze a data set containing information on children with Hodgkin Lymphoma (HL) enrolled on a clinical trial. Treatments received and survival status were collected together with other covariates such as demographics and clinical measurements. Our main task is to explore the potential of machine learning (ML) algorithms in a survival analysis context in order to improve over the Cox Proportional Hazard (CoxPH) model. We discuss the weaknesses of the CoxPH model we would like to improve upon and then we introduce multiple algorithms, from well-established ones to state-of-the-art models, that solve these issues. We then compare every model according to the concordance index and the brier score. Finally, we produce a series of recommendations, based on our experience, for practitioners that would like to benefit from the recent advances in artificial intelligence.
A Deep Latent-Variable Model Application to Select Treatment Intensity in Survival Analysis
Nov 29, 2018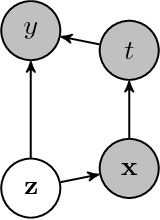
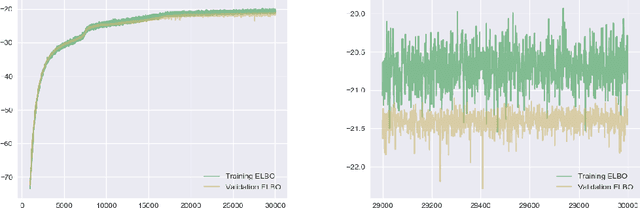
In the following short article we adapt a new and popular machine learning model for inference on medical data sets. Our method is based on the Variational AutoEncoder (VAE) framework that we adapt to survival analysis on small data sets with missing values. In our model, the true health status appears as a set of latent variables that affects the observed covariates and the survival chances. We show that this flexible model allows insightful decision-making using a predicted distribution and outperforms a classic survival analysis model.
Predicting University Students' Academic Success and Major using Random Forests
Sep 30, 2018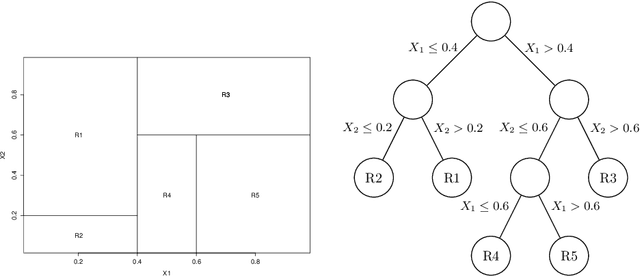
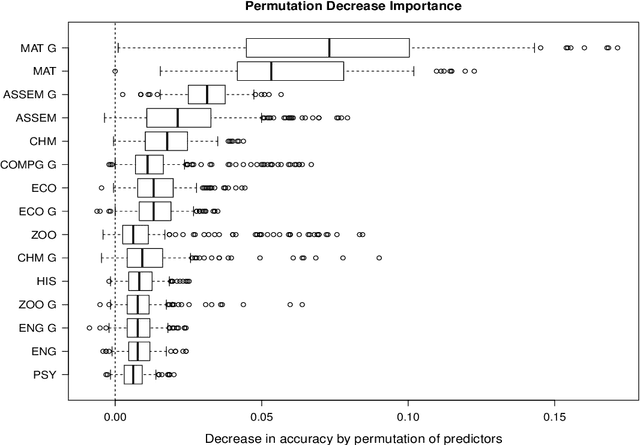
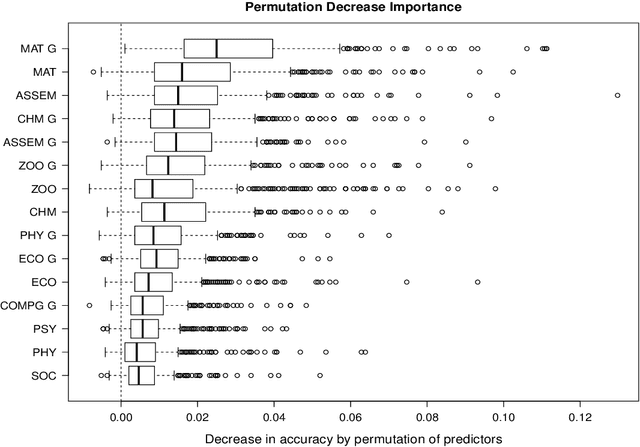
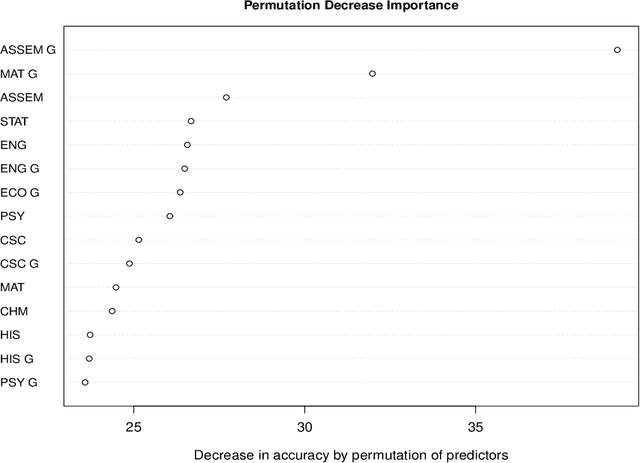
In this article, a large data set containing every course taken by every undergraduate student in a major university in Canada over 10 years is analysed. Modern machine learning algorithms can use large data sets to build useful tools for the data provider, in this case, the university. In this article, two classifiers are constructed using random forests. To begin, the first two semesters of courses completed by a student are used to predict if they will obtain an undergraduate degree. Secondly, for the students that completed a program, their major is predicted using once again the first few courses they've registered to. A classification tree is an intuitive and powerful classifier and building a random forest of trees lowers the variance of the classifier and also prevents overfitting. Random forests also allow for reliable variable importance measurements. These measures explain what variables are useful to both of the classifiers and can be used to better understand what is statistically related to the students' situation. The results are two accurate classifiers and a variable importance analysis that provides useful information to the university.
Handling Missing Values using Decision Trees with Branch-Exclusive Splits
Apr 26, 2018


In this article we propose a new decision tree construction algorithm. The proposed approach allows the algorithm to interact with some predictors that are only defined in subspaces of the feature space. One way to utilize this new tool is to create or use one of the predictors to keep track of missing values. This predictor can later be used to define the subspace where predictors with missing values are available for the data partitioning process. By doing so, this new classification tree can handle missing values for both modelling and prediction. The algorithm is tested against simulated and real data. The result is a classification procedure that efficiently handles missing values and produces results that are more accurate and more interpretable than most common procedures.