 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of a high-resolution hand-written digits data set with writer characteristics
Nov 04, 2020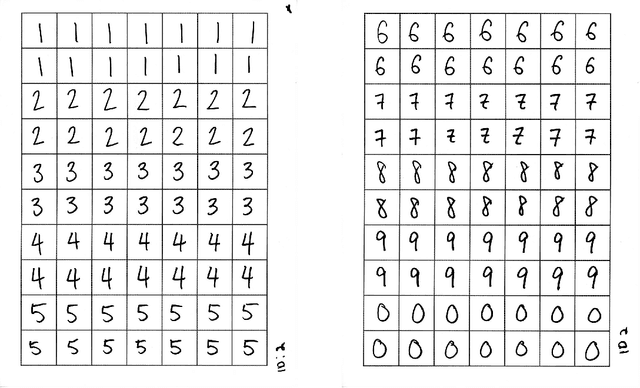
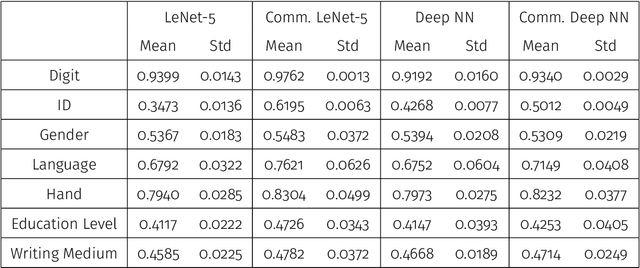

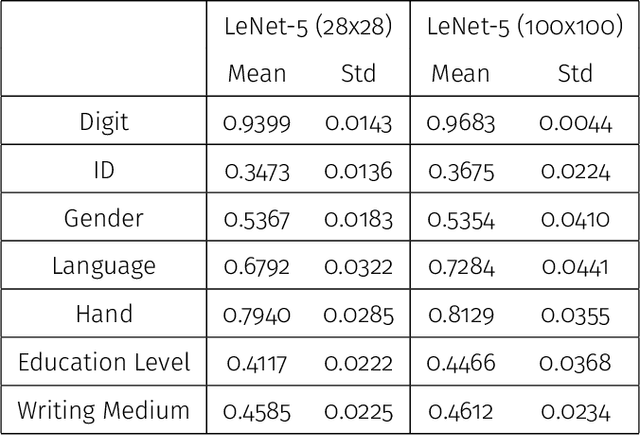
The contributions in this article are two-fold. First, we introduce a new hand-written digit data set that we collected. It contains high-resolution images of hand-written digits together with various writer characteristics which are not available in the well-known MNIST database. The data set is publicly available and is designed to create new research opportunities. Second, we perform a first analysis of this new data set. We begin with simple supervised tasks. We assess the predictability of the writer characteristics gathered, the effect of using some of those characteristics as predictors in classification task and the effect of higher resolution images on classification accuracy. We also explore semi-supervised applications; we can leverage the high quantity of hand-written digits data sets already existing online to improve the accuracy of various classifications task with noticeable success. Finally, we also demonstrate the generative perspective offered by this new data set; we are able to generate images that mimics the writing style of specific writers. The data set provides new research opportunities and our analysis establishes benchmarks and showcases some of the new opportunities made possible with this new data set.
An evaluation of machine learning techniques to predict the outcome of children treated for Hodgkin-Lymphoma on the AHOD0031 trial: A report from the Children's Oncology Group
Jan 15, 2020
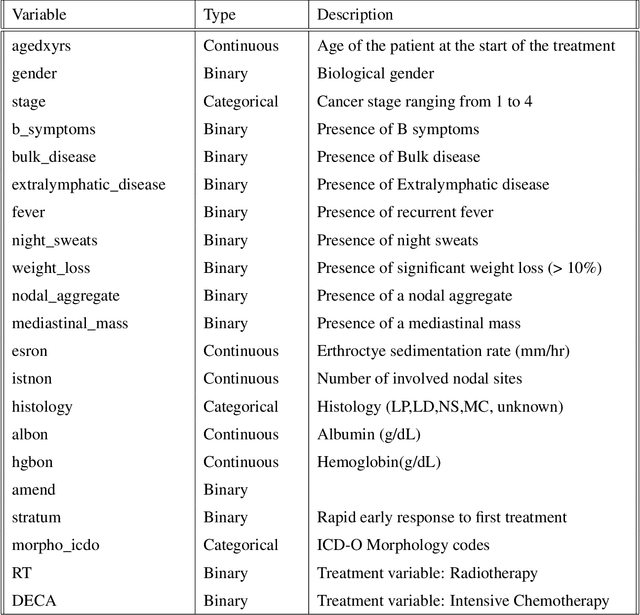
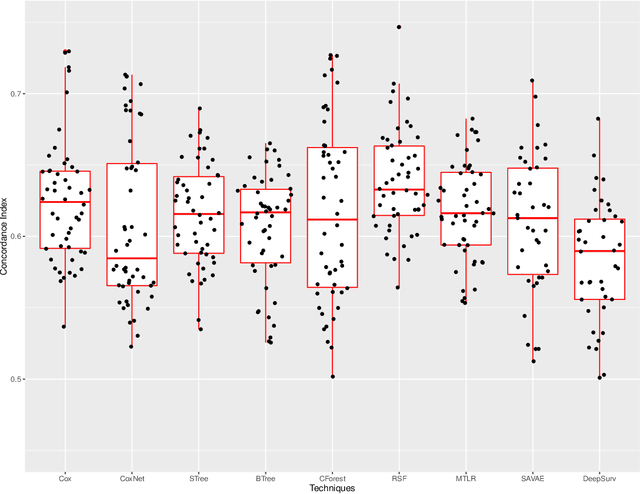
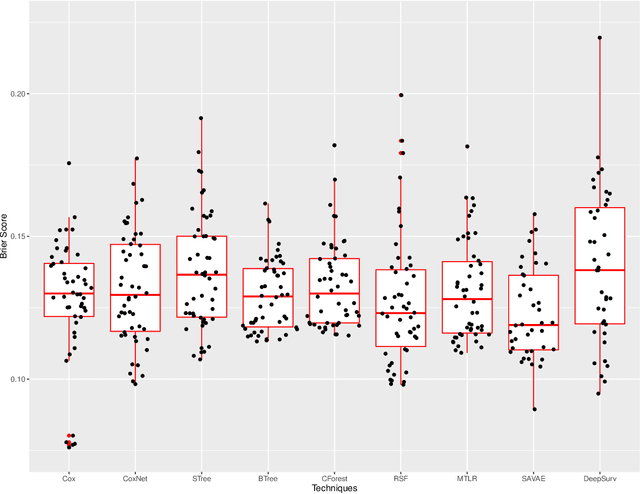
In this manuscript we analyze a data set containing information on children with Hodgkin Lymphoma (HL) enrolled on a clinical trial. Treatments received and survival status were collected together with other covariates such as demographics and clinical measurements. Our main task is to explore the potential of machine learning (ML) algorithms in a survival analysis context in order to improve over the Cox Proportional Hazard (CoxPH) model. We discuss the weaknesses of the CoxPH model we would like to improve upon and then we introduce multiple algorithms, from well-established ones to state-of-the-art models, that solve these issues. We then compare every model according to the concordance index and the brier score. Finally, we produce a series of recommendations, based on our experience, for practitioners that would like to benefit from the recent advances in artificial intelligence.
A Deep Latent-Variable Model Application to Select Treatment Intensity in Survival Analysis
Nov 29, 2018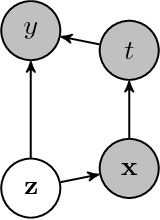
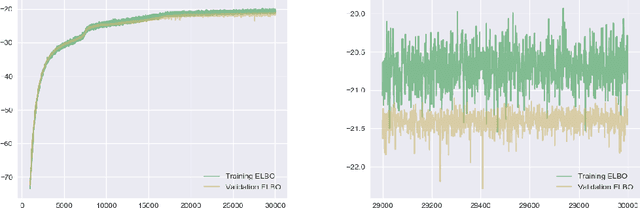
In the following short article we adapt a new and popular machine learning model for inference on medical data sets. Our method is based on the Variational AutoEncoder (VAE) framework that we adapt to survival analysis on small data sets with missing values. In our model, the true health status appears as a set of latent variables that affects the observed covariates and the survival chances. We show that this flexible model allows insightful decision-making using a predicted distribution and outperforms a classic survival analysis model.
Predicting University Students' Academic Success and Major using Random Forests
Sep 30, 2018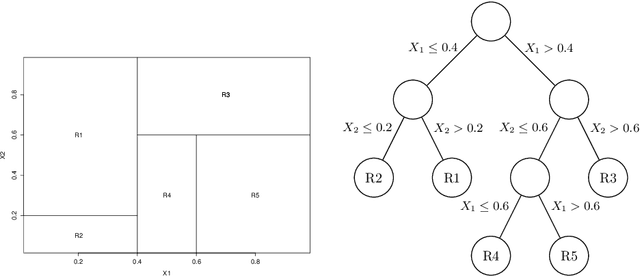
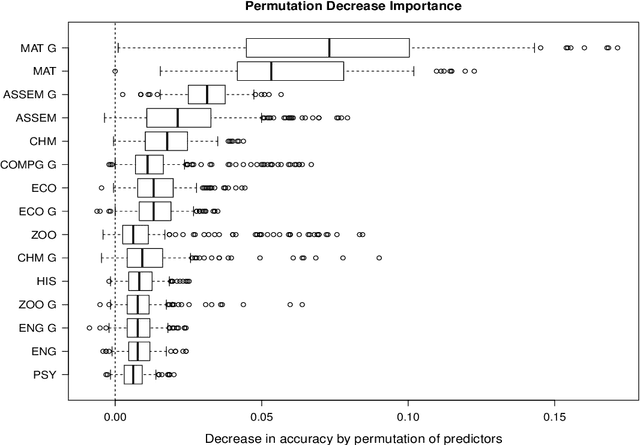
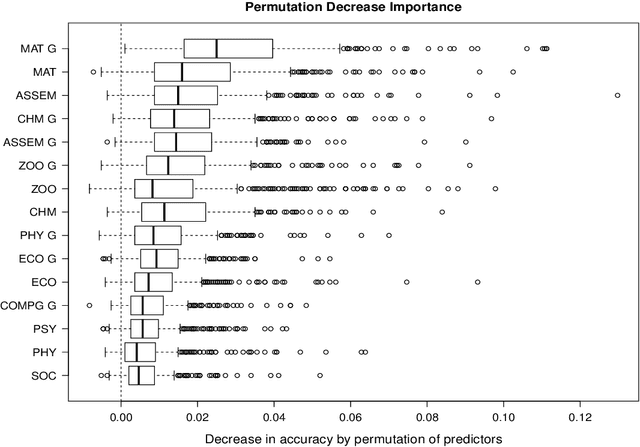
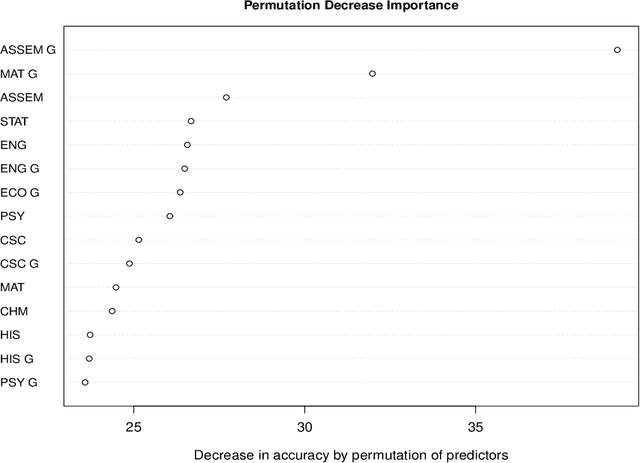
In this article, a large data set containing every course taken by every undergraduate student in a major university in Canada over 10 years is analysed. Modern machine learning algorithms can use large data sets to build useful tools for the data provider, in this case, the university. In this article, two classifiers are constructed using random forests. To begin, the first two semesters of courses completed by a student are used to predict if they will obtain an undergraduate degree. Secondly, for the students that completed a program, their major is predicted using once again the first few courses they've registered to. A classification tree is an intuitive and powerful classifier and building a random forest of trees lowers the variance of the classifier and also prevents overfitting. Random forests also allow for reliable variable importance measurements. These measures explain what variables are useful to both of the classifiers and can be used to better understand what is statistically related to the students' situation. The results are two accurate classifiers and a variable importance analysis that provides useful information to the university.
Handling Missing Values using Decision Trees with Branch-Exclusive Splits
Apr 26, 2018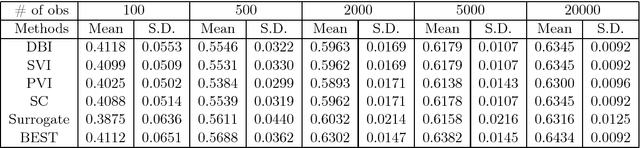
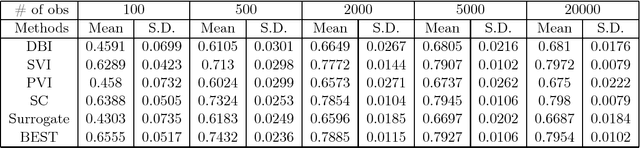


In this article we propose a new decision tree construction algorithm. The proposed approach allows the algorithm to interact with some predictors that are only defined in subspaces of the feature space. One way to utilize this new tool is to create or use one of the predictors to keep track of missing values. This predictor can later be used to define the subspace where predictors with missing values are available for the data partitioning process. By doing so, this new classification tree can handle missing values for both modelling and prediction. The algorithm is tested against simulated and real data. The result is a classification procedure that efficiently handles missing values and produces results that are more accurate and more interpretable than most common procedures.
Likelihood Inflating Sampling Algorithm
Jun 30, 2017
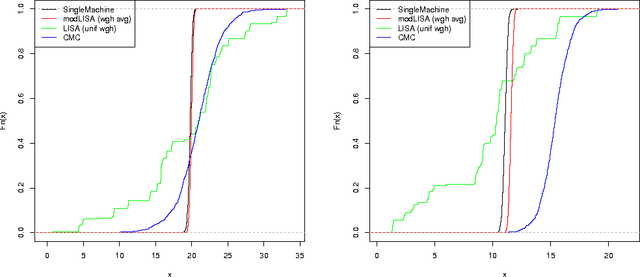
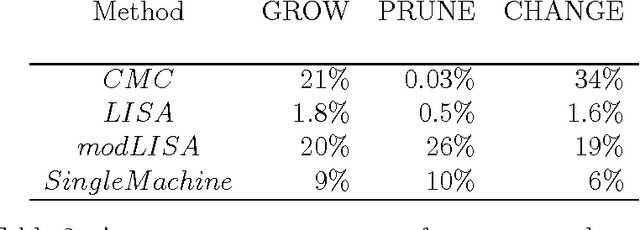

Markov Chain Monte Carlo (MCMC) sampling from a posterior distribution corresponding to a massive data set can be computationally prohibitive since producing one sample requires a number of operations that is linear in the data size. In this paper, we introduce a new communication-free parallel method, the Likelihood Inflating Sampling Algorithm (LISA), that significantly reduces computational costs by randomly splitting the dataset into smaller subsets and running MCMC methods independently in parallel on each subset using different processors. Each processor will be used to run an MCMC chain that samples sub-posterior distributions which are defined using an "inflated" likelihood function. We develop a strategy for combining the draws from different sub-posteriors to study the full posterior of the Bayesian Additive Regression Trees (BART) model. The performance of the method is tested using both simulated and real data.