 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of a high-resolution hand-written digits data set with writer characteristics
Paper and Code
Nov 04, 2020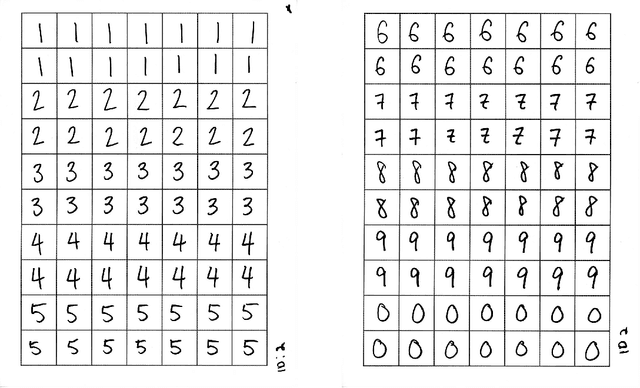
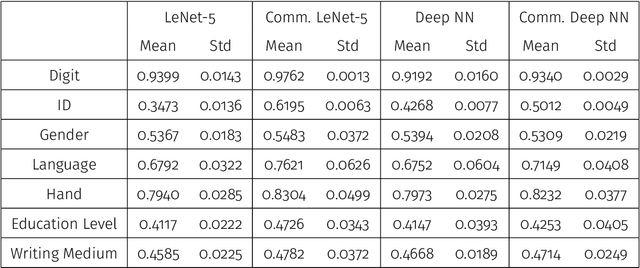

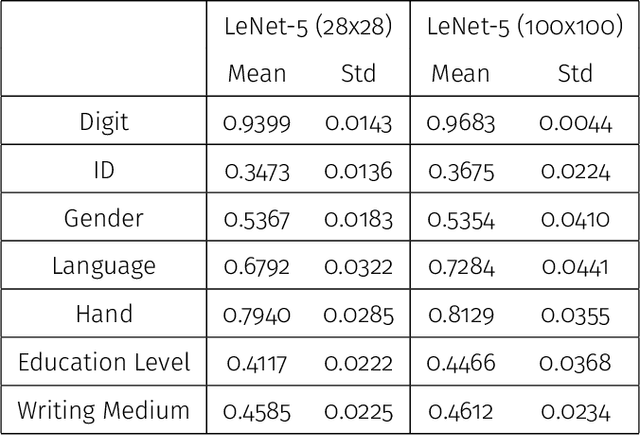
The contributions in this article are two-fold. First, we introduce a new hand-written digit data set that we collected. It contains high-resolution images of hand-written digits together with various writer characteristics which are not available in the well-known MNIST database. The data set is publicly available and is designed to create new research opportunities. Second, we perform a first analysis of this new data set. We begin with simple supervised tasks. We assess the predictability of the writer characteristics gathered, the effect of using some of those characteristics as predictors in classification task and the effect of higher resolution images on classification accuracy. We also explore semi-supervised applications; we can leverage the high quantity of hand-written digits data sets already existing online to improve the accuracy of various classifications task with noticeable success. Finally, we also demonstrate the generative perspective offered by this new data set; we are able to generate images that mimics the writing style of specific writers. The data set provides new research opportunities and our analysis establishes benchmarks and showcases some of the new opportunities made possible with this new data set.