 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting University Students' Academic Success and Major using Random Forests
Paper and Code
Sep 30, 2018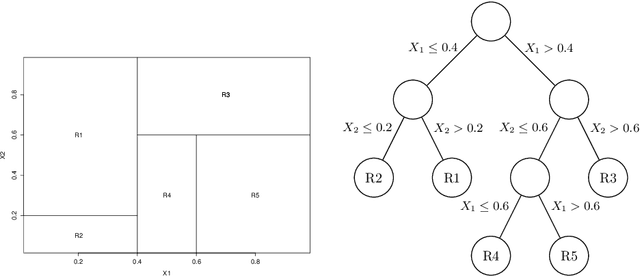
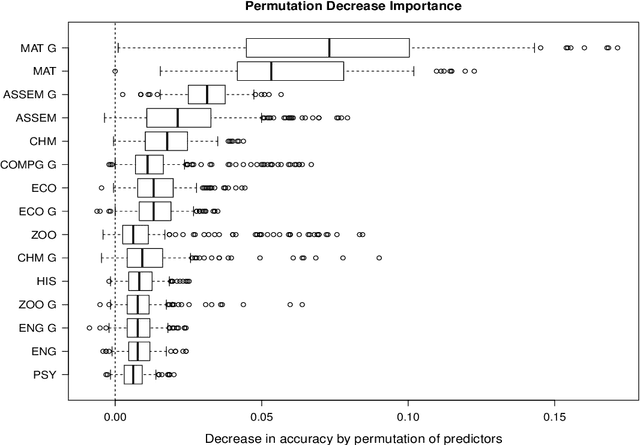
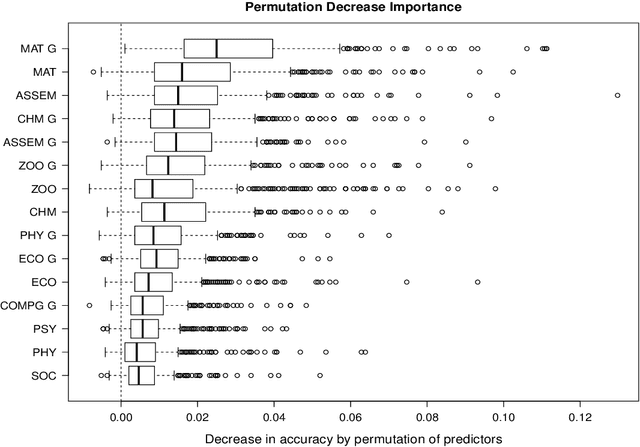
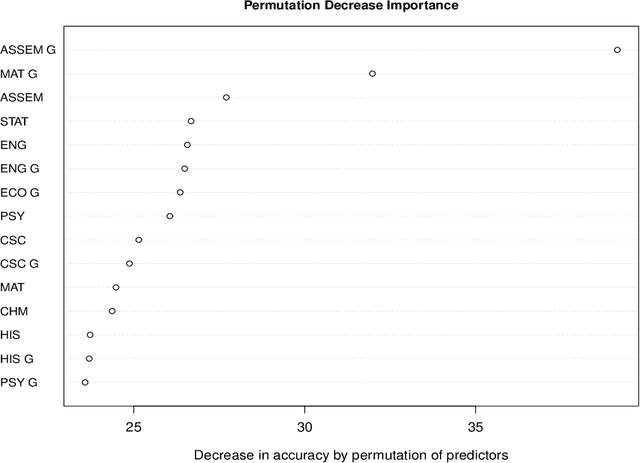
In this article, a large data set containing every course taken by every undergraduate student in a major university in Canada over 10 years is analysed. Modern machine learning algorithms can use large data sets to build useful tools for the data provider, in this case, the university. In this article, two classifiers are constructed using random forests. To begin, the first two semesters of courses completed by a student are used to predict if they will obtain an undergraduate degree. Secondly, for the students that completed a program, their major is predicted using once again the first few courses they've registered to. A classification tree is an intuitive and powerful classifier and building a random forest of trees lowers the variance of the classifier and also prevents overfitting. Random forests also allow for reliable variable importance measurements. These measures explain what variables are useful to both of the classifiers and can be used to better understand what is statistically related to the students' situation. The results are two accurate classifiers and a variable importance analysis that provides useful information to the university.