 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Missing Values using Decision Trees with Branch-Exclusive Splits
Paper and Code
Apr 26, 2018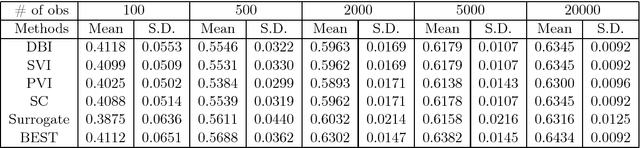
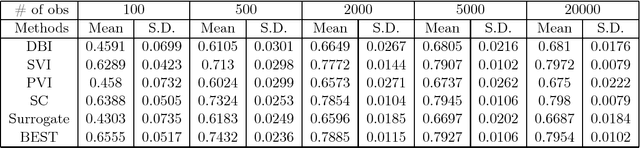


In this article we propose a new decision tree construction algorithm. The proposed approach allows the algorithm to interact with some predictors that are only defined in subspaces of the feature space. One way to utilize this new tool is to create or use one of the predictors to keep track of missing values. This predictor can later be used to define the subspace where predictors with missing values are available for the data partitioning process. By doing so, this new classification tree can handle missing values for both modelling and prediction. The algorithm is tested against simulated and real data. The result is a classification procedure that efficiently handles missing values and produces results that are more accurate and more interpretable than most common procedures.