 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Hypothesis Path Planning with Uncertain Object Detections
Aug 14, 2023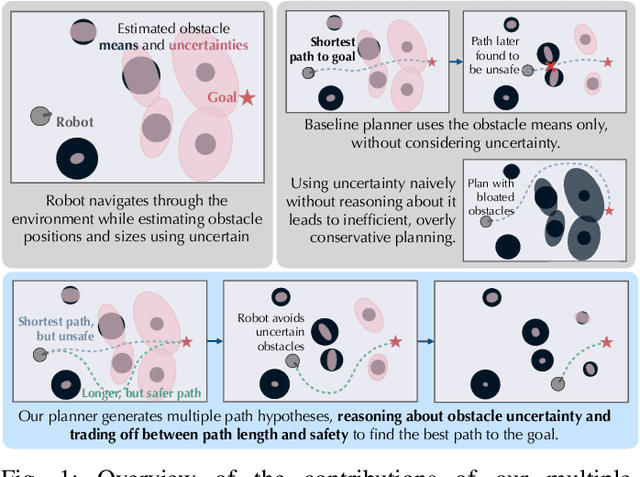
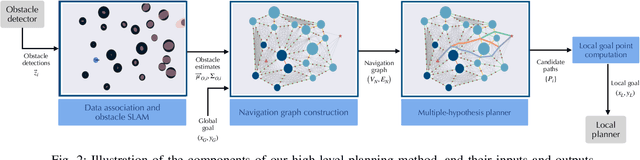
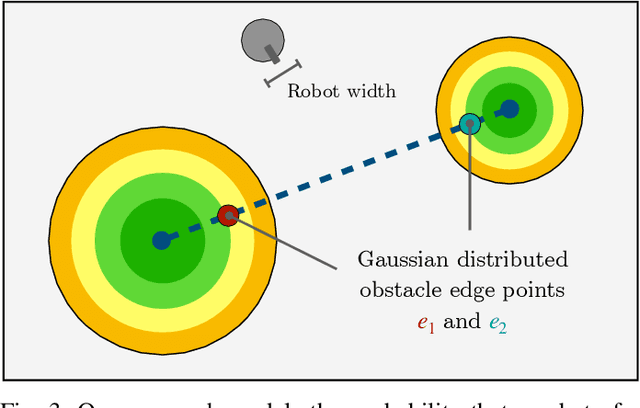
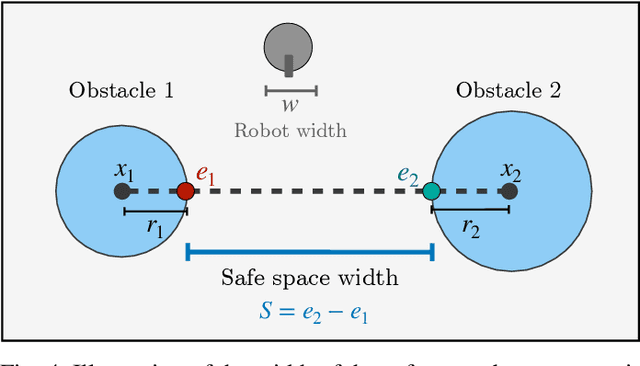
Path planning in obstacle-dense environments is a key challenge in robotics, and depends on inferring scene attributes and associated uncertainties. We present a multiple-hypothesis path planner designed to navigate complex environments using obstacle detections. Path hypotheses are generated by reasoning about uncertainty and range, as initial detections are typically at far ranges with high uncertainty, before subsequent detections reduce this uncertainty. Given estimated obstacles, we build a graph of pairwise connections between objects based on the probability that the robot can safely pass between the pair. The graph is updated in real time and pruned of unsafe paths, providing probabilistic safety guarantees. The planner generates path hypotheses over this graph, then trades between safety and path length to intelligently optimize the best route. We evaluate our planner on randomly generated simulated forests, and find that in the most challenging environments, it increases the navigation success rate over an A* baseline from 20% to 75%. Results indicate that the use of evolving, range-based uncertainty and multiple hypotheses are critical for navigating dense environments.
Detecting and Mapping Trees in Unstructured Environments with a Stereo Camera and Pseudo-Lidar
Mar 29, 2021

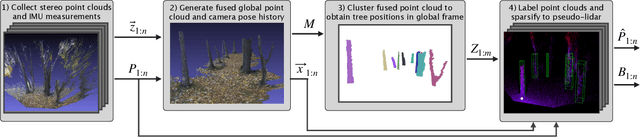
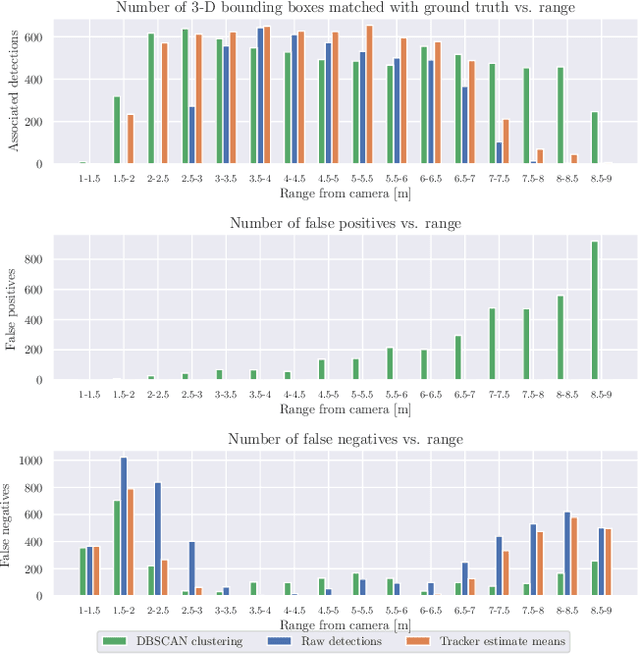
We present a method for detecting and mapping trees in noisy stereo camera point clouds, using a learned 3-D object detector. Inspired by recent advancements in 3-D object detection using a pseudo-lidar representation for stereo data, we train a PointRCNN detector to recognize trees in forest-like environments. We generate detector training data with a novel automatic labeling process that clusters a fused global point cloud. This process annotates large stereo point cloud training data sets with minimal user supervision, and unlike previous pseudo-lidar detection pipelines, requires no 3-D ground truth from other sensors such as lidar. Our mapping system additionally uses a Kalman filter to associate detections and consistently estimate the positions and sizes of trees. We collect a data set for tree detection consisting of 8680 stereo point clouds, and validate our method on an outdoors test sequence. Our results demonstrate robust tree recognition in noisy stereo data at ranges of up to 7 meters, on 720p resolution images from a Stereolabs ZED 2 camera. Code and data are available at https://github.com/brian-h-wang/pseudolidar-tree-detection.
LDLS: 3-D Object Segmentation Through Label Diffusion From 2-D Images
Oct 30, 2019
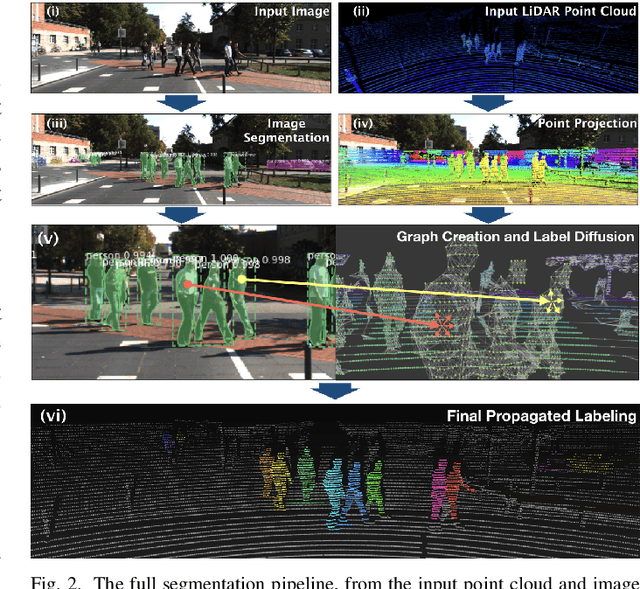
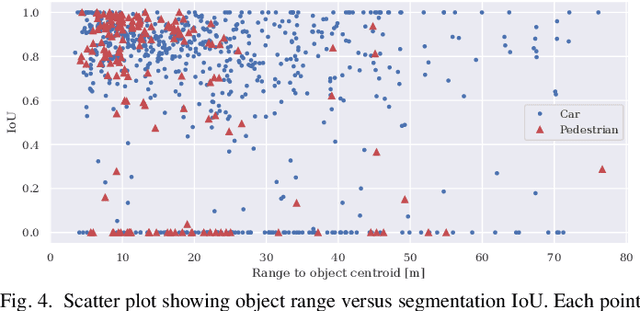
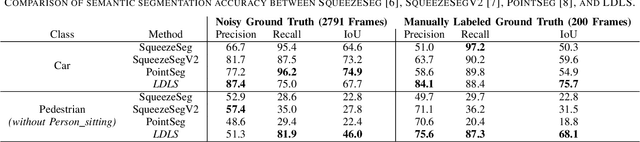
Object segmentation in three-dimensional (3-D) point clouds is a critical task for robots capable of 3-D perception. Despite the impressive performance of deep learning-based approaches on object segmentation in 2-D images, deep learning has not been applied nearly as successfully for 3-D point cloud segmentation. Deep networks generally require large amounts of labeled training data, which are readily available for 2-D images but are difficult to produce for 3-D point clouds. In this letter, we present Label Diffusion Lidar Segmentation (LDLS), a novel approach for 3-D point cloud segmentation, which leverages 2-D segmentation of an RGB image from an aligned camera to avoid the need for training on annotated 3-D data. We obtain 2-D segmentation predictions by applying Mask-RCNN to the RGB image, and then link this image to a 3-D lidar point cloud by building a graph of connections among 3-D points and 2-D pixels. This graph then directs a semi-supervised label diffusion process, where the 2-D pixels act as source nodes that diffuse object label information through the 3-D point cloud, resulting in a complete 3-D point cloud segmentation. We conduct empirical studies on the KITTI benchmark dataset and on a mobile robot, demonstrating wide applicability and superior performance of LDLS compared with the previous state of the art in 3-D point cloud segmentation, without any need for either 3-D training data or fine tuning of the 2-D image segmentation model.
Anytime Stereo Image Depth Estimation on Mobile Devices
Oct 26, 2018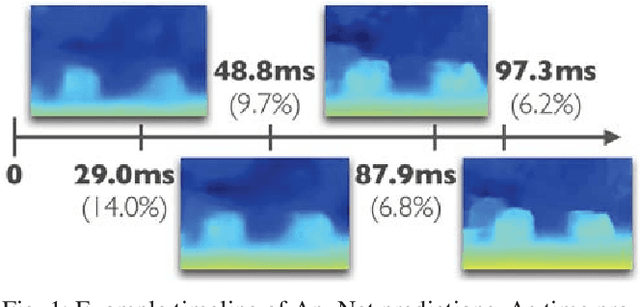
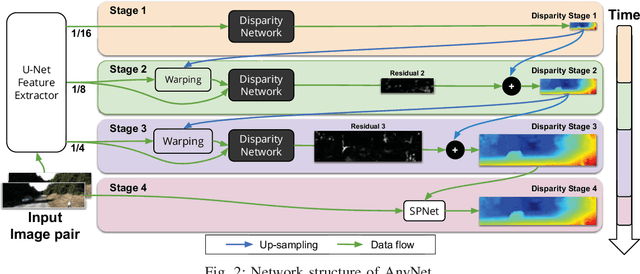
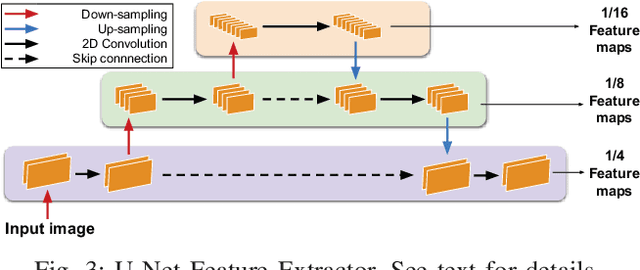
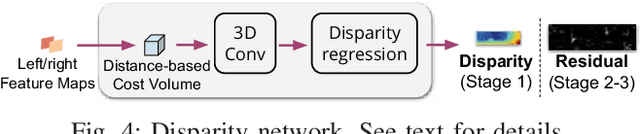
Many real-world applications of stereo depth estimation in robotics require the generation of accurate disparity maps in real time under significant computational constraints. Current state-of-the-art algorithms can either generate accurate but slow mappings, or fast but inaccurate ones, and typically require far too many parameters for power- or memory-constrained devices. Motivated by this shortcoming, we propose a novel approach for disparity prediction in the anytime setting. In contrast to prior work, our end-to-end learned approach can trade off computation and accuracy at inference time. The depth estimation is performed in stages, during which the model can be queried at any time to output its current best estimate. Our final model can process 1242$ \times $375 resolution images within a range of 10-35 FPS on an NVIDIA Jetson TX2 module with only marginal increases in error -- using two orders of magnitude fewer parameters than the most competitive baseline. Our code is available as open source on https://github.com/mileyan/AnyNet .
Deep Person Re-identification for Probabilistic Data Association in Multiple Pedestrian Tracking
Oct 19, 2018

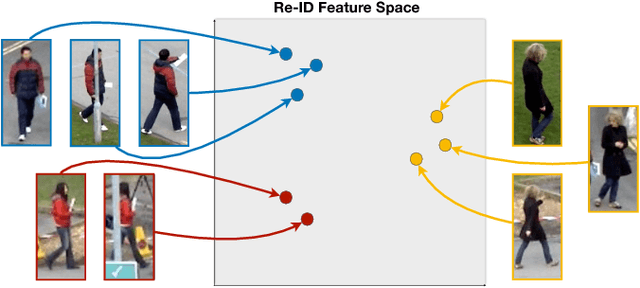

We present a data association method for vision-based multiple pedestrian tracking, using deep convolutional features to distinguish between different people based on their appearances. These re-identification (re-ID) features are learned such that they are invariant to transformations such as rotation, translation, and changes in the background, allowing consistent identification of a pedestrian moving through a scene. We incorporate re-ID features into a general data association likelihood model for multiple person tracking, experimentally validate this model by using it to perform tracking in two evaluation video sequences, and examine the performance improvements gained as compared to several baseline approaches. Our results demonstrate that using deep person re-ID for data association greatly improves tracking robustness to challenges such as occlusions and path crossings.