 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Hypothesis Path Planning with Uncertain Object Detections
Aug 14, 2023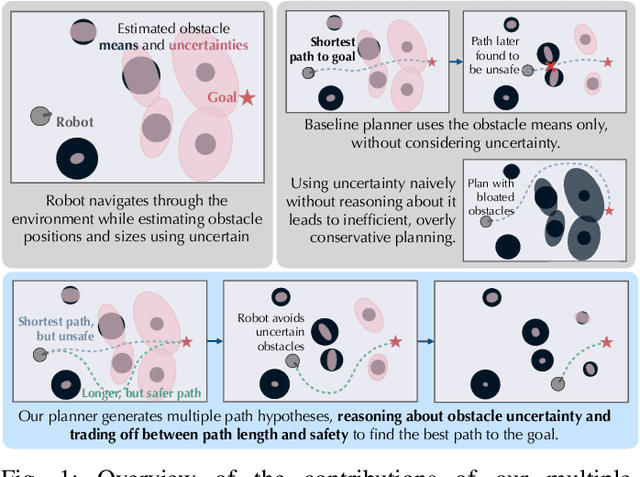
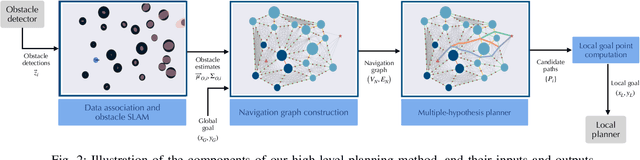
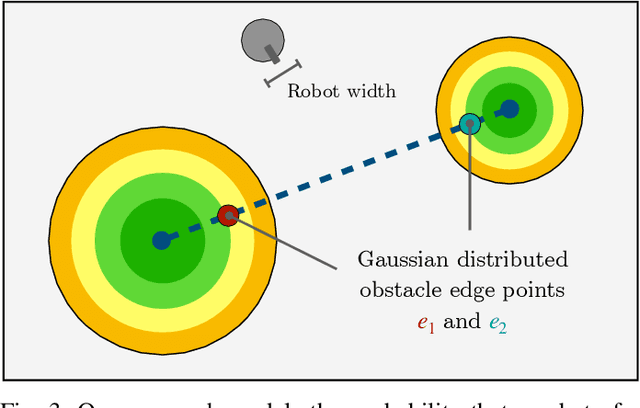
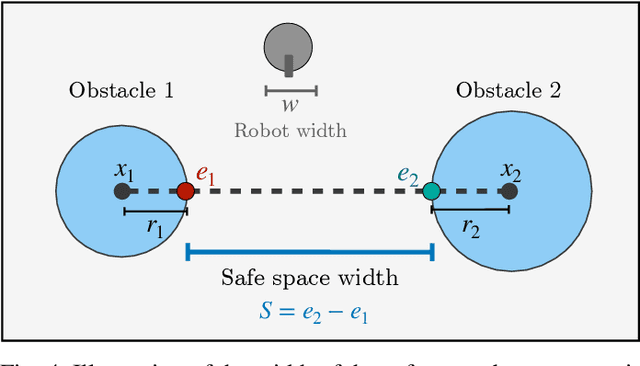
Path planning in obstacle-dense environments is a key challenge in robotics, and depends on inferring scene attributes and associated uncertainties. We present a multiple-hypothesis path planner designed to navigate complex environments using obstacle detections. Path hypotheses are generated by reasoning about uncertainty and range, as initial detections are typically at far ranges with high uncertainty, before subsequent detections reduce this uncertainty. Given estimated obstacles, we build a graph of pairwise connections between objects based on the probability that the robot can safely pass between the pair. The graph is updated in real time and pruned of unsafe paths, providing probabilistic safety guarantees. The planner generates path hypotheses over this graph, then trades between safety and path length to intelligently optimize the best route. We evaluate our planner on randomly generated simulated forests, and find that in the most challenging environments, it increases the navigation success rate over an A* baseline from 20% to 75%. Results indicate that the use of evolving, range-based uncertainty and multiple hypotheses are critical for navigating dense environments.
Learning to Assess Danger from Movies for Cooperative Escape Planning in Hazardous Environments
Jul 27, 2022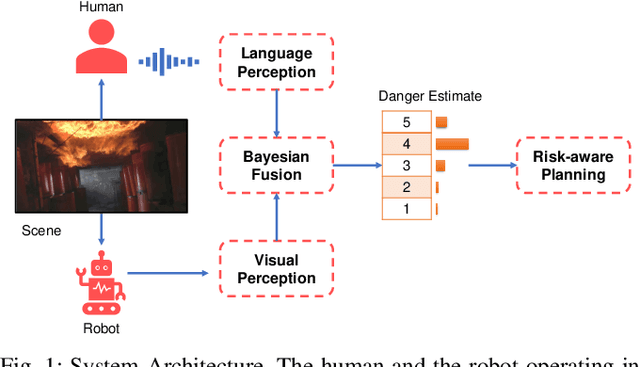
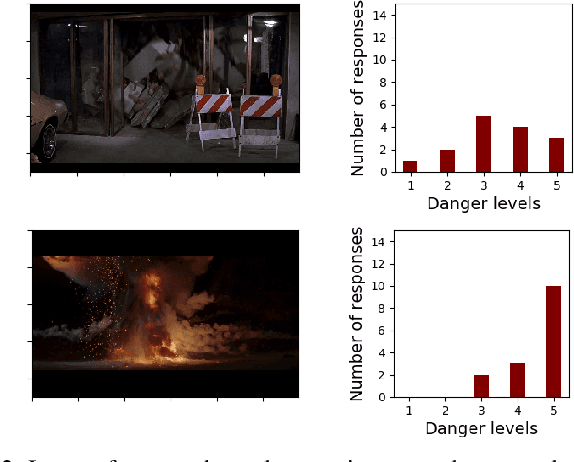


There has been a plethora of work towards improving robot perception and navigation, yet their application in hazardous environments, like during a fire or an earthquake, is still at a nascent stage. We hypothesize two key challenges here: first, it is difficult to replicate such scenarios in the real world, which is necessary for training and testing purposes. Second, current systems are not fully able to take advantage of the rich multi-modal data available in such hazardous environments. To address the first challenge, we propose to harness the enormous amount of visual content available in the form of movies and TV shows, and develop a dataset that can represent hazardous environments encountered in the real world. The data is annotated with high-level danger ratings for realistic disaster images, and corresponding keywords are provided that summarize the content of the scene. In response to the second challenge, we propose a multi-modal danger estimation pipeline for collaborative human-robot escape scenarios. Our Bayesian framework improves danger estimation by fusing information from robot's camera sensor and language inputs from the human. Furthermore, we augment the estimation module with a risk-aware planner that helps in identifying safer paths out of the dangerous environment. Through extensive simulations, we exhibit the advantages of our multi-modal perception framework that gets translated into tangible benefits such as higher success rate in a collaborative human-robot mission.
Exploiting Natural Language for Efficient Risk-Aware Multi-robot SaR Planning
Apr 08, 2021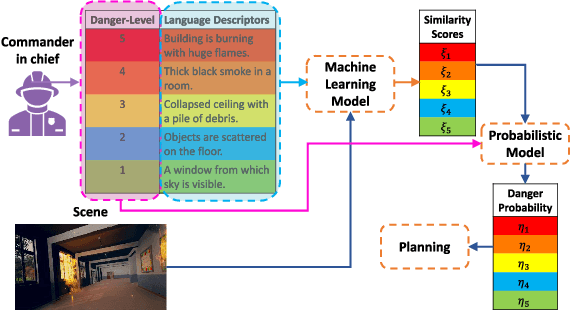
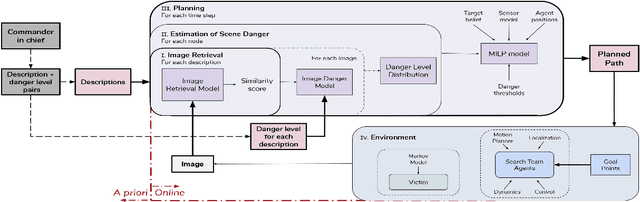


The ability to develop a high-level understanding of a scene, such as perceiving danger levels, can prove valuable in planning multi-robot search and rescue (SaR) missions. In this work, we propose to uniquely leverage natural language descriptions from the mission commander in chief and image data captured by robots to estimate scene danger. Given a description and an image, a state-of-the-art deep neural network is used to assess a corresponding similarity score, which is then converted into a probabilistic distribution of danger levels. Because commonly used visio-linguistic datasets do not represent SaR missions well, we collect a large-scale image-description dataset from synthetic images taken from realistic disaster scenes and use it to train our machine learning model. A risk-aware variant of the Multi-robot Efficient Search Path Planning (MESPP) problem is then formulated to use the danger estimates in order to account for high-risk locations in the environment when planning the searchers' paths. The problem is solved via a distributed approach based on Mixed-Integer Linear Programming. Our experiments demonstrate that our framework allows to plan safer yet highly successful search missions, abiding to the two most important aspects of SaR missions: to ensure both searchers' and victim safety.
* 8 pages, 5 figures. To be presented at the IEEE International Conference on Robotics and Automation, 2021. Dataset available at: https://github.com/vikshree/DISC-L.git