 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Assess Danger from Movies for Cooperative Escape Planning in Hazardous Environments
Jul 27, 2022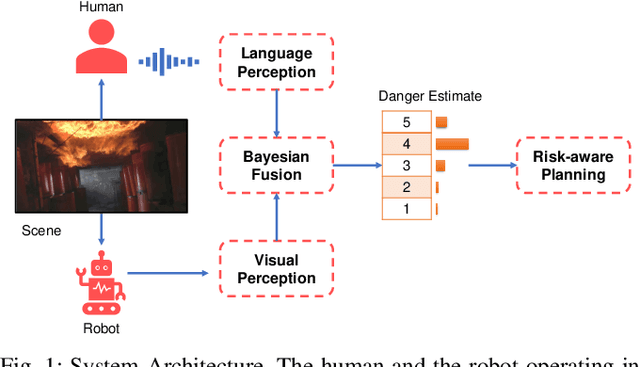
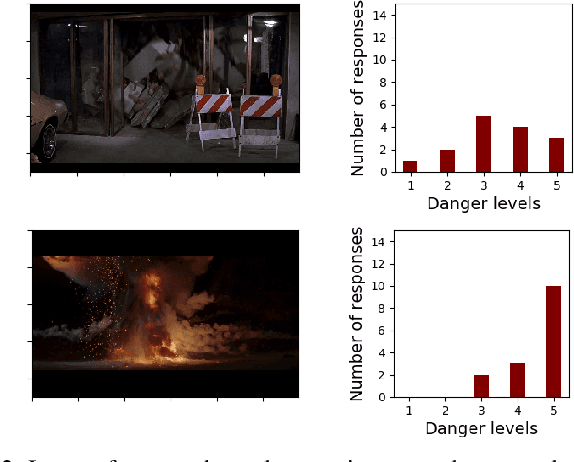


There has been a plethora of work towards improving robot perception and navigation, yet their application in hazardous environments, like during a fire or an earthquake, is still at a nascent stage. We hypothesize two key challenges here: first, it is difficult to replicate such scenarios in the real world, which is necessary for training and testing purposes. Second, current systems are not fully able to take advantage of the rich multi-modal data available in such hazardous environments. To address the first challenge, we propose to harness the enormous amount of visual content available in the form of movies and TV shows, and develop a dataset that can represent hazardous environments encountered in the real world. The data is annotated with high-level danger ratings for realistic disaster images, and corresponding keywords are provided that summarize the content of the scene. In response to the second challenge, we propose a multi-modal danger estimation pipeline for collaborative human-robot escape scenarios. Our Bayesian framework improves danger estimation by fusing information from robot's camera sensor and language inputs from the human. Furthermore, we augment the estimation module with a risk-aware planner that helps in identifying safer paths out of the dangerous environment. Through extensive simulations, we exhibit the advantages of our multi-modal perception framework that gets translated into tangible benefits such as higher success rate in a collaborative human-robot mission.
Orientation-Discriminative Feature Representation for Decentralized Pedestrian Tracking
Feb 26, 2022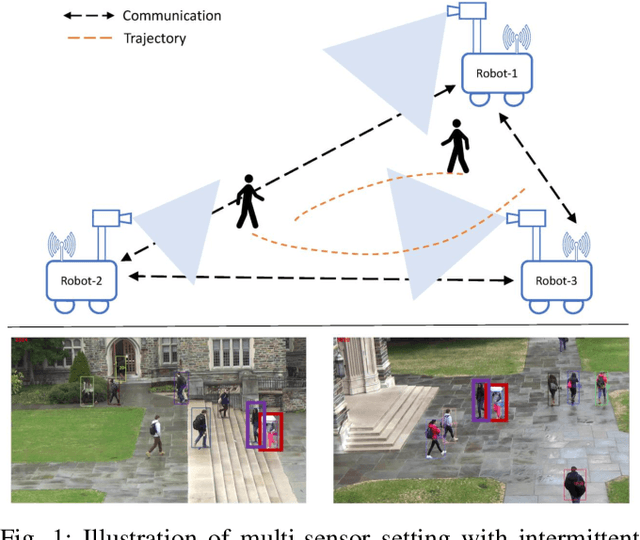
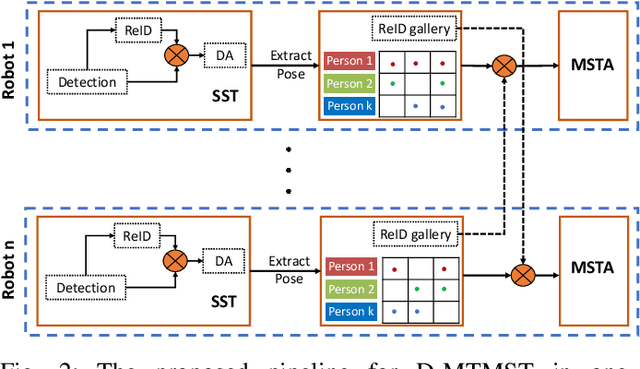
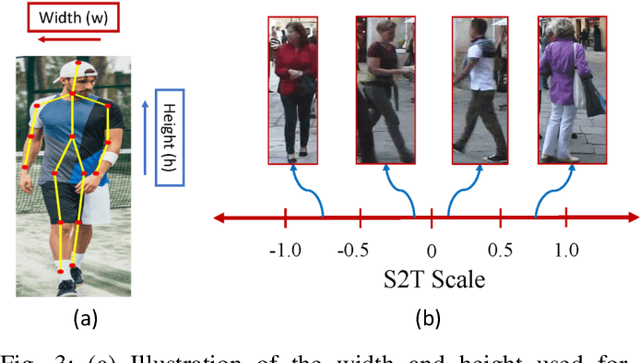
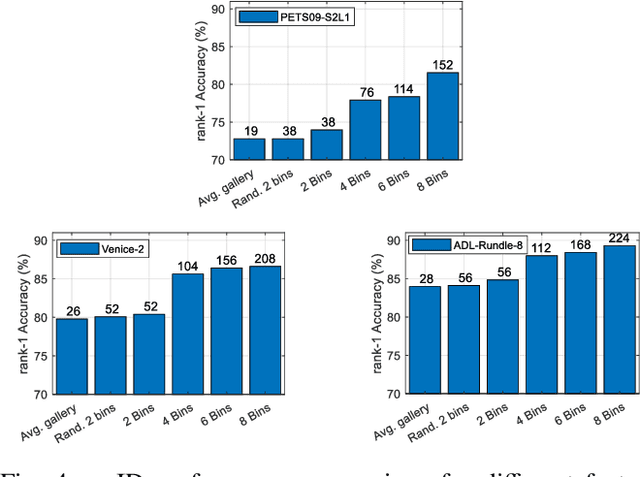
This paper focuses on the problem of decentralized pedestrian tracking using a sensor network. Traditional works on pedestrian tracking usually use a centralized framework, which becomes less practical for robotic applications due to limited communication bandwidth. Our paper proposes a communication-efficient, orientation-discriminative feature representation to characterize pedestrian appearance information, that can be shared among sensors. Building upon that representation, our work develops a cross-sensor track association approach to achieve decentralized tracking. Extensive evaluations are conducted on publicly available datasets and results show that our proposed approach leads to improved performance in multi-sensor tracking.
Exploiting Natural Language for Efficient Risk-Aware Multi-robot SaR Planning
Apr 08, 2021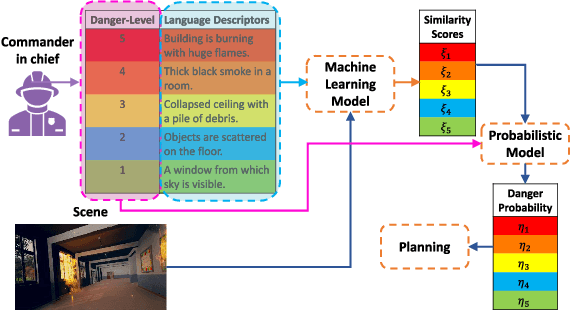
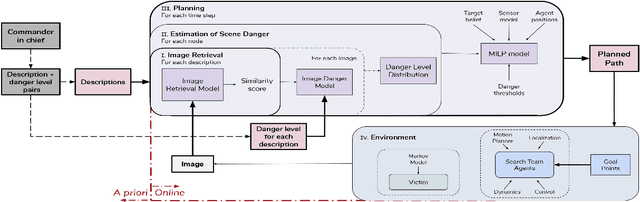


The ability to develop a high-level understanding of a scene, such as perceiving danger levels, can prove valuable in planning multi-robot search and rescue (SaR) missions. In this work, we propose to uniquely leverage natural language descriptions from the mission commander in chief and image data captured by robots to estimate scene danger. Given a description and an image, a state-of-the-art deep neural network is used to assess a corresponding similarity score, which is then converted into a probabilistic distribution of danger levels. Because commonly used visio-linguistic datasets do not represent SaR missions well, we collect a large-scale image-description dataset from synthetic images taken from realistic disaster scenes and use it to train our machine learning model. A risk-aware variant of the Multi-robot Efficient Search Path Planning (MESPP) problem is then formulated to use the danger estimates in order to account for high-risk locations in the environment when planning the searchers' paths. The problem is solved via a distributed approach based on Mixed-Integer Linear Programming. Our experiments demonstrate that our framework allows to plan safer yet highly successful search missions, abiding to the two most important aspects of SaR missions: to ensure both searchers' and victim safety.
* 8 pages, 5 figures. To be presented at the IEEE International Conference on Robotics and Automation, 2021. Dataset available at: https://github.com/vikshree/DISC-L.git
Interactive Natural Language-based Person Search
Feb 19, 2020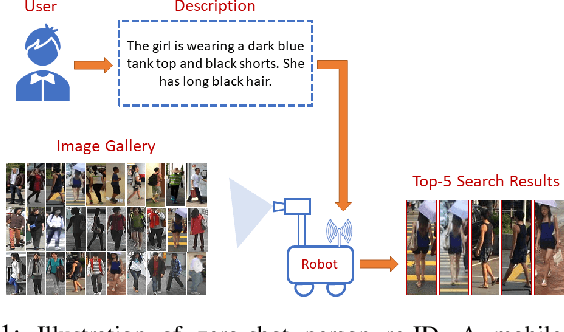
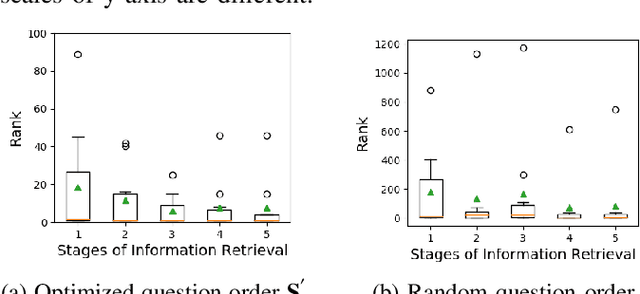

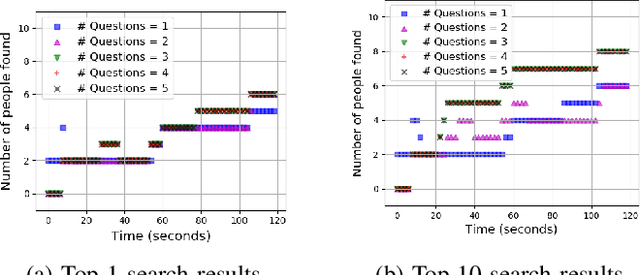
In this work, we consider the problem of searching people in an unconstrained environment, with natural language descriptions. Specifically, we study how to systematically design an algorithm to effectively acquire descriptions from humans. An algorithm is proposed by adapting models, used for visual and language understanding, to search a person of interest (POI) in a principled way, achieving promising results without the need to re-design another complicated model. We then investigate an iterative question-answering (QA) strategy that enable robots to request additional information about the POI's appearance from the user. To this end, we introduce a greedy algorithm to rank questions in terms of their significance, and equip the algorithm with the capability to dynamically adjust the length of human-robot interaction according to model's uncertainty. Our approach is validated not only on benchmark datasets but on a mobile robot, moving in a dynamic and crowded environment.
* 8 pages, 12 figures, Published in IEEE Robotics and Automation Letters (RA-L), "Dataset at: https://github.com/vikshree/QA_PersonSearchLanguageData" , Video attachment at: https://www.youtube.com/watch?v=Yyxu8uVUREE&feature=youtu.be
An Empirical Study of Person Re-Identification with Attributes
Jan 25, 2020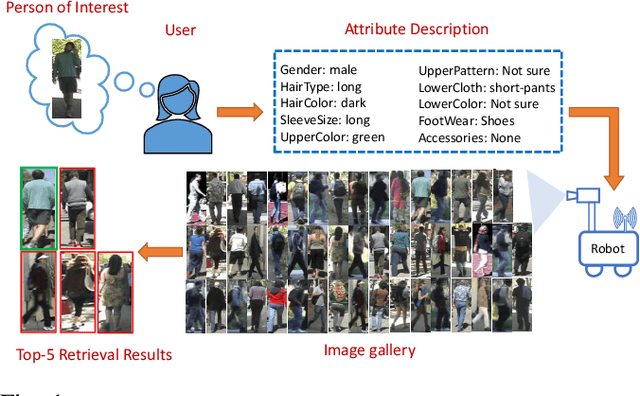
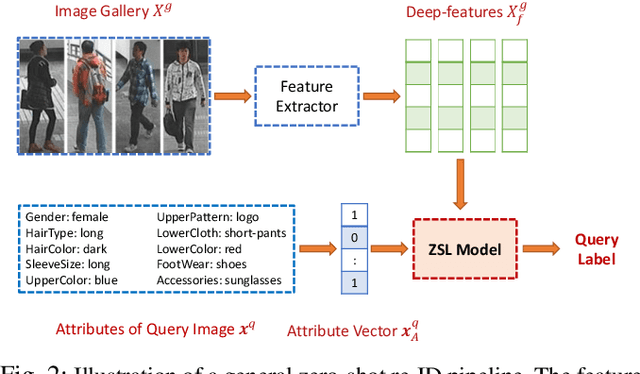
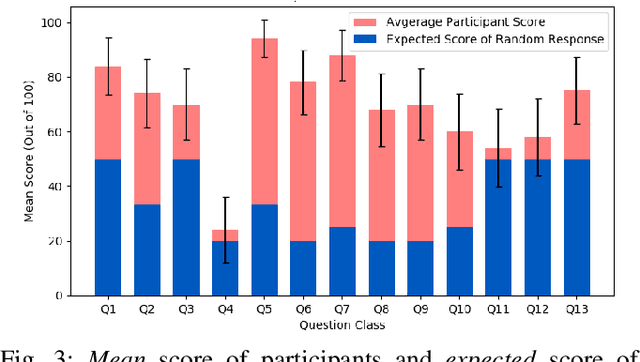

Person re-identification aims to identify a person from an image collection, given one image of that person as the query. There is, however, a plethora of real-life scenarios where we may not have a priori library of query images and therefore must rely on information from other modalities. In this paper, an attribute-based approach is proposed where the person of interest (POI) is described by a set of visual attributes, which are used to perform the search. We compare multiple algorithms and analyze how the quality of attributes impacts the performance. While prior work mostly relies on high precision attributes annotated by experts, we conduct a human-subject study and reveal that certain visual attributes could not be consistently described by human observers, making them less reliable in real applications. A key conclusion is that the performance achieved by non-expert attributes, instead of expert-annotated ones, is a more faithful indicator of the status quo of attribute-based approaches for person re-identification.
RFM-SLAM: Exploiting Relative Feature Measurements to Separate Orientation and Position Estimation in SLAM
Sep 16, 2016
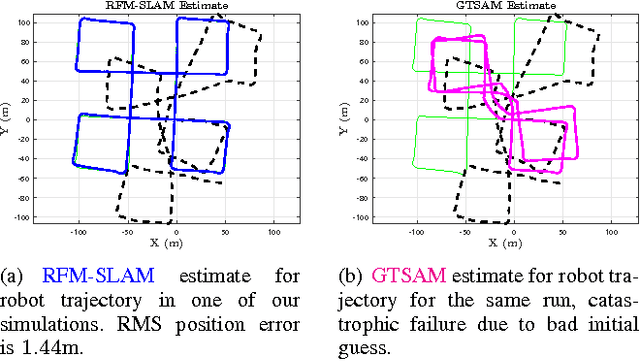
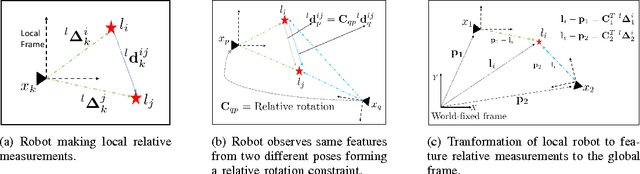

The SLAM problem is known to have a special property that when robot orientation is known, estimating the history of robot poses and feature locations can be posed as a standard linear least squares problem. In this work, we develop a SLAM framework that uses relative feature-to-feature measurements to exploit this structural property of SLAM. Relative feature measurements are used to pose a linear estimation problem for pose-to-pose orientation constraints. This is followed by solving an iterative non-linear on-manifold optimization problem to compute the maximum likelihood estimate for robot orientation given relative rotation constraints. Once the robot orientation is computed, we solve a linear problem for robot position and map estimation. Our approach reduces the computational burden of non-linear optimization by posing a smaller optimization problem as compared to standard graph-based methods for feature-based SLAM. Further, empirical results show our method avoids catastrophic failures that arise in existing methods due to using odometery as an initial guess for non-linear optimization, while its accuracy degrades gracefully as sensor noise is increased. We demonstrate our method through extensive simulations and comparisons with an existing state-of-the-art solver.