 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLDLS: 3-D Object Segmentation Through Label Diffusion From 2-D Images
Paper and Code

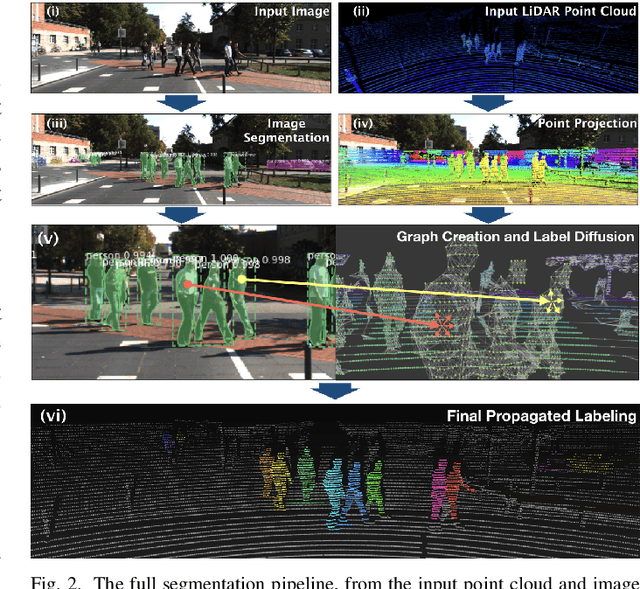
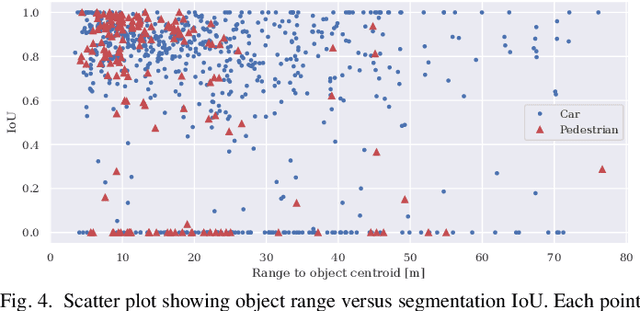
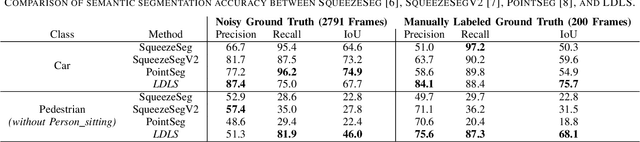
Object segmentation in three-dimensional (3-D) point clouds is a critical task for robots capable of 3-D perception. Despite the impressive performance of deep learning-based approaches on object segmentation in 2-D images, deep learning has not been applied nearly as successfully for 3-D point cloud segmentation. Deep networks generally require large amounts of labeled training data, which are readily available for 2-D images but are difficult to produce for 3-D point clouds. In this letter, we present Label Diffusion Lidar Segmentation (LDLS), a novel approach for 3-D point cloud segmentation, which leverages 2-D segmentation of an RGB image from an aligned camera to avoid the need for training on annotated 3-D data. We obtain 2-D segmentation predictions by applying Mask-RCNN to the RGB image, and then link this image to a 3-D lidar point cloud by building a graph of connections among 3-D points and 2-D pixels. This graph then directs a semi-supervised label diffusion process, where the 2-D pixels act as source nodes that diffuse object label information through the 3-D point cloud, resulting in a complete 3-D point cloud segmentation. We conduct empirical studies on the KITTI benchmark dataset and on a mobile robot, demonstrating wide applicability and superior performance of LDLS compared with the previous state of the art in 3-D point cloud segmentation, without any need for either 3-D training data or fine tuning of the 2-D image segmentation model.