 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMRD: Using Physically Based Differentiable Rendering to Probe Vision Models for 3D Scene Understanding
Dec 13, 2025While deep learning methods have achieved impressive success in many vision benchmarks, it remains difficult to understand and explain the representations and decisions of these models. Though vision models are typically trained on 2D inputs, they are often assumed to develop an implicit representation of the underlying 3D scene (for example, showing tolerance to partial occlusion, or the ability to reason about relative depth). Here, we introduce MRD (metamers rendered differentiably), an approach that uses physically based differentiable rendering to probe vision models' implicit understanding of generative 3D scene properties, by finding 3D scene parameters that are physically different but produce the same model activation (i.e. are model metamers). Unlike previous pixel-based methods for evaluating model representations, these reconstruction results are always grounded in physical scene descriptions. This means we can, for example, probe a model's sensitivity to object shape while holding material and lighting constant. As a proof-of-principle, we assess multiple models in their ability to recover scene parameters of geometry (shape) and bidirectional reflectance distribution function (material). The results show high similarity in model activation between target and optimized scenes, with varying visual results. Qualitatively, these reconstructions help investigate the physical scene attributes to which models are sensitive or invariant. MRD holds promise for advancing our understanding of both computer and human vision by enabling analysis of how physical scene parameters drive changes in model responses.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jun 30, 2022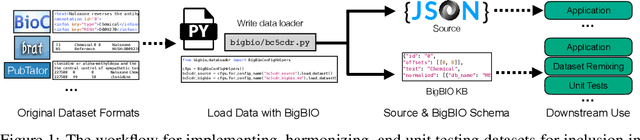
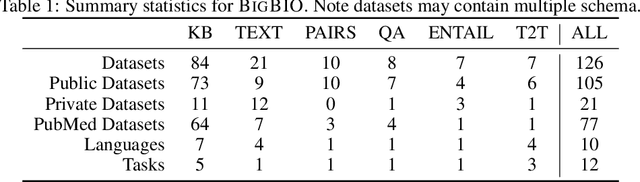

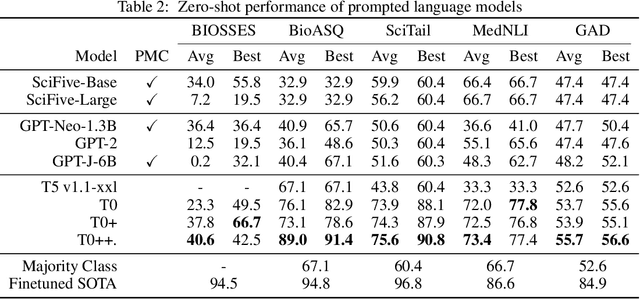
Training and evaluating language models increasingly requires the construction of meta-datasets --diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a diversity of novel pretraining tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBIO a community library of 126+ biomedical NLP datasets, currently covering 12 task categories and 10+ languages. BigBIO facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBIO is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical
LibriVoxDeEn: A Corpus for German-to-English Speech Translation and Speech Recognition
Oct 18, 2019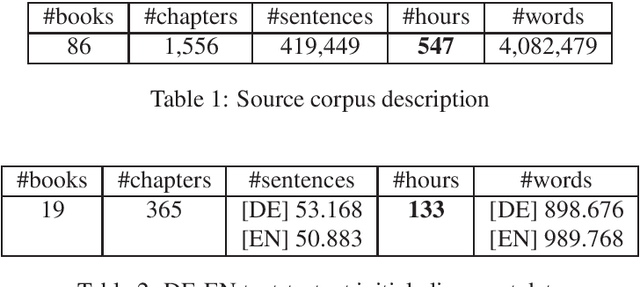



We present a corpus of sentence-aligned triples of German audio, German text, and English translation, based on German audio books. The corpus consists of over 100 hours of audio material and over 50k parallel sentences. The audio data is read speech and thus low in disfluencies. The quality of audio and sentence alignments has been checked by a manual evaluation, showing that speech alignment quality is in general very high. The sentence alignment quality is comparable to well-used parallel translation data and can be adjusted by cutoffs on the automatic alignment score. To our knowledge, this corpus is to date the largest resource for end-to-end speech translation for German.