 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeODBO: Bayesian Optimization with Search Space Prescreening for Directed Protein Evolution
May 20, 2022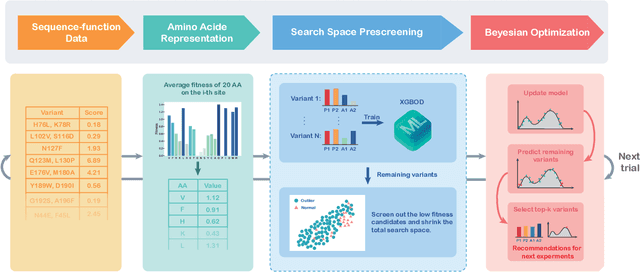
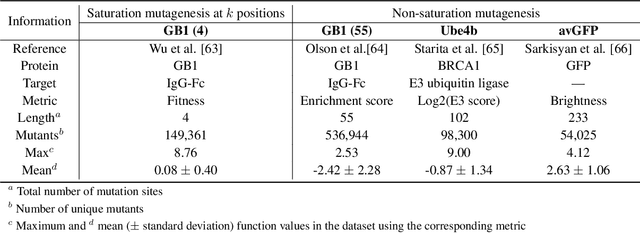
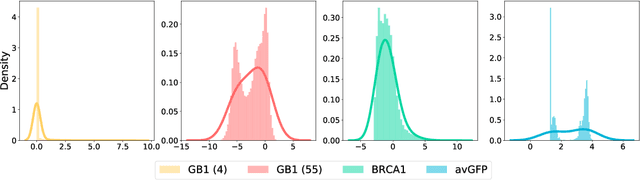

Directed evolution is a versatile technique in protein engineering that mimics the process of natural selection by iteratively alternating between mutagenesis and screening in order to search for sequences that optimize a given property of interest, such as catalytic activity and binding affinity to a specified target. However, the space of possible proteins is too large to search exhaustively in the laboratory, and functional proteins are scarce in the vast sequence space. Machine learning (ML) approaches can accelerate directed evolution by learning to map protein sequences to functions without building a detailed model of the underlying physics, chemistry and biological pathways. Despite the great potentials held by these ML methods, they encounter severe challenges in identifying the most suitable sequences for a targeted function. These failures can be attributed to the common practice of adopting a high-dimensional feature representation for protein sequences and inefficient search methods. To address these issues, we propose an efficient, experimental design-oriented closed-loop optimization framework for protein directed evolution, termed ODBO, which employs a combination of novel low-dimensional protein encoding strategy and Bayesian optimization enhanced with search space prescreening via outlier detection. We further design an initial sample selection strategy to minimize the number of experimental samples for training ML models. We conduct and report four protein directed evolution experiments that substantiate the capability of the proposed framework for finding of the variants with properties of interest. We expect the ODBO framework to greatly reduce the experimental cost and time cost of directed evolution, and can be further generalized as a powerful tool for adaptive experimental design in a broader context.
Retroformer: Pushing the Limits of Interpretable End-to-end Retrosynthesis Transformer
Jan 29, 2022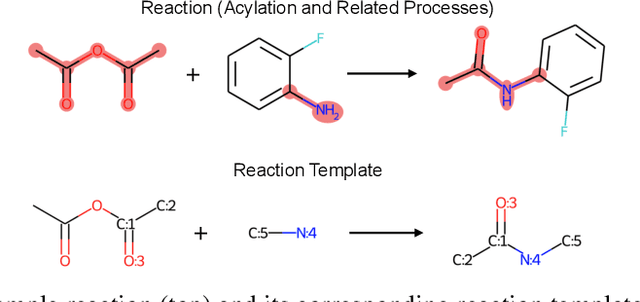
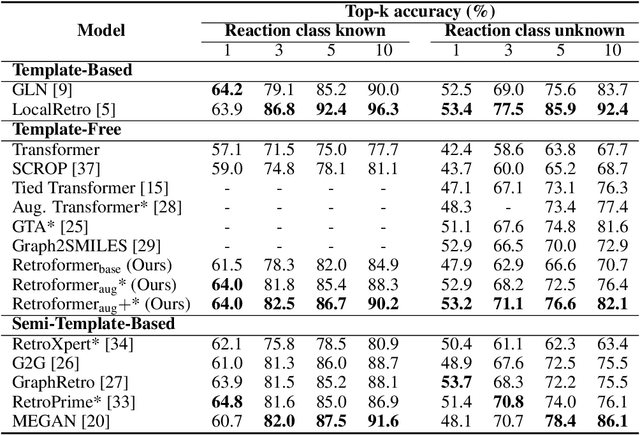
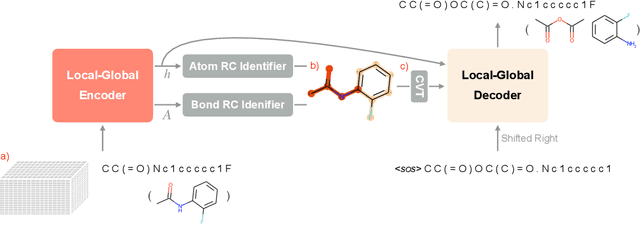
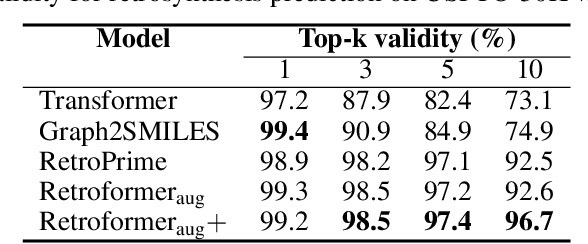
Retrosynthesis prediction is one of the fundamental challenges in organic synthesis. The task is to predict the reactants given a core product. With the advancement of machine learning, computer-aided synthesis planning has gained increasing interest. Numerous methods were proposed to solve this problem with different levels of dependency on additional chemical knowledge. In this paper, we propose Retroformer, a novel Transformer-based architecture for retrosynthesis prediction without relying on any cheminformatics tools for molecule editing. Via the proposed local attention head, the model can jointly encode the molecular sequence and graph, and efficiently exchange information between the local reactive region and the global reaction context. Retroformer reaches the new state-of-the-art accuracy for the end-to-end template-free retrosynthesis, and improves over many strong baselines on better molecule and reaction validity. In addition, its generative procedure is highly interpretable and controllable. Overall, Retroformer pushes the limits of the reaction reasoning ability of deep generative models.
Wasserstein Collaborative Filtering for Item Cold-start Recommendation
Sep 10, 2019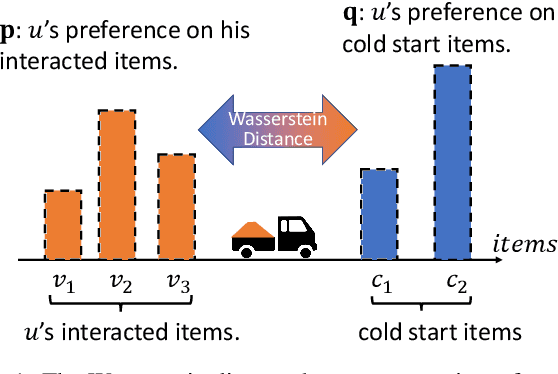
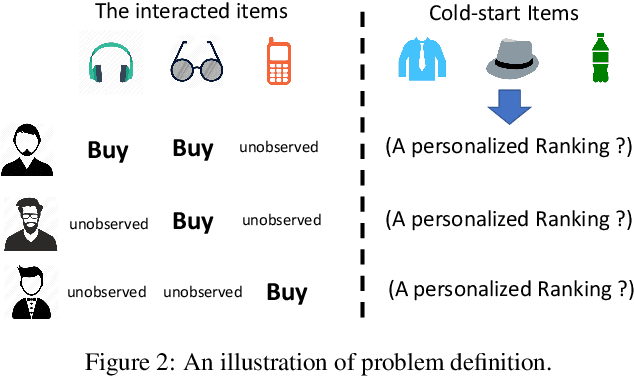
The item cold-start problem seriously limits the recommendation performance of Collaborative Filtering (CF) methods when new items have either none or very little interactions. To solve this issue, many modern Internet applications propose to predict a new item's interaction from the possessing contents. However, it is difficult to design and learn a map between the item's interaction history and the corresponding contents. In this paper, we apply the Wasserstein distance to address the item cold-start problem. Given item content information, we can calculate the similarity between the interacted items and cold-start ones, so that a user's preference on cold-start items can be inferred by minimizing the Wasserstein distance between the distributions over these two types of items. We further adopt the idea of CF and propose Wasserstein CF (WCF) to improve the recommendation performance on cold-start items. Experimental results demonstrate the superiority of WCF over state-of-the-art approaches.
PMD: A New User Distance for Recommender Systems
Sep 10, 2019
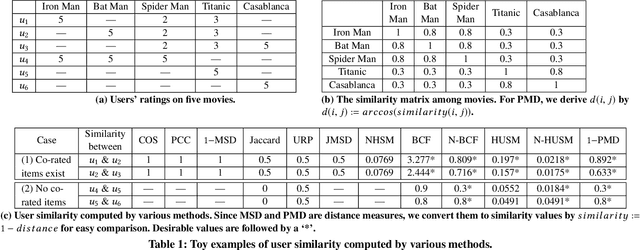


Collaborative filtering, a widely-used recommendation technique, predicts a user's preference by aggregating the ratings from similar users. As a result, these measures cannot fully utilize the rating information and are not suitable for real world sparse data. To solve these issues, we propose a novel user distance measure named Preference Mover's Distance (PMD) which makes full use of all ratings made by each user. Our proposed PMD can properly measure the distance between a pair of users even if they have no co-rated items. We show that this measure can be cast as an instance of the Earth Mover's Distance, a well-studied transportation problem for which several highly efficient solvers have been developed. Experimental results show that PMD can help achieve superior recommendation accuracy than state-of-the-art methods, especially when training data is very sparse.
Alchemy: A Quantum Chemistry Dataset for Benchmarking AI Models
Jun 22, 2019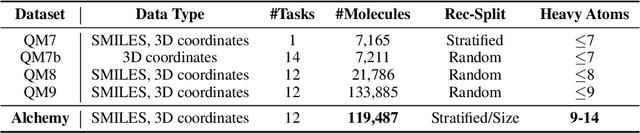
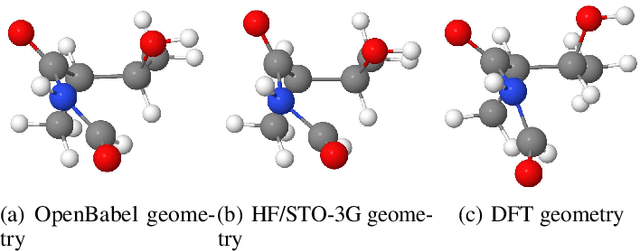
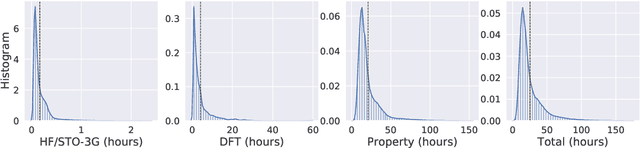
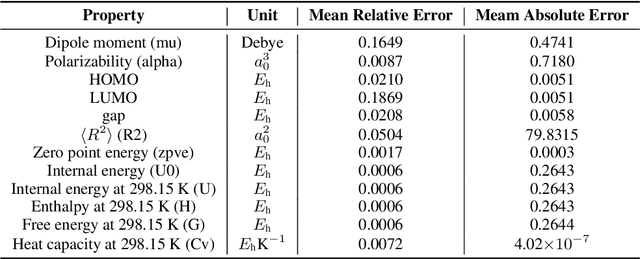
We introduce a new molecular dataset, named Alchemy, for developing machine learning models useful in chemistry and material science. As of June 20th 2019, the dataset comprises of 12 quantum mechanical properties of 119,487 organic molecules with up to 14 heavy atoms, sampled from the GDB MedChem database. The Alchemy dataset expands the volume and diversity of existing molecular datasets. Our extensive benchmarks of the state-of-the-art graph neural network models on Alchemy clearly manifest the usefulness of new data in validating and developing machine learning models for chemistry and material science. We further launch a contest to attract attentions from researchers in the related fields. More details can be found on the contest website \footnote{https://alchemy.tencent.com}. At the time of benchamrking experiment, we have generated 119,487 molecules in our Alchemy dataset. More molecular samples are generated since then. Hence, we provide a list of molecules used in the reported benchmarks.
A Meta Approach to Defend Noisy Labels by the Manifold Regularizer PSDR
Jun 13, 2019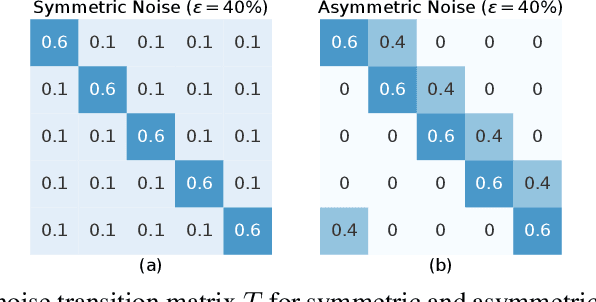
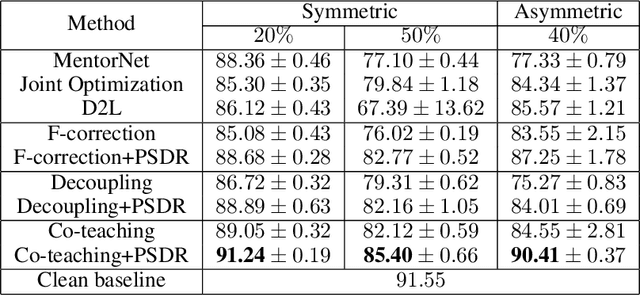
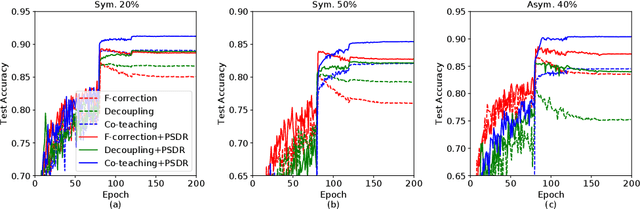
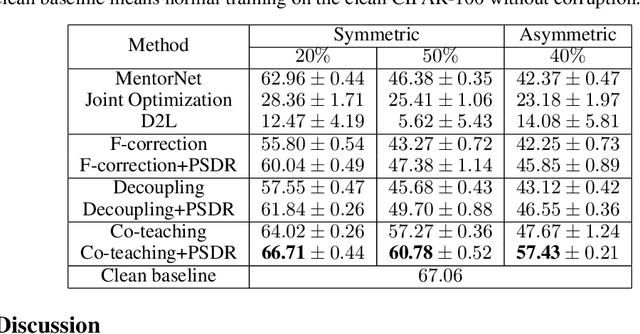
Noisy labels are ubiquitous in real-world datasets, which poses a challenge for robustly training deep neural networks (DNNs) since DNNs can easily overfit to the noisy labels. Most recent efforts have been devoted to defending noisy labels by discarding noisy samples from the training set or assigning weights to training samples, where the weight associated with a noisy sample is expected to be small. Thereby, these previous efforts result in a waste of samples, especially those assigned with small weights. The input $x$ is always useful regardless of whether its observed label $y$ is clean. To make full use of all samples, we introduce a manifold regularizer, named as Paired Softmax Divergence Regularization (PSDR), to penalize the Kullback-Leibler (KL) divergence between softmax outputs of similar inputs. In particular, similar inputs can be effectively generated by data augmentation. PSDR can be easily implemented on any type of DNNs to improve the robustness against noisy labels. As empirically demonstrated on benchmark datasets, our PSDR impressively improve state-of-the-art results by a significant margin.
Understanding Adversarial Behavior of DNNs by Disentangling Non-Robust and Robust Components in Performance Metric
Jun 06, 2019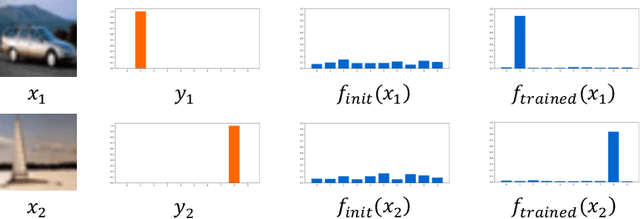

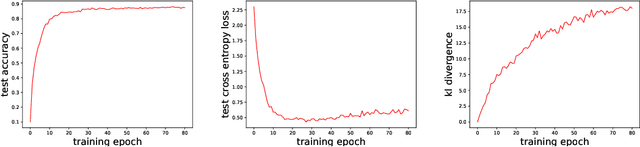
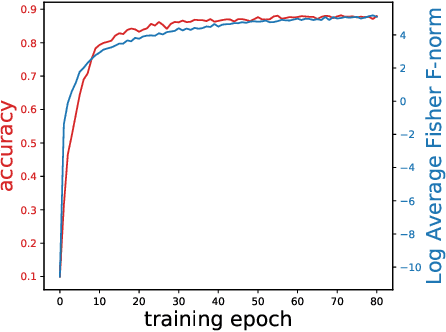
The vulnerability to slight input perturbations is a worrying yet intriguing property of deep neural networks (DNNs). Despite many previous works studying the reason behind such adversarial behavior, the relationship between the generalization performance and adversarial behavior of DNNs is still little understood. In this work, we reveal such relation by introducing a metric characterizing the generalization performance of a DNN. The metric can be disentangled into an information-theoretic non-robust component, responsible for adversarial behavior, and a robust component. Then, we show by experiments that current DNNs rely heavily on optimizing the non-robust component in achieving decent performance. We also demonstrate that current state-of-the-art adversarial training algorithms indeed try to robustify the DNNs by preventing them from using the non-robust component to distinguish samples from different categories. Also, based on our findings, we take a step forward and point out the possible direction for achieving decent standard performance and adversarial robustness simultaneously. We believe that our theory could further inspire the community to make more interesting discoveries about the relationship between standard generalization and adversarial generalization of deep learning models.
Rethinking the Usage of Batch Normalization and Dropout in the Training of Deep Neural Networks
May 15, 2019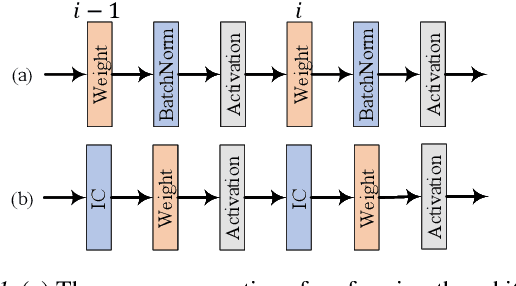
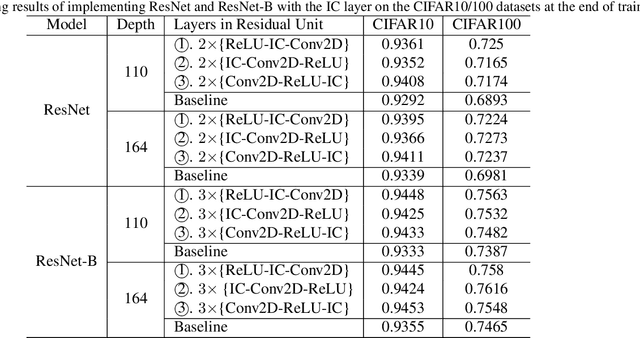

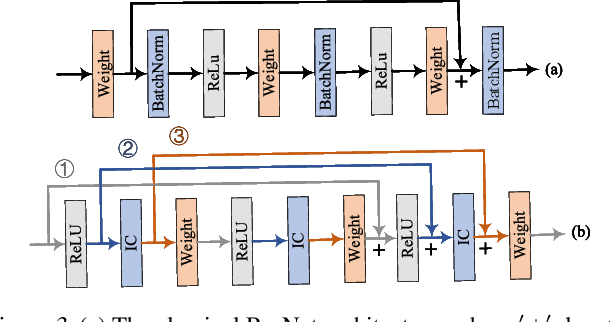
In this work, we propose a novel technique to boost training efficiency of a neural network. Our work is based on an excellent idea that whitening the inputs of neural networks can achieve a fast convergence speed. Given the well-known fact that independent components must be whitened, we introduce a novel Independent-Component (IC) layer before each weight layer, whose inputs would be made more independent. However, determining independent components is a computationally intensive task. To overcome this challenge, we propose to implement an IC layer by combining two popular techniques, Batch Normalization and Dropout, in a new manner that we can rigorously prove that Dropout can quadratically reduce the mutual information and linearly reduce the correlation between any pair of neurons with respect to the dropout layer parameter $p$. As demonstrated experimentally, the IC layer consistently outperforms the baseline approaches with more stable training process, faster convergence speed and better convergence limit on CIFAR10/100 and ILSVRC2012 datasets. The implementation of our IC layer makes us rethink the common practices in the design of neural networks. For example, we should not place Batch Normalization before ReLU since the non-negative responses of ReLU will make the weight layer updated in a suboptimal way, and we can achieve better performance by combining Batch Normalization and Dropout together as an IC layer.
Understanding and Utilizing Deep Neural Networks Trained with Noisy Labels
May 13, 2019
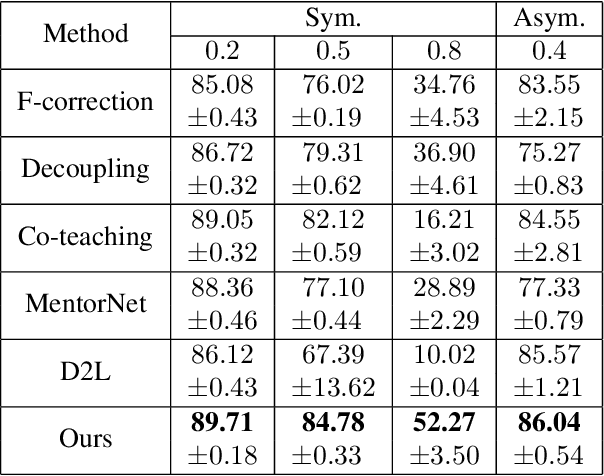
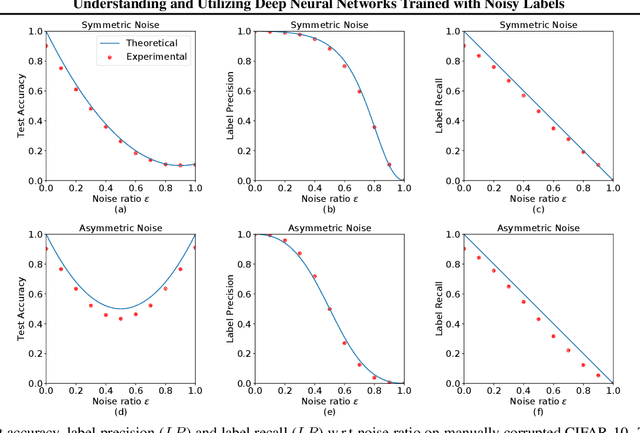
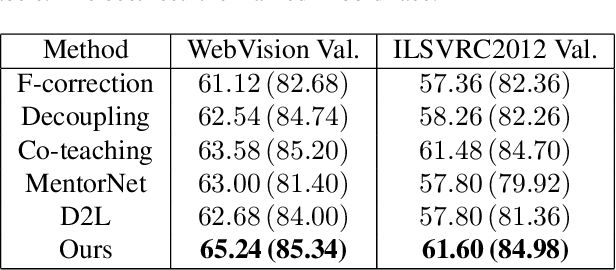
Noisy labels are ubiquitous in real-world datasets, which poses a challenge for robustly training deep neural networks (DNNs) as DNNs usually have the high capacity to memorize the noisy labels. In this paper, we find that the test accuracy can be quantitatively characterized in terms of the noise ratio in datasets. In particular, the test accuracy is a quadratic function of the noise ratio in the case of symmetric noise, which explains the experimental findings previously published. Based on our analysis, we apply cross-validation to randomly split noisy datasets, which identifies most samples that have correct labels. Then we adopt the Co-teaching strategy which takes full advantage of the identified samples to train DNNs robustly against noisy labels. Compared with extensive state-of-the-art methods, our strategy consistently improves the generalization performance of DNNs under both synthetic and real-world training noise.