 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Adversarial Behavior of DNNs by Disentangling Non-Robust and Robust Components in Performance Metric
Paper and Code
Jun 06, 2019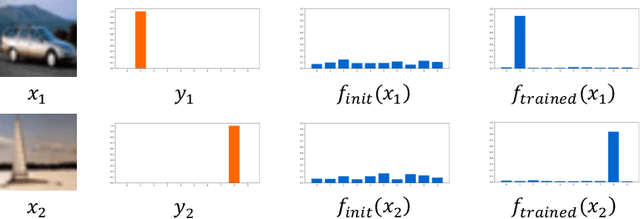

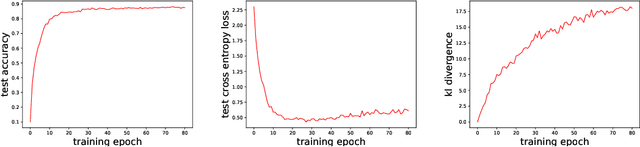
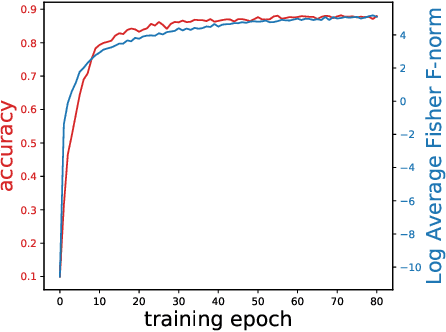
The vulnerability to slight input perturbations is a worrying yet intriguing property of deep neural networks (DNNs). Despite many previous works studying the reason behind such adversarial behavior, the relationship between the generalization performance and adversarial behavior of DNNs is still little understood. In this work, we reveal such relation by introducing a metric characterizing the generalization performance of a DNN. The metric can be disentangled into an information-theoretic non-robust component, responsible for adversarial behavior, and a robust component. Then, we show by experiments that current DNNs rely heavily on optimizing the non-robust component in achieving decent performance. We also demonstrate that current state-of-the-art adversarial training algorithms indeed try to robustify the DNNs by preventing them from using the non-robust component to distinguish samples from different categories. Also, based on our findings, we take a step forward and point out the possible direction for achieving decent standard performance and adversarial robustness simultaneously. We believe that our theory could further inspire the community to make more interesting discoveries about the relationship between standard generalization and adversarial generalization of deep learning models.