 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction Classification and Highlighting in Videos
Aug 31, 2017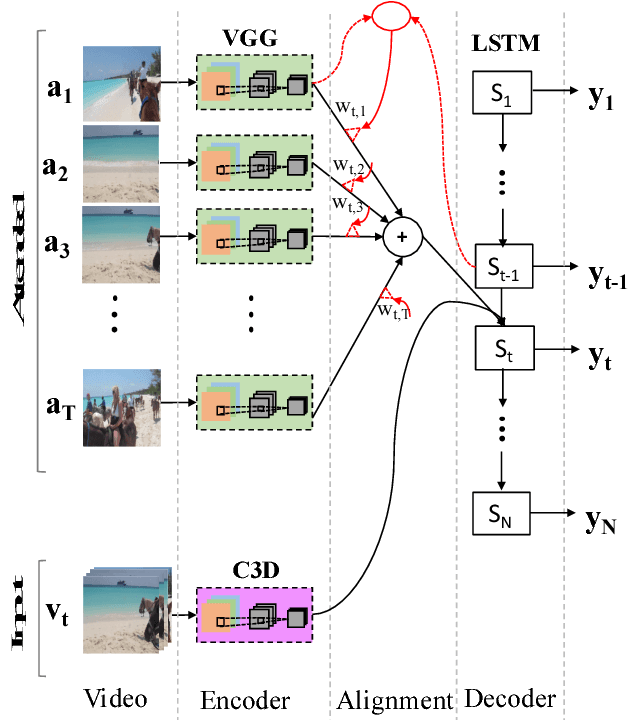
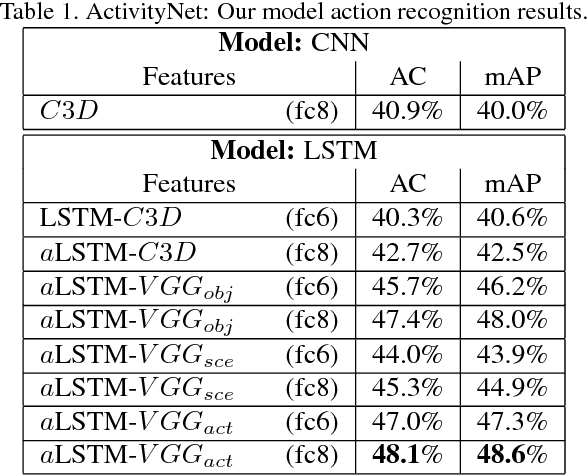

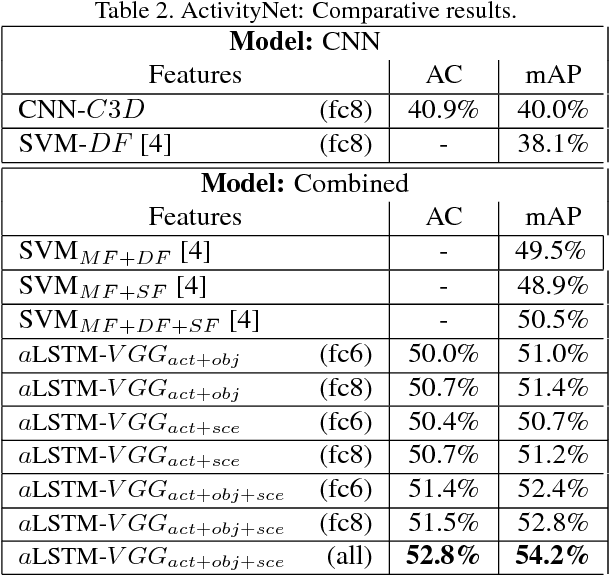
Inspired by recent advances in neural machine translation, that jointly align and translate using encoder-decoder networks equipped with attention, we propose an attentionbased LSTM model for human activity recognition. Our model jointly learns to classify actions and highlight frames associated with the action, by attending to salient visual information through a jointly learned soft-attention networks. We explore attention informed by various forms of visual semantic features, including those encoding actions, objects and scenes. We qualitatively show that soft-attention can learn to effectively attend to important objects and scene information correlated with specific human actions. Further, we show that, quantitatively, our attention-based LSTM outperforms the vanilla LSTM and CNN models used by stateof-the-art methods. On a large-scale youtube video dataset, ActivityNet, our model outperforms competing methods in action classification.
Learning Language-Visual Embedding for Movie Understanding with Natural-Language
Sep 26, 2016
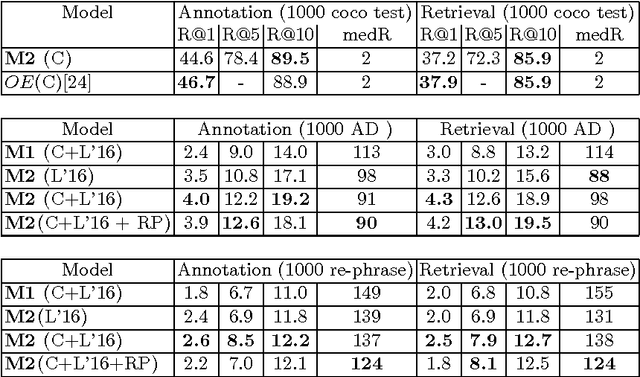


Learning a joint language-visual embedding has a number of very appealing properties and can result in variety of practical application, including natural language image/video annotation and search. In this work, we study three different joint language-visual neural network model architectures. We evaluate our models on large scale LSMDC16 movie dataset for two tasks: 1) Standard Ranking for video annotation and retrieval 2) Our proposed movie multiple-choice test. This test facilitate automatic evaluation of visual-language models for natural language video annotation based on human activities. In addition to original Audio Description (AD) captions, provided as part of LSMDC16, we collected and will make available a) manually generated re-phrasings of those captions obtained using Amazon MTurk b) automatically generated human activity elements in "Predicate + Object" (PO) phrases based on "Knowlywood", an activity knowledge mining model. Our best model archives Recall@10 of 19.2% on annotation and 18.9% on video retrieval tasks for subset of 1000 samples. For multiple-choice test, our best model achieve accuracy 58.11% over whole LSMDC16 public test-set.
Movie Description
May 12, 2016
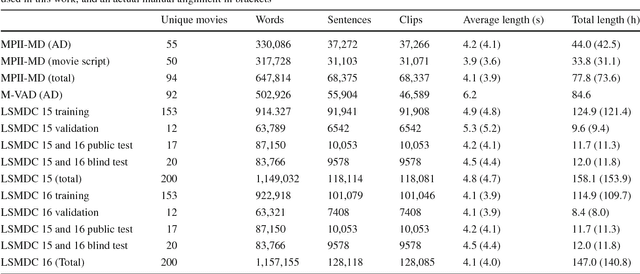

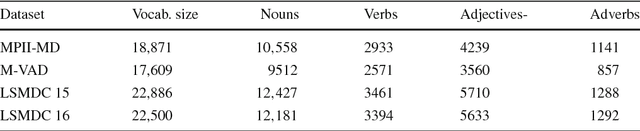
Audio Description (AD) provides linguistic descriptions of movies and allows visually impaired people to follow a movie along with their peers. Such descriptions are by design mainly visual and thus naturally form an interesting data source for computer vision and computational linguistics. In this work we propose a novel dataset which contains transcribed ADs, which are temporally aligned to full length movies. In addition we also collected and aligned movie scripts used in prior work and compare the two sources of descriptions. In total the Large Scale Movie Description Challenge (LSMDC) contains a parallel corpus of 118,114 sentences and video clips from 202 movies. First we characterize the dataset by benchmarking different approaches for generating video descriptions. Comparing ADs to scripts, we find that ADs are indeed more visual and describe precisely what is shown rather than what should happen according to the scripts created prior to movie production. Furthermore, we present and compare the results of several teams who participated in a challenge organized in the context of the workshop "Describing and Understanding Video & The Large Scale Movie Description Challenge (LSMDC)", at ICCV 2015.
Describing Videos by Exploiting Temporal Structure
Oct 01, 2015
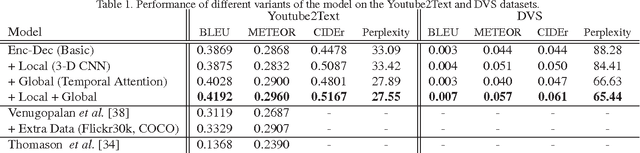
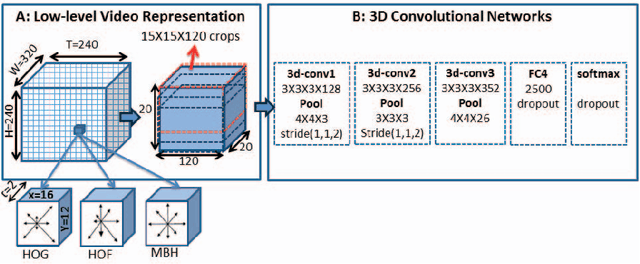
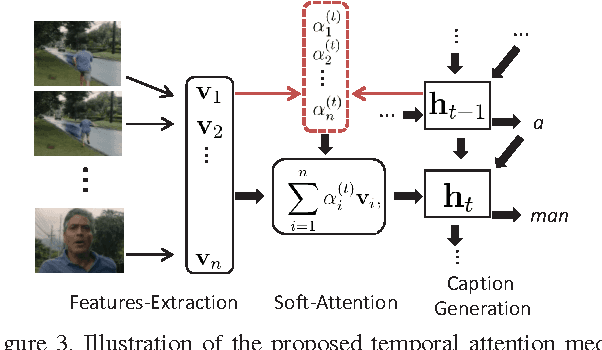
Recent progress in using recurrent neural networks (RNNs) for image description has motivated the exploration of their application for video description. However, while images are static, working with videos requires modeling their dynamic temporal structure and then properly integrating that information into a natural language description. In this context, we propose an approach that successfully takes into account both the local and global temporal structure of videos to produce descriptions. First, our approach incorporates a spatial temporal 3-D convolutional neural network (3-D CNN) representation of the short temporal dynamics. The 3-D CNN representation is trained on video action recognition tasks, so as to produce a representation that is tuned to human motion and behavior. Second we propose a temporal attention mechanism that allows to go beyond local temporal modeling and learns to automatically select the most relevant temporal segments given the text-generating RNN. Our approach exceeds the current state-of-art for both BLEU and METEOR metrics on the Youtube2Text dataset. We also present results on a new, larger and more challenging dataset of paired video and natural language descriptions.
Using Descriptive Video Services to Create a Large Data Source for Video Annotation Research
Mar 03, 2015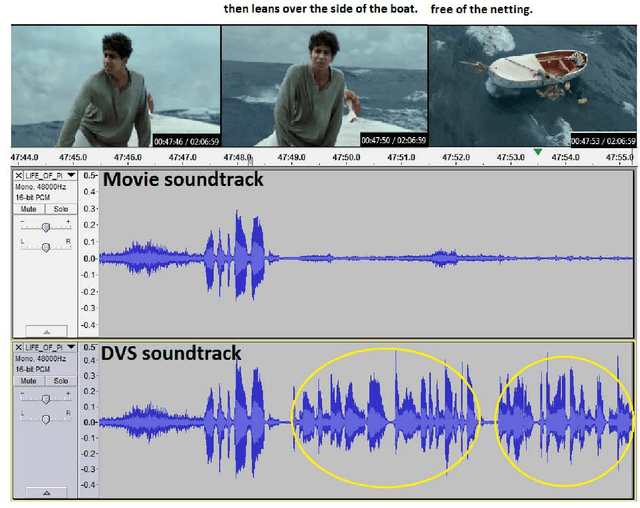

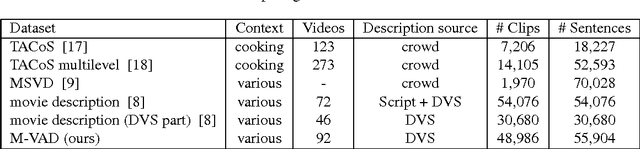
In this work, we introduce a dataset of video annotated with high quality natural language phrases describing the visual content in a given segment of time. Our dataset is based on the Descriptive Video Service (DVS) that is now encoded on many digital media products such as DVDs. DVS is an audio narration describing the visual elements and actions in a movie for the visually impaired. It is temporally aligned with the movie and mixed with the original movie soundtrack. We describe an automatic DVS segmentation and alignment method for movies, that enables us to scale up the collection of a DVS-derived dataset with minimal human intervention. Using this method, we have collected the largest DVS-derived dataset for video description of which we are aware. Our dataset currently includes over 84.6 hours of paired video/sentences from 92 DVDs and is growing.
A Bag of Words Approach for Semantic Segmentation of Monitored Scenes
May 14, 2013
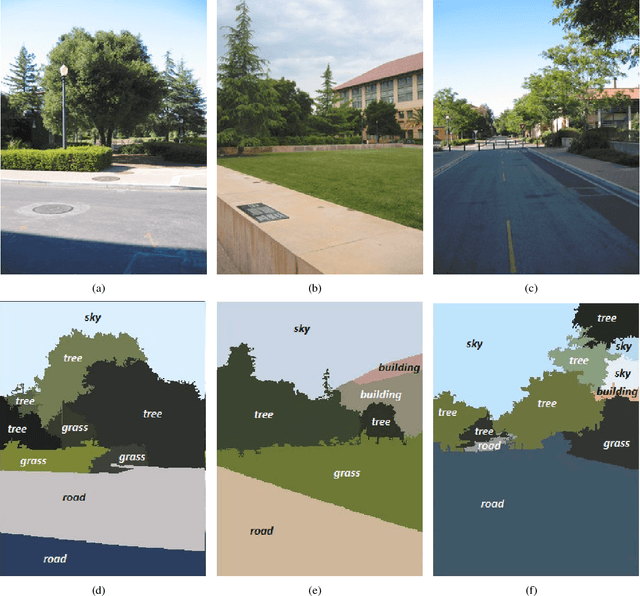
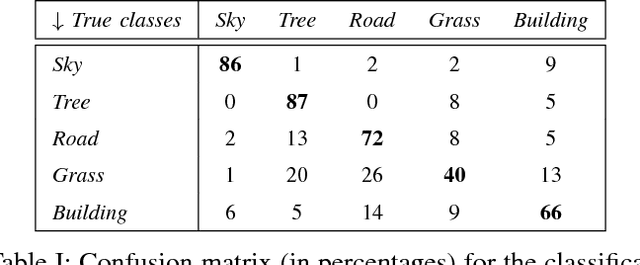
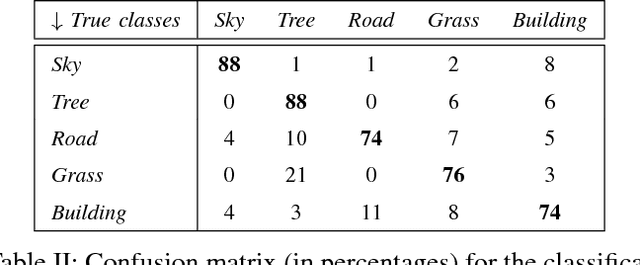
This paper proposes a semantic segmentation method for outdoor scenes captured by a surveillance camera. Our algorithm classifies each perceptually homogenous region as one of the predefined classes learned from a collection of manually labelled images. The proposed approach combines two different types of information. First, color segmentation is performed to divide the scene into perceptually similar regions. Then, the second step is based on SIFT keypoints and uses the bag of words representation of the regions for the classification. The prediction is done using a Na\"ive Bayesian Network as a generative classifier. Compared to existing techniques, our method provides more compact representations of scene contents and the segmentation result is more consistent with human perception due to the combination of the color information with the image keypoints. The experiments conducted on a publicly available data set demonstrate the validity of the proposed method.