 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMovie Description
Paper and Code

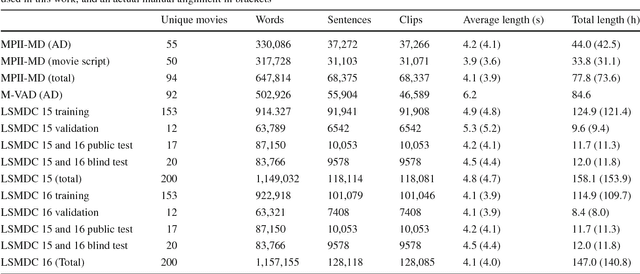

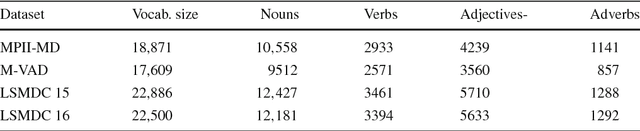
Audio Description (AD) provides linguistic descriptions of movies and allows visually impaired people to follow a movie along with their peers. Such descriptions are by design mainly visual and thus naturally form an interesting data source for computer vision and computational linguistics. In this work we propose a novel dataset which contains transcribed ADs, which are temporally aligned to full length movies. In addition we also collected and aligned movie scripts used in prior work and compare the two sources of descriptions. In total the Large Scale Movie Description Challenge (LSMDC) contains a parallel corpus of 118,114 sentences and video clips from 202 movies. First we characterize the dataset by benchmarking different approaches for generating video descriptions. Comparing ADs to scripts, we find that ADs are indeed more visual and describe precisely what is shown rather than what should happen according to the scripts created prior to movie production. Furthermore, we present and compare the results of several teams who participated in a challenge organized in the context of the workshop "Describing and Understanding Video & The Large Scale Movie Description Challenge (LSMDC)", at ICCV 2015.