 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bag of Words Approach for Semantic Segmentation of Monitored Scenes
Paper and Code
May 14, 2013
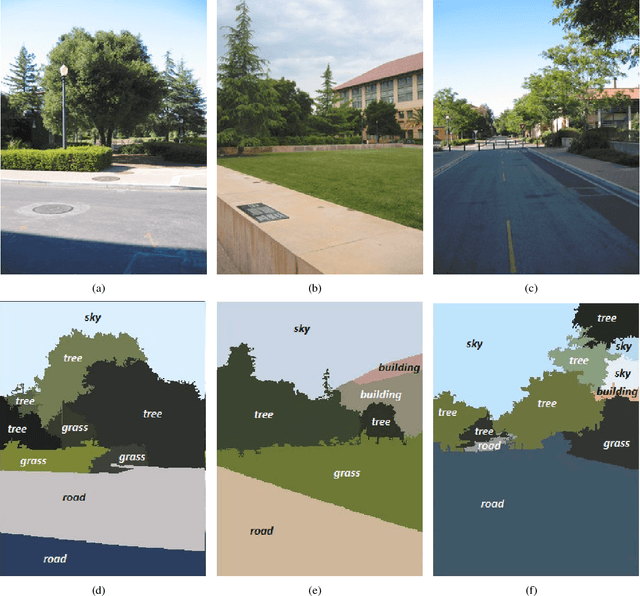
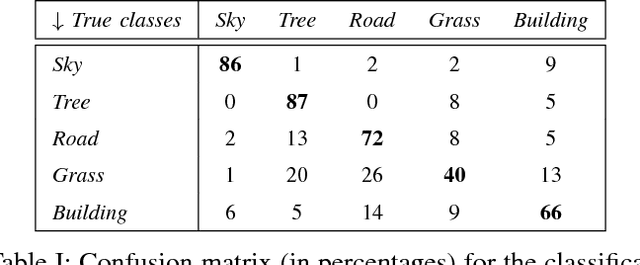
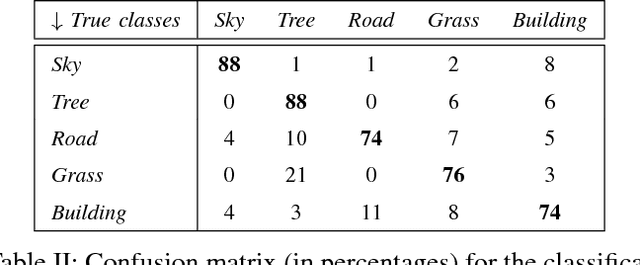
This paper proposes a semantic segmentation method for outdoor scenes captured by a surveillance camera. Our algorithm classifies each perceptually homogenous region as one of the predefined classes learned from a collection of manually labelled images. The proposed approach combines two different types of information. First, color segmentation is performed to divide the scene into perceptually similar regions. Then, the second step is based on SIFT keypoints and uses the bag of words representation of the regions for the classification. The prediction is done using a Na\"ive Bayesian Network as a generative classifier. Compared to existing techniques, our method provides more compact representations of scene contents and the segmentation result is more consistent with human perception due to the combination of the color information with the image keypoints. The experiments conducted on a publicly available data set demonstrate the validity of the proposed method.