 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Paper: Agent AI Towards a Holistic Intelligence
Feb 28, 2024Recent advancements in large foundation models have remarkably enhanced our understanding of sensory information in open-world environments. In leveraging the power of foundation models, it is crucial for AI research to pivot away from excessive reductionism and toward an emphasis on systems that function as cohesive wholes. Specifically, we emphasize developing Agent AI -- an embodied system that integrates large foundation models into agent actions. The emerging field of Agent AI spans a wide range of existing embodied and agent-based multimodal interactions, including robotics, gaming, and healthcare systems, etc. In this paper, we propose a novel large action model to achieve embodied intelligent behavior, the Agent Foundation Model. On top of this idea, we discuss how agent AI exhibits remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. Furthermore, we discuss the potential of Agent AI from an interdisciplinary perspective, underscoring AI cognition and consciousness within scientific discourse. We believe that those discussions serve as a basis for future research directions and encourage broader societal engagement.
An Interactive Agent Foundation Model
Feb 08, 2024



The development of artificial intelligence systems is transitioning from creating static, task-specific models to dynamic, agent-based systems capable of performing well in a wide range of applications. We propose an Interactive Agent Foundation Model that uses a novel multi-task agent training paradigm for training AI agents across a wide range of domains, datasets, and tasks. Our training paradigm unifies diverse pre-training strategies, including visual masked auto-encoders, language modeling, and next-action prediction, enabling a versatile and adaptable AI framework. We demonstrate the performance of our framework across three separate domains -- Robotics, Gaming AI, and Healthcare. Our model demonstrates its ability to generate meaningful and contextually relevant outputs in each area. The strength of our approach lies in its generality, leveraging a variety of data sources such as robotics sequences, gameplay data, large-scale video datasets, and textual information for effective multimodal and multi-task learning. Our approach provides a promising avenue for developing generalist, action-taking, multimodal systems.
A Risk-Sensitive Approach to Policy Optimization
Aug 19, 2022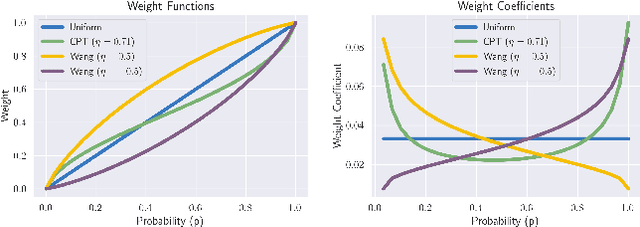
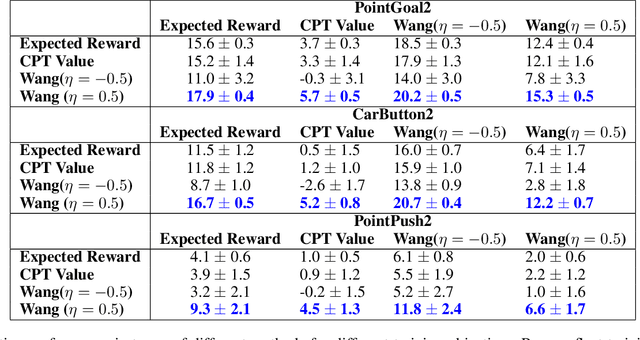
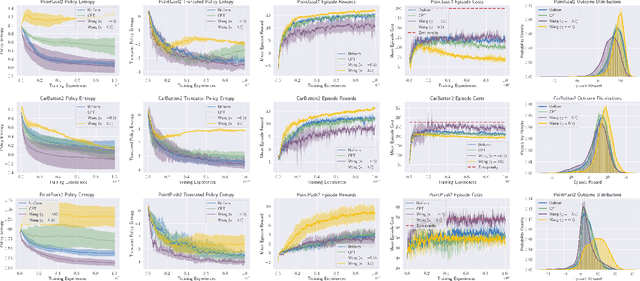
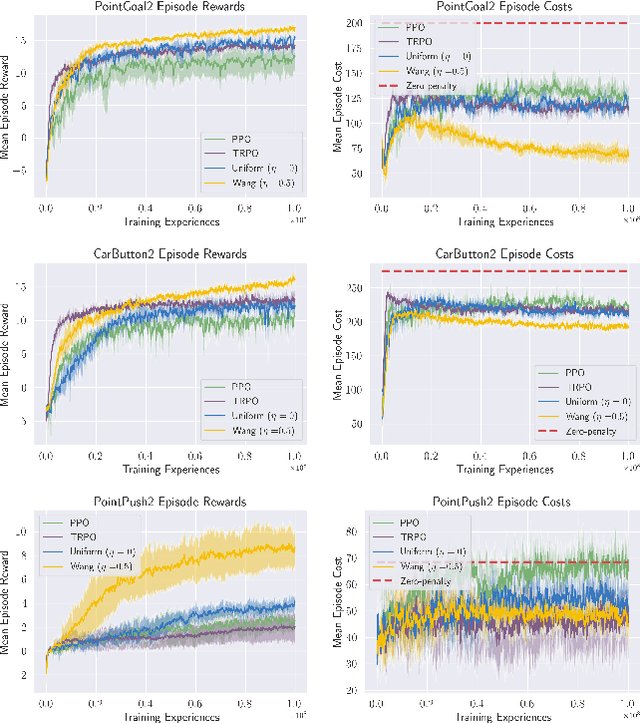
Standard deep reinforcement learning (DRL) aims to maximize expected reward, considering collected experiences equally in formulating a policy. This differs from human decision-making, where gains and losses are valued differently and outlying outcomes are given increased consideration. It also fails to capitalize on opportunities to improve safety and/or performance through the incorporation of distributional context. Several approaches to distributional DRL have been investigated, with one popular strategy being to evaluate the projected distribution of returns for possible actions. We propose a more direct approach whereby risk-sensitive objectives, specified in terms of the cumulative distribution function (CDF) of the distribution of full-episode rewards, are optimized. This approach allows for outcomes to be weighed based on relative quality, can be used for both continuous and discrete action spaces, and may naturally be applied in both constrained and unconstrained settings. We show how to compute an asymptotically consistent estimate of the policy gradient for a broad class of risk-sensitive objectives via sampling, subsequently incorporating variance reduction and regularization measures to facilitate effective on-policy learning. We then demonstrate that the use of moderately "pessimistic" risk profiles, which emphasize scenarios where the agent performs poorly, leads to enhanced exploration and a continual focus on addressing deficiencies. We test the approach using different risk profiles in six OpenAI Safety Gym environments, comparing to state of the art on-policy methods. Without cost constraints, we find that pessimistic risk profiles can be used to reduce cost while improving total reward accumulation. With cost constraints, they are seen to provide higher positive rewards than risk-neutral approaches at the prescribed allowable cost.
Assured Autonomy: Path Toward Living With Autonomous Systems We Can Trust
Oct 27, 2020The challenge of establishing assurance in autonomy is rapidly attracting increasing interest in the industry, government, and academia. Autonomy is a broad and expansive capability that enables systems to behave without direct control by a human operator. To that end, it is expected to be present in a wide variety of systems and applications. A vast range of industrial sectors, including (but by no means limited to) defense, mobility, health care, manufacturing, and civilian infrastructure, are embracing the opportunities in autonomy yet face the similar barriers toward establishing the necessary level of assurance sooner or later. Numerous government agencies are poised to tackle the challenges in assured autonomy. Given the already immense interest and investment in autonomy, a series of workshops on Assured Autonomy was convened to facilitate dialogs and increase awareness among the stakeholders in the academia, industry, and government. This series of three workshops aimed to help create a unified understanding of the goals for assured autonomy, the research trends and needs, and a strategy that will facilitate sustained progress in autonomy. The first workshop, held in October 2019, focused on current and anticipated challenges and problems in assuring autonomous systems within and across applications and sectors. The second workshop held in February 2020, focused on existing capabilities, current research, and research trends that could address the challenges and problems identified in workshop. The third event was dedicated to a discussion of a draft of the major findings from the previous two workshops and the recommendations.