 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Risk-Sensitive Approach to Policy Optimization
Paper and Code
Aug 19, 2022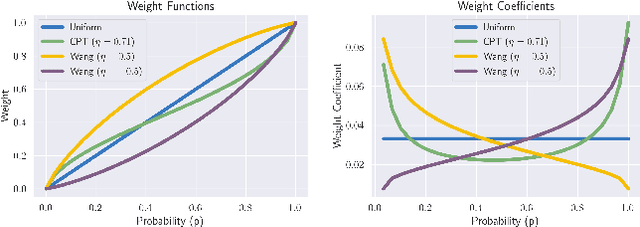
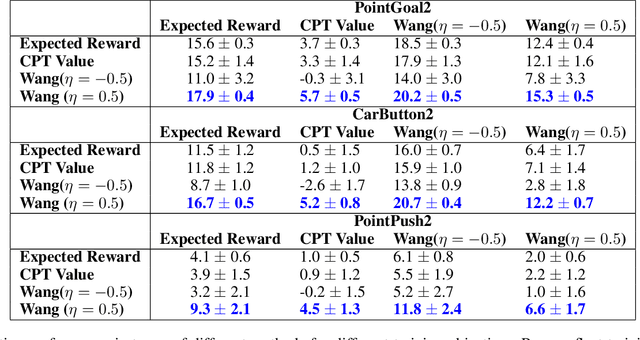
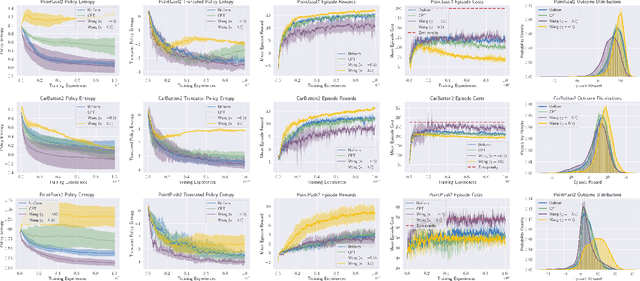
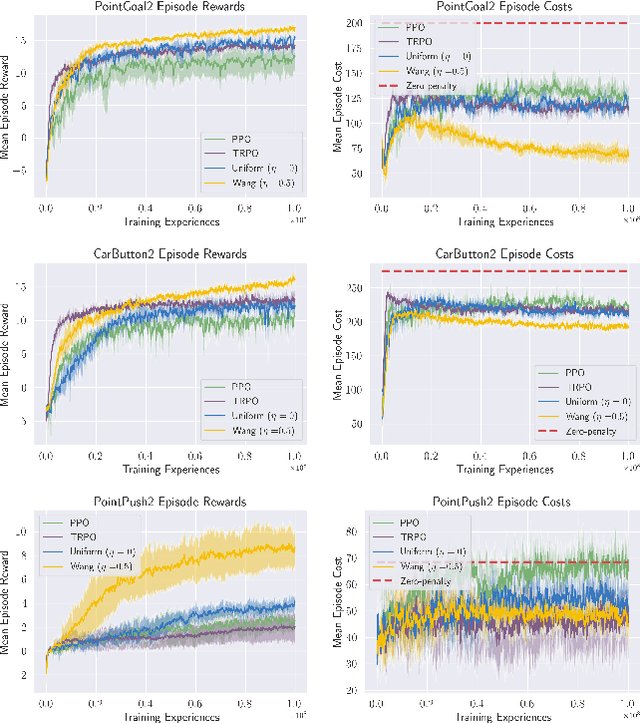
Standard deep reinforcement learning (DRL) aims to maximize expected reward, considering collected experiences equally in formulating a policy. This differs from human decision-making, where gains and losses are valued differently and outlying outcomes are given increased consideration. It also fails to capitalize on opportunities to improve safety and/or performance through the incorporation of distributional context. Several approaches to distributional DRL have been investigated, with one popular strategy being to evaluate the projected distribution of returns for possible actions. We propose a more direct approach whereby risk-sensitive objectives, specified in terms of the cumulative distribution function (CDF) of the distribution of full-episode rewards, are optimized. This approach allows for outcomes to be weighed based on relative quality, can be used for both continuous and discrete action spaces, and may naturally be applied in both constrained and unconstrained settings. We show how to compute an asymptotically consistent estimate of the policy gradient for a broad class of risk-sensitive objectives via sampling, subsequently incorporating variance reduction and regularization measures to facilitate effective on-policy learning. We then demonstrate that the use of moderately "pessimistic" risk profiles, which emphasize scenarios where the agent performs poorly, leads to enhanced exploration and a continual focus on addressing deficiencies. We test the approach using different risk profiles in six OpenAI Safety Gym environments, comparing to state of the art on-policy methods. Without cost constraints, we find that pessimistic risk profiles can be used to reduce cost while improving total reward accumulation. With cost constraints, they are seen to provide higher positive rewards than risk-neutral approaches at the prescribed allowable cost.