 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Skull Reconstruction in Brain CT Images with Decompressive Craniectomy
Jul 11, 2020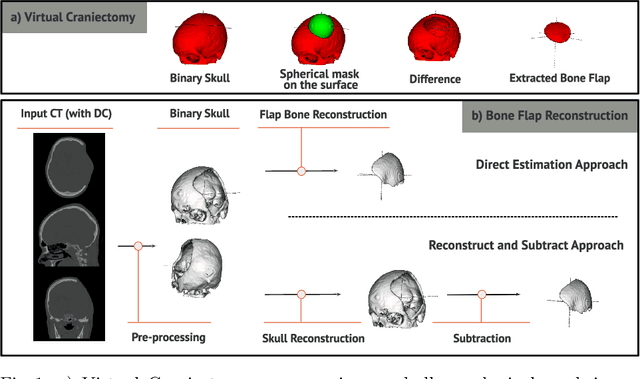
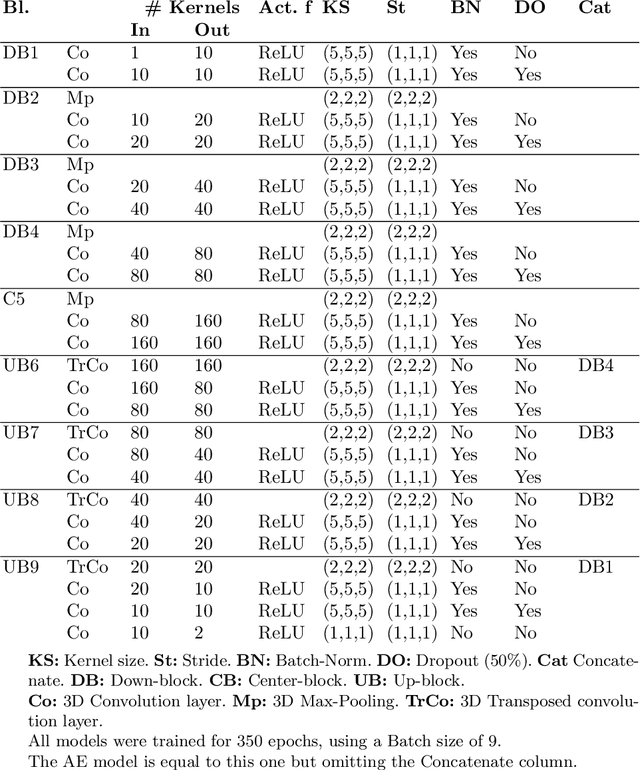
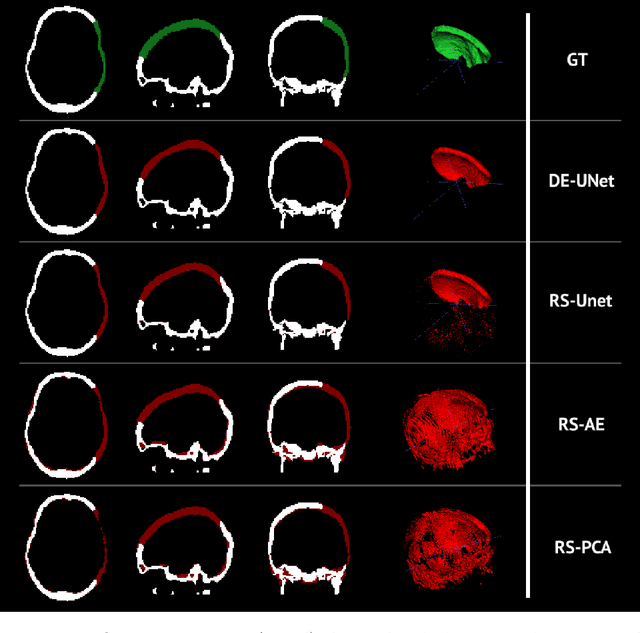
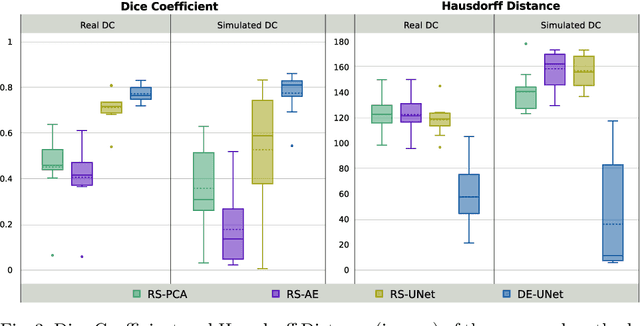
Decompressive craniectomy (DC) is a common surgical procedure consisting of the removal of a portion of the skull that is performed after incidents such as stroke, traumatic brain injury (TBI) or other events that could result in acute subdural hemorrhage and/or increasing intracranial pressure. In these cases, CT scans are obtained to diagnose and assess injuries, or guide a certain therapy and intervention. We propose a deep learning based method to reconstruct the skull defect removed during DC performed after TBI from post-operative CT images. This reconstruction is useful in multiple scenarios, e.g. to support the creation of cranioplasty plates, accurate measurements of bone flap volume and total intracranial volume, important for studies that aim to relate later atrophy to patient outcome. We propose and compare alternative self-supervised methods where an encoder-decoder convolutional neural network (CNN) estimates the missing bone flap on post-operative CTs. The self-supervised learning strategy only requires images with complete skulls and avoids the need for annotated DC images. For evaluation, we employ real and simulated images with DC, comparing the results with other state-of-the-art approaches. The experiments show that the proposed model outperforms current manual methods, enabling reconstruction even in highly challenging cases where big skull defects have been removed during surgery.
Tensor-Dictionary Learning with Deep Kruskal-Factor Analysis
Mar 05, 2017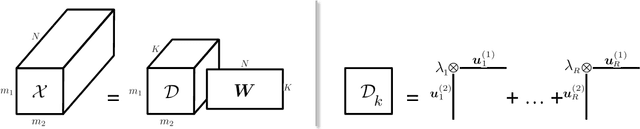
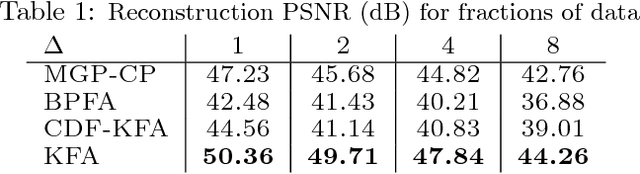
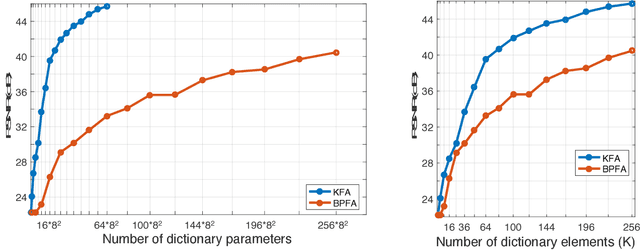
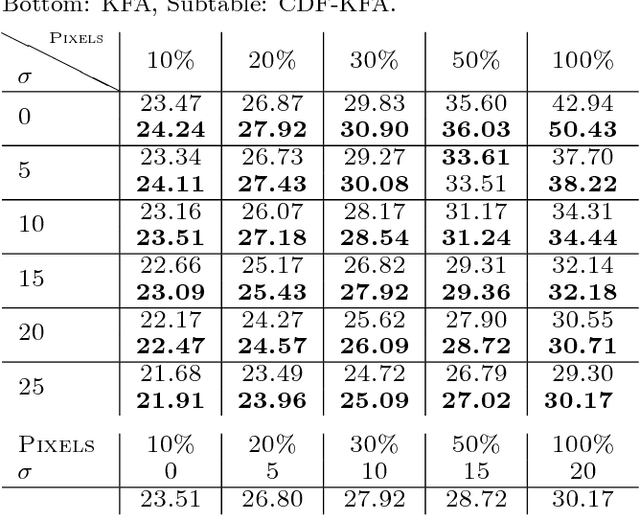
A multi-way factor analysis model is introduced for tensor-variate data of any order. Each data item is represented as a (sparse) sum of Kruskal decompositions, a Kruskal-factor analysis (KFA). KFA is nonparametric and can infer both the tensor-rank of each dictionary atom and the number of dictionary atoms. The model is adapted for online learning, which allows dictionary learning on large data sets. After KFA is introduced, the model is extended to a deep convolutional tensor-factor analysis, supervised by a Bayesian SVM. The experiments section demonstrates the improvement of KFA over vectorized approaches (e.g., BPFA), tensor decompositions, and convolutional neural networks (CNN) in multi-way denoising, blind inpainting, and image classification. The improvement in PSNR for the inpainting results over other methods exceeds 1dB in several cases and we achieve state of the art results on Caltech101 image classification.
Variational Autoencoder for Deep Learning of Images, Labels and Captions
Sep 28, 2016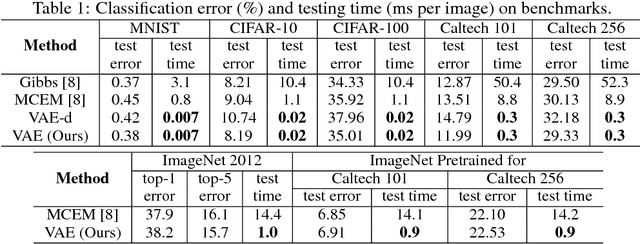
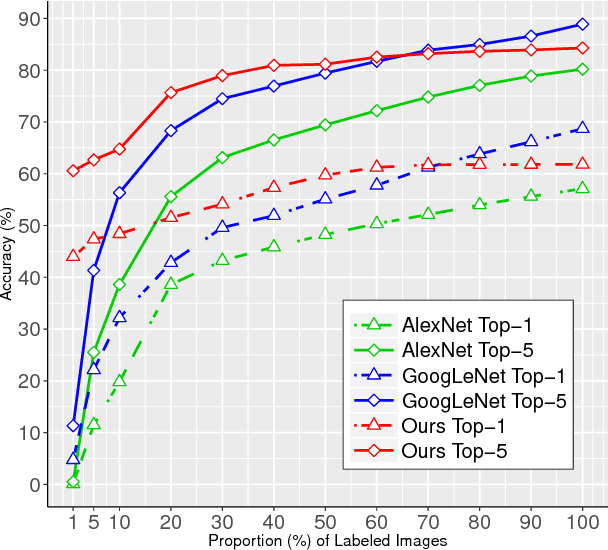
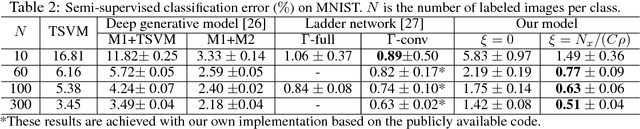

A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code. The latent code is also linked to generative models for labels (Bayesian support vector machine) or captions (recurrent neural network). When predicting a label/caption for a new image at test, averaging is performed across the distribution of latent codes; this is computationally efficient as a consequence of the learned CNN-based encoder. Since the framework is capable of modeling the image in the presence/absence of associated labels/captions, a new semi-supervised setting is manifested for CNN learning with images; the framework even allows unsupervised CNN learning, based on images alone.
The DARPA Twitter Bot Challenge
Apr 21, 2016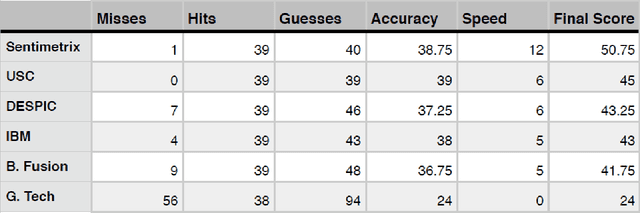
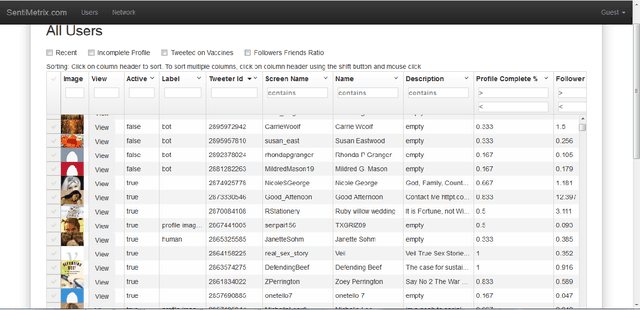
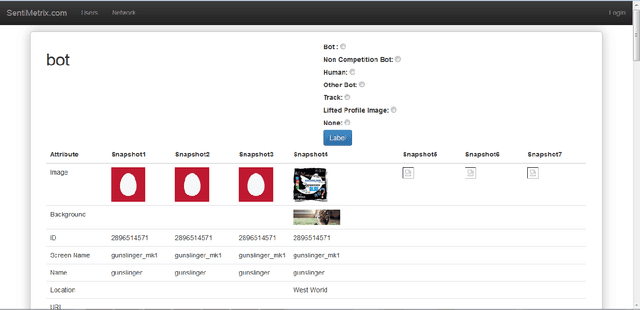
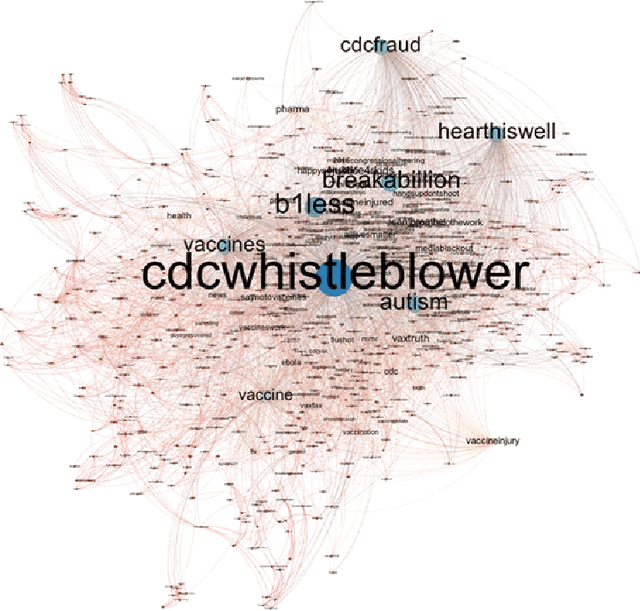
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press
A Deep Generative Deconvolutional Image Model
Dec 23, 2015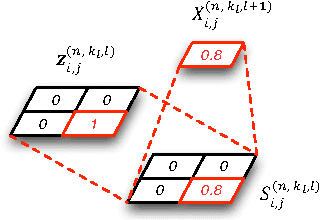
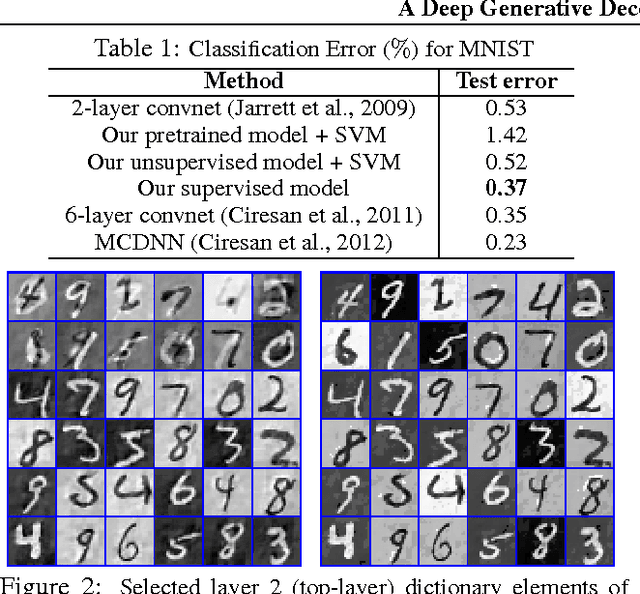
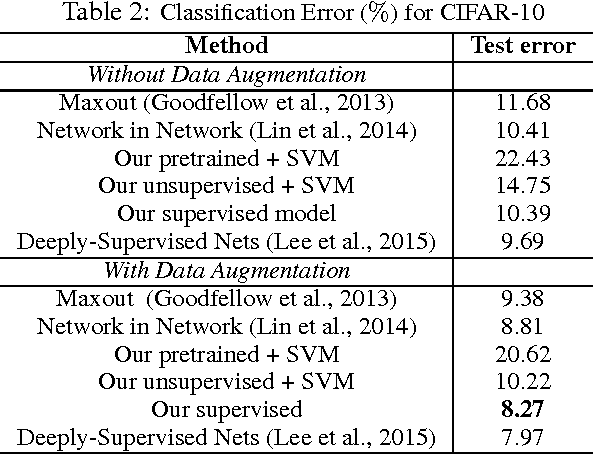

A deep generative model is developed for representation and analysis of images, based on a hierarchical convolutional dictionary-learning framework. Stochastic {\em unpooling} is employed to link consecutive layers in the model, yielding top-down image generation. A Bayesian support vector machine is linked to the top-layer features, yielding max-margin discrimination. Deep deconvolutional inference is employed when testing, to infer the latent features, and the top-layer features are connected with the max-margin classifier for discrimination tasks. The model is efficiently trained using a Monte Carlo expectation-maximization (MCEM) algorithm, with implementation on graphical processor units (GPUs) for efficient large-scale learning, and fast testing. Excellent results are obtained on several benchmark datasets, including ImageNet, demonstrating that the proposed model achieves results that are highly competitive with similarly sized convolutional neural networks.