 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiST: Understanding the Role of Mid-Stage Scientific Training in Developing Chemical Reasoning Models
Dec 24, 2025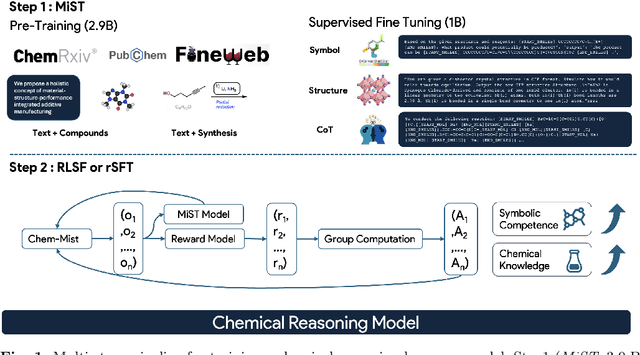
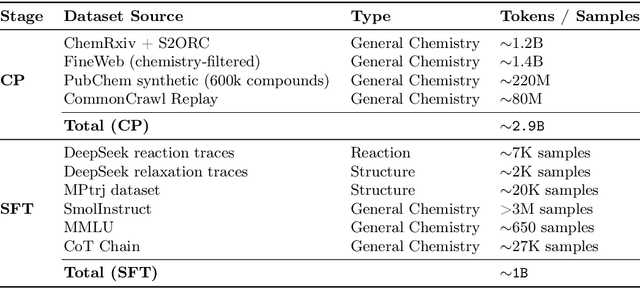
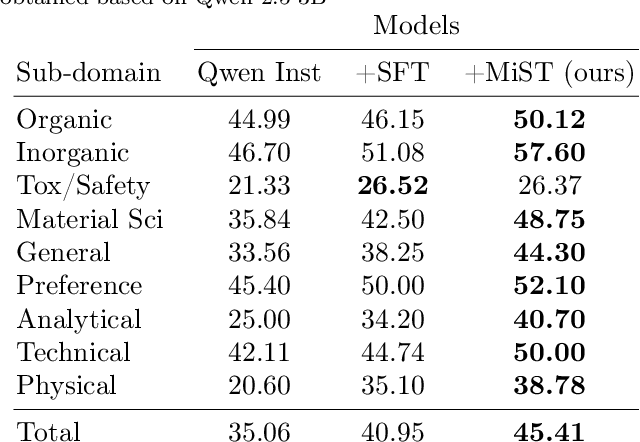
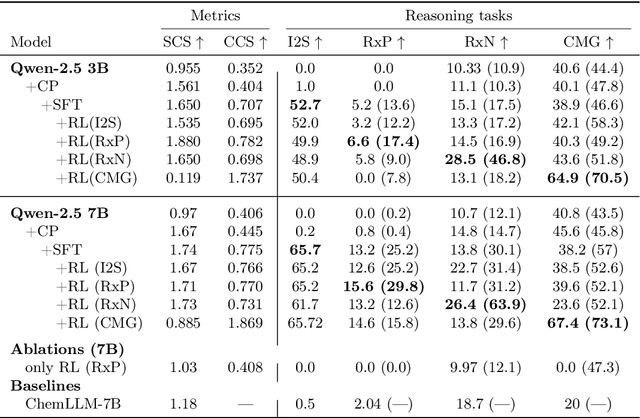
Large Language Models can develop reasoning capabilities through online fine-tuning with rule-based rewards. However, recent studies reveal a critical constraint: reinforcement learning succeeds only when the base model already assigns non-negligible probability to correct answers -- a property we term 'latent solvability'. This work investigates the emergence of chemical reasoning capabilities and what these prerequisites mean for chemistry. We identify two necessary conditions for RL-based chemical reasoning: 1) Symbolic competence, and 2) Latent chemical knowledge. We propose mid-stage scientific training (MiST): a set of mid-stage training techniques to satisfy these, including data-mixing with SMILES/CIF-aware pre-processing, continued pre-training on 2.9B tokens, and supervised fine-tuning on 1B tokens. These steps raise the latent-solvability score on 3B and 7B models by up to 1.8x, and enable RL to lift top-1 accuracy from 10.9 to 63.9% on organic reaction naming, and from 40.6 to 67.4% on inorganic material generation. Similar results are observed for other challenging chemical tasks, while producing interpretable reasoning traces. Our results define clear prerequisites for chemical reasoning training and highlight the broader role of mid-stage training in unlocking reasoning capabilities.
Synthelite: Chemist-aligned and feasibility-aware synthesis planning with LLMs
Dec 18, 2025



Computer-aided synthesis planning (CASP) has long been envisioned as a complementary tool for synthetic chemists. However, existing frameworks often lack mechanisms to allow interaction with human experts, limiting their ability to integrate chemists' insights. In this work, we introduce Synthelite, a synthesis planning framework that uses large language models (LLMs) to directly propose retrosynthetic transformations. Synthelite can generate end-to-end synthesis routes by harnessing the intrinsic chemical knowledge and reasoning capabilities of LLMs, while allowing expert intervention through natural language prompts. Our experiments demonstrate that Synthelite can flexibly adapt its planning trajectory to diverse user-specified constraints, achieving up to 95\% success rates in both strategy-constrained and starting-material-constrained synthesis tasks. Additionally, Synthelite exhibits the ability to account for chemical feasibility during route design. We envision Synthelite to be both a useful tool and a step toward a paradigm where LLMs are the central orchestrators of synthesis planning.
Position: Intelligent Science Laboratory Requires the Integration of Cognitive and Embodied AI
Jun 24, 2025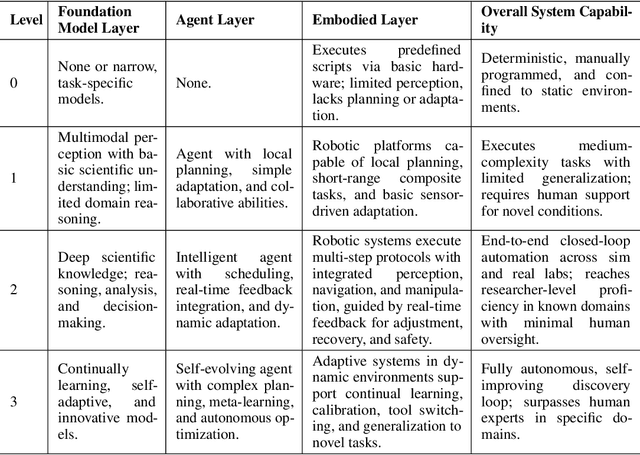
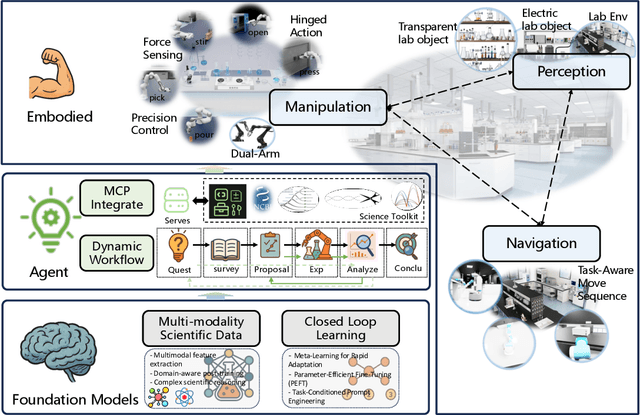
Scientific discovery has long been constrained by human limitations in expertise, physical capability, and sleep cycles. The recent rise of AI scientists and automated laboratories has accelerated both the cognitive and operational aspects of research. However, key limitations persist: AI systems are often confined to virtual environments, while automated laboratories lack the flexibility and autonomy to adaptively test new hypotheses in the physical world. Recent advances in embodied AI, such as generalist robot foundation models, diffusion-based action policies, fine-grained manipulation learning, and sim-to-real transfer, highlight the promise of integrating cognitive and embodied intelligence. This convergence opens the door to closed-loop systems that support iterative, autonomous experimentation and the possibility of serendipitous discovery. In this position paper, we propose the paradigm of Intelligent Science Laboratories (ISLs): a multi-layered, closed-loop framework that deeply integrates cognitive and embodied intelligence. ISLs unify foundation models for scientific reasoning, agent-based workflow orchestration, and embodied agents for robust physical experimentation. We argue that such systems are essential for overcoming the current limitations of scientific discovery and for realizing the full transformative potential of AI-driven science.
Chemical reasoning in LLMs unlocks steerable synthesis planning and reaction mechanism elucidation
Mar 11, 2025While machine learning algorithms have been shown to excel at specific chemical tasks, they have struggled to capture the strategic thinking that characterizes expert chemical reasoning, limiting their widespread adoption. Here we demonstrate that large language models (LLMs) can serve as powerful chemical reasoning engines when integrated with traditional search algorithms, enabling a new approach to computer-aided chemistry that mirrors human expert thinking. Rather than using LLMs to directly manipulate chemical structures, we leverage their ability to evaluate chemical strategies and guide search algorithms toward chemically meaningful solutions. We demonstrate this paradigm through two fundamental challenges: strategy-aware retrosynthetic planning and mechanism elucidation. In retrosynthetic planning, our method allows chemists to specify desired synthetic strategies in natural language to find routes that satisfy these constraints in vast searches. In mechanism elucidation, LLMs guide the search for plausible reaction mechanisms by combining chemical principles with systematic exploration. Our approach shows strong performance across diverse chemical tasks, with larger models demonstrating increasingly sophisticated chemical reasoning. Our approach establishes a new paradigm for computer-aided chemistry that combines the strategic understanding of LLMs with the precision of traditional chemical tools, opening possibilities for more intuitive and powerful chemical reasoning systems.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Reflections from the 2024 Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry
Nov 20, 2024



Here, we present the outcomes from the second Large Language Model (LLM) Hackathon for Applications in Materials Science and Chemistry, which engaged participants across global hybrid locations, resulting in 34 team submissions. The submissions spanned seven key application areas and demonstrated the diverse utility of LLMs for applications in (1) molecular and material property prediction; (2) molecular and material design; (3) automation and novel interfaces; (4) scientific communication and education; (5) research data management and automation; (6) hypothesis generation and evaluation; and (7) knowledge extraction and reasoning from scientific literature. Each team submission is presented in a summary table with links to the code and as brief papers in the appendix. Beyond team results, we discuss the hackathon event and its hybrid format, which included physical hubs in Toronto, Montreal, San Francisco, Berlin, Lausanne, and Tokyo, alongside a global online hub to enable local and virtual collaboration. Overall, the event highlighted significant improvements in LLM capabilities since the previous year's hackathon, suggesting continued expansion of LLMs for applications in materials science and chemistry research. These outcomes demonstrate the dual utility of LLMs as both multipurpose models for diverse machine learning tasks and platforms for rapid prototyping custom applications in scientific research.
Transformers and Large Language Models for Chemistry and Drug Discovery
Oct 09, 2023
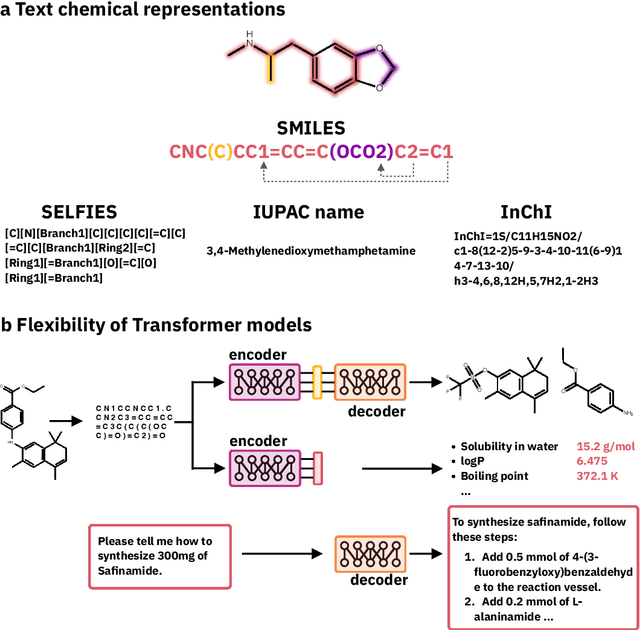

Language modeling has seen impressive progress over the last years, mainly prompted by the invention of the Transformer architecture, sparking a revolution in many fields of machine learning, with breakthroughs in chemistry and biology. In this chapter, we explore how analogies between chemical and natural language have inspired the use of Transformers to tackle important bottlenecks in the drug discovery process, such as retrosynthetic planning and chemical space exploration. The revolution started with models able to perform particular tasks with a single type of data, like linearised molecular graphs, which then evolved to include other types of data, like spectra from analytical instruments, synthesis actions, and human language. A new trend leverages recent developments in large language models, giving rise to a wave of models capable of solving generic tasks in chemistry, all facilitated by the flexibility of natural language. As we continue to explore and harness these capabilities, we can look forward to a future where machine learning plays an even more integral role in accelerating scientific discovery.
ChemCrow: Augmenting large-language models with chemistry tools
Apr 12, 2023Large-language models (LLMs) have recently shown strong performance in tasks across domains, but struggle with chemistry-related problems. Moreover, these models lack access to external knowledge sources, limiting their usefulness in scientific applications. In this study, we introduce ChemCrow, an LLM chemistry agent designed to accomplish tasks across organic synthesis, drug discovery, and materials design. By integrating 13 expert-designed tools, ChemCrow augments the LLM performance in chemistry, and new capabilities emerge. Our evaluation, including both LLM and expert human assessments, demonstrates ChemCrow's effectiveness in automating a diverse set of chemical tasks. Surprisingly, we find that GPT-4 as an evaluator cannot distinguish between clearly wrong GPT-4 completions and GPT-4 + ChemCrow performance. There is a significant risk of misuse of tools like ChemCrow and we discuss their potential harms. Employed responsibly, ChemCrow not only aids expert chemists and lowers barriers for non-experts, but also fosters scientific advancement by bridging the gap between experimental and computational chemistry.