 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-Guided Diffusion for 3D Human Recovery
Mar 14, 2024We present Score-Guided Human Mesh Recovery (ScoreHMR), an approach for solving inverse problems for 3D human pose and shape reconstruction. These inverse problems involve fitting a human body model to image observations, traditionally solved through optimization techniques. ScoreHMR mimics model fitting approaches, but alignment with the image observation is achieved through score guidance in the latent space of a diffusion model. The diffusion model is trained to capture the conditional distribution of the human model parameters given an input image. By guiding its denoising process with a task-specific score, ScoreHMR effectively solves inverse problems for various applications without the need for retraining the task-agnostic diffusion model. We evaluate our approach on three settings/applications. These are: (i) single-frame model fitting; (ii) reconstruction from multiple uncalibrated views; (iii) reconstructing humans in video sequences. ScoreHMR consistently outperforms all optimization baselines on popular benchmarks across all settings. We make our code and models available at the https://statho.github.io/ScoreHMR.
Improving Tuning-Free Real Image Editing with Proximal Guidance
Jun 29, 2023
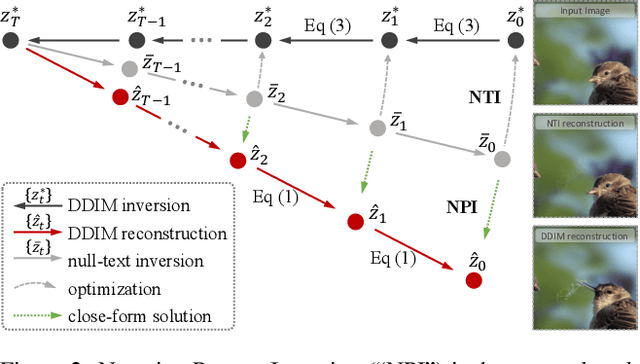
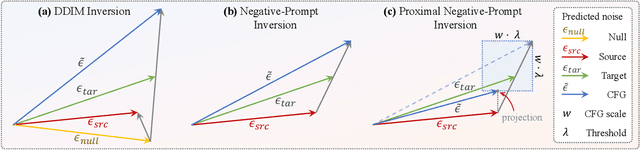

DDIM inversion has revealed the remarkable potential of real image editing within diffusion-based methods. However, the accuracy of DDIM reconstruction degrades as larger classifier-free guidance (CFG) scales being used for enhanced editing. Null-text inversion (NTI) optimizes null embeddings to align the reconstruction and inversion trajectories with larger CFG scales, enabling real image editing with cross-attention control. Negative-prompt inversion (NPI) further offers a training-free closed-form solution of NTI. However, it may introduce artifacts and is still constrained by DDIM reconstruction quality. To overcome these limitations, we propose proximal guidance and incorporate it to NPI with cross-attention control. We enhance NPI with a regularization term and reconstruction guidance, which reduces artifacts while capitalizing on its training-free nature. Additionally, we extend the concepts to incorporate mutual self-attention control, enabling geometry and layout alterations in the editing process. Our method provides an efficient and straightforward approach, effectively addressing real image editing tasks with minimal computational overhead.
Learning Articulated Shape with Keypoint Pseudo-labels from Web Images
Apr 27, 2023


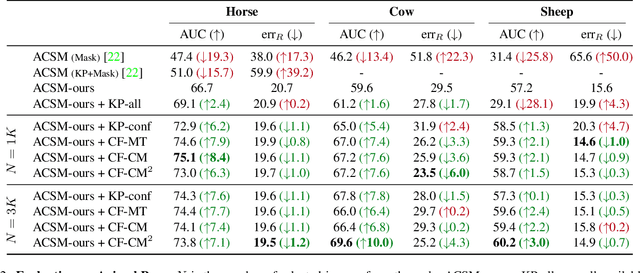
This paper shows that it is possible to learn models for monocular 3D reconstruction of articulated objects (e.g., horses, cows, sheep), using as few as 50-150 images labeled with 2D keypoints. Our proposed approach involves training category-specific keypoint estimators, generating 2D keypoint pseudo-labels on unlabeled web images, and using both the labeled and self-labeled sets to train 3D reconstruction models. It is based on two key insights: (1) 2D keypoint estimation networks trained on as few as 50-150 images of a given object category generalize well and generate reliable pseudo-labels; (2) a data selection mechanism can automatically create a "curated" subset of the unlabeled web images that can be used for training -- we evaluate four data selection methods. Coupling these two insights enables us to train models that effectively utilize web images, resulting in improved 3D reconstruction performance for several articulated object categories beyond the fully-supervised baseline. Our approach can quickly bootstrap a model and requires only a few images labeled with 2D keypoints. This requirement can be easily satisfied for any new object category. To showcase the practicality of our approach for predicting the 3D shape of arbitrary object categories, we annotate 2D keypoints on giraffe and bear images from COCO -- the annotation process takes less than 1 minute per image.
Exploiting Unlabeled Data with Vision and Language Models for Object Detection
Jul 18, 2022
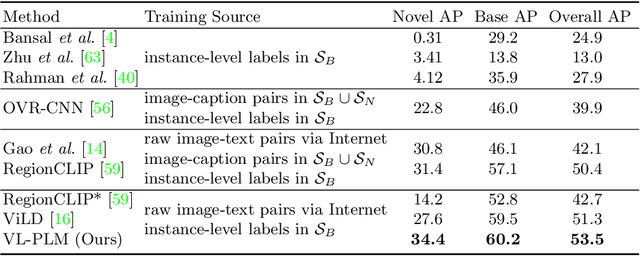
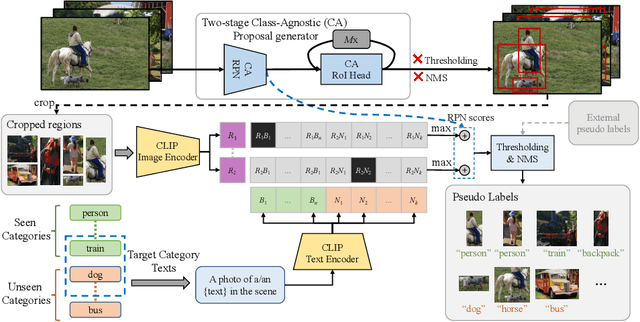

Building robust and generic object detection frameworks requires scaling to larger label spaces and bigger training datasets. However, it is prohibitively costly to acquire annotations for thousands of categories at a large scale. We propose a novel method that leverages the rich semantics available in recent vision and language models to localize and classify objects in unlabeled images, effectively generating pseudo labels for object detection. Starting with a generic and class-agnostic region proposal mechanism, we use vision and language models to categorize each region of an image into any object category that is required for downstream tasks. We demonstrate the value of the generated pseudo labels in two specific tasks, open-vocabulary detection, where a model needs to generalize to unseen object categories, and semi-supervised object detection, where additional unlabeled images can be used to improve the model. Our empirical evaluation shows the effectiveness of the pseudo labels in both tasks, where we outperform competitive baselines and achieve a novel state-of-the-art for open-vocabulary object detection. Our code is available at https://github.com/xiaofeng94/VL-PLM.
Dual Projection Generative Adversarial Networks for Conditional Image Generation
Aug 20, 2021
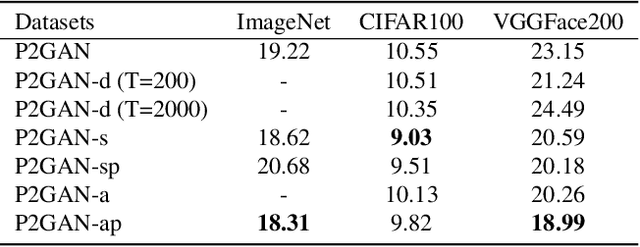
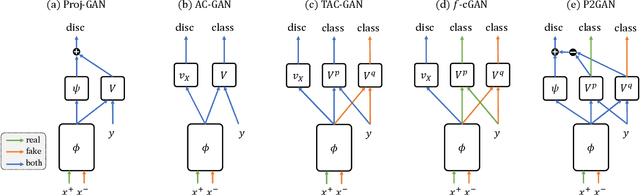

Conditional Generative Adversarial Networks (cGANs) extend the standard unconditional GAN framework to learning joint data-label distributions from samples, and have been established as powerful generative models capable of generating high-fidelity imagery. A challenge of training such a model lies in properly infusing class information into its generator and discriminator. For the discriminator, class conditioning can be achieved by either (1) directly incorporating labels as input or (2) involving labels in an auxiliary classification loss. In this paper, we show that the former directly aligns the class-conditioned fake-and-real data distributions $P(\text{image}|\text{class})$ ({\em data matching}), while the latter aligns data-conditioned class distributions $P(\text{class}|\text{image})$ ({\em label matching}). Although class separability does not directly translate to sample quality and becomes a burden if classification itself is intrinsically difficult, the discriminator cannot provide useful guidance for the generator if features of distinct classes are mapped to the same point and thus become inseparable. Motivated by this intuition, we propose a Dual Projection GAN (P2GAN) model that learns to balance between {\em data matching} and {\em label matching}. We then propose an improved cGAN model with Auxiliary Classification that directly aligns the fake and real conditionals $P(\text{class}|\text{image})$ by minimizing their $f$-divergence. Experiments on a synthetic Mixture of Gaussian (MoG) dataset and a variety of real-world datasets including CIFAR100, ImageNet, and VGGFace2 demonstrate the efficacy of our proposed models.
Unbiased Auxiliary Classifier GANs with MINE
Jun 13, 2020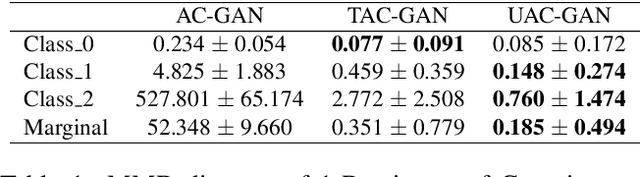


Auxiliary Classifier GANs (AC-GANs) are widely used conditional generative models and are capable of generating high-quality images. Previous work has pointed out that AC-GAN learns a biased distribution. To remedy this, Twin Auxiliary Classifier GAN (TAC-GAN) introduces a twin classifier to the min-max game. However, it has been reported that using a twin auxiliary classifier may cause instability in training. To this end, we propose an Unbiased Auxiliary GANs (UAC-GAN) that utilizes the Mutual Information Neural Estimator (MINE) to estimate the mutual information between the generated data distribution and labels. To further improve the performance, we also propose a novel projection-based statistics network architecture for MINE. Experimental results on three datasets, including Mixture of Gaussian (MoG), MNIST and CIFAR10 datasets, show that our UAC-GAN performs better than AC-GAN and TAC-GAN. Code can be found on the project website.