 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Articulated Shape with Keypoint Pseudo-labels from Web Images
Paper and Code



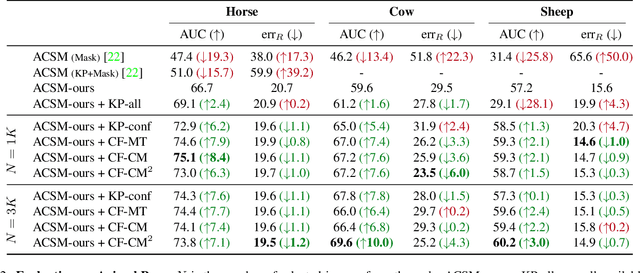
This paper shows that it is possible to learn models for monocular 3D reconstruction of articulated objects (e.g., horses, cows, sheep), using as few as 50-150 images labeled with 2D keypoints. Our proposed approach involves training category-specific keypoint estimators, generating 2D keypoint pseudo-labels on unlabeled web images, and using both the labeled and self-labeled sets to train 3D reconstruction models. It is based on two key insights: (1) 2D keypoint estimation networks trained on as few as 50-150 images of a given object category generalize well and generate reliable pseudo-labels; (2) a data selection mechanism can automatically create a "curated" subset of the unlabeled web images that can be used for training -- we evaluate four data selection methods. Coupling these two insights enables us to train models that effectively utilize web images, resulting in improved 3D reconstruction performance for several articulated object categories beyond the fully-supervised baseline. Our approach can quickly bootstrap a model and requires only a few images labeled with 2D keypoints. This requirement can be easily satisfied for any new object category. To showcase the practicality of our approach for predicting the 3D shape of arbitrary object categories, we annotate 2D keypoints on giraffe and bear images from COCO -- the annotation process takes less than 1 minute per image.