 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot ECG Classification with Multimodal Learning and Test-time Clinical Knowledge Enhancement
Mar 11, 2024



Electrocardiograms (ECGs) are non-invasive diagnostic tools crucial for detecting cardiac arrhythmic diseases in clinical practice. While ECG Self-supervised Learning (eSSL) methods show promise in representation learning from unannotated ECG data, they often overlook the clinical knowledge that can be found in reports. This oversight and the requirement for annotated samples for downstream tasks limit eSSL's versatility. In this work, we address these issues with the Multimodal ECG Representation Learning (MERL}) framework. Through multimodal learning on ECG records and associated reports, MERL is capable of performing zero-shot ECG classification with text prompts, eliminating the need for training data in downstream tasks. At test time, we propose the Clinical Knowledge Enhanced Prompt Engineering (CKEPE) approach, which uses Large Language Models (LLMs) to exploit external expert-verified clinical knowledge databases, generating more descriptive prompts and reducing hallucinations in LLM-generated content to boost zero-shot classification. Based on MERL, we perform the first benchmark across six public ECG datasets, showing the superior performance of MERL compared against eSSL methods. Notably, MERL achieves an average AUC score of 75.2% in zero-shot classification (without training data), 3.2% higher than linear probed eSSL methods with 10\% annotated training data, averaged across all six datasets.
T3D: Towards 3D Medical Image Understanding through Vision-Language Pre-training
Dec 05, 2023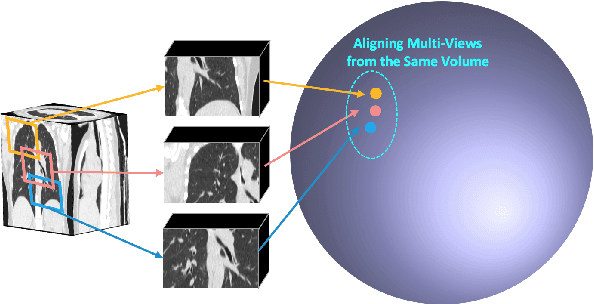
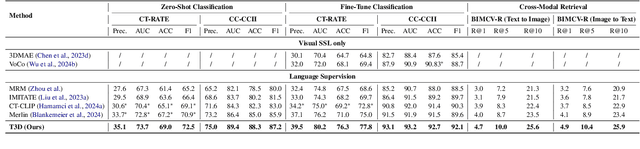
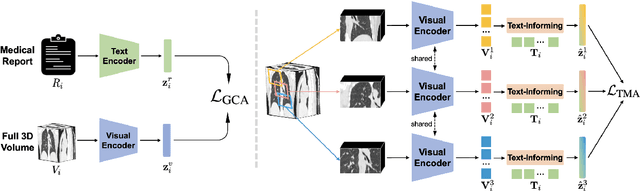
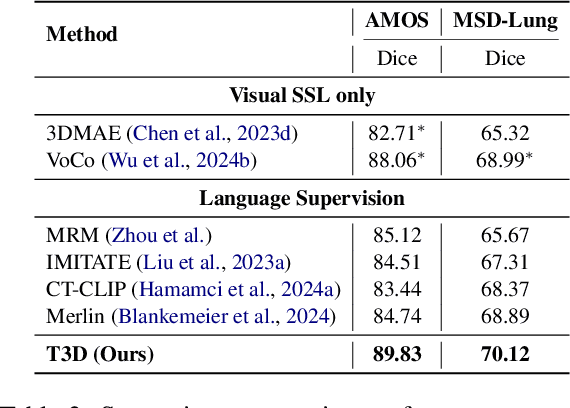
Expert annotation of 3D medical image for downstream analysis is resource-intensive, posing challenges in clinical applications. Visual self-supervised learning (vSSL), though effective for learning visual invariance, neglects the incorporation of domain knowledge from medicine. To incorporate medical knowledge into visual representation learning, vision-language pre-training (VLP) has shown promising results in 2D image. However, existing VLP approaches become generally impractical when applied to high-resolution 3D medical images due to GPU hardware constraints and the potential loss of critical details caused by downsampling, which is the intuitive solution to hardware constraints. To address the above limitations, we introduce T3D, the first VLP framework designed for high-resolution 3D medical images. T3D incorporates two text-informed pretext tasks: (\lowerromannumeral{1}) text-informed contrastive learning; (\lowerromannumeral{2}) text-informed image restoration. These tasks focus on learning 3D visual representations from high-resolution 3D medical images and integrating clinical knowledge from radiology reports, without distorting information through forced alignment of downsampled volumes with detailed anatomical text. Trained on a newly curated large-scale dataset of 3D medical images and radiology reports, T3D significantly outperforms current vSSL methods in tasks like organ and tumor segmentation, as well as disease classification. This underlines T3D's potential in representation learning for 3D medical image analysis. All data and code will be available upon acceptance.
G2D: From Global to Dense Radiography Representation Learning via Vision-Language Pre-training
Dec 03, 2023Recently, medical vision-language pre-training (VLP) has reached substantial progress to learn global visual representation from medical images and their paired radiology reports. However, medical imaging tasks in real world usually require finer granularity in visual features. These tasks include visual localization tasks (e.g., semantic segmentation, object detection) and visual grounding task. Yet, current medical VLP methods face challenges in learning these fine-grained features, as they primarily focus on brute-force alignment between image patches and individual text tokens for local visual feature learning, which is suboptimal for downstream dense prediction tasks. In this work, we propose a new VLP framework, named \textbf{G}lobal to \textbf{D}ense level representation learning (G2D) that achieves significantly improved granularity and more accurate grounding for the learned features, compared to existing medical VLP approaches. In particular, G2D learns dense and semantically-grounded image representations via a pseudo segmentation task parallel with the global vision-language alignment. Notably, generating pseudo segmentation targets does not incur extra trainable parameters: they are obtained on the fly during VLP with a parameter-free processor. G2D achieves superior performance across 6 medical imaging tasks and 25 diseases, particularly in semantic segmentation, which necessitates fine-grained, semantically-grounded image features. In this task, G2D surpasses peer models even when fine-tuned with just 1\% of the training data, compared to the 100\% used by these models. The code will be released upon acceptance.
IMITATE: Clinical Prior Guided Hierarchical Vision-Language Pre-training
Oct 11, 2023



In the field of medical Vision-Language Pre-training (VLP), significant efforts have been devoted to deriving text and image features from both clinical reports and associated medical images. However, most existing methods may have overlooked the opportunity in leveraging the inherent hierarchical structure of clinical reports, which are generally split into `findings' for descriptive content and `impressions' for conclusive observation. Instead of utilizing this rich, structured format, current medical VLP approaches often simplify the report into either a unified entity or fragmented tokens. In this work, we propose a novel clinical prior guided VLP framework named IMITATE to learn the structure information from medical reports with hierarchical vision-language alignment. The framework derives multi-level visual features from the chest X-ray (CXR) images and separately aligns these features with the descriptive and the conclusive text encoded in the hierarchical medical report. Furthermore, a new clinical-informed contrastive loss is introduced for cross-modal learning, which accounts for clinical prior knowledge in formulating sample correlations in contrastive learning. The proposed model, IMITATE, outperforms baseline VLP methods across six different datasets, spanning five medical imaging downstream tasks. Comprehensive experimental results highlight the advantages of integrating the hierarchical structure of medical reports for vision-language alignment.
Utilizing Synthetic Data for Medical Vision-Language Pre-training: Bypassing the Need for Real Images
Oct 10, 2023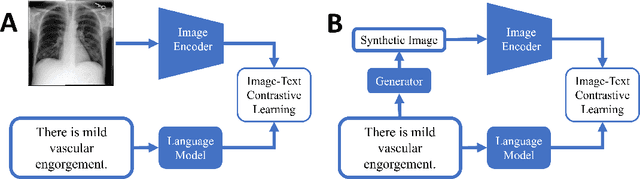
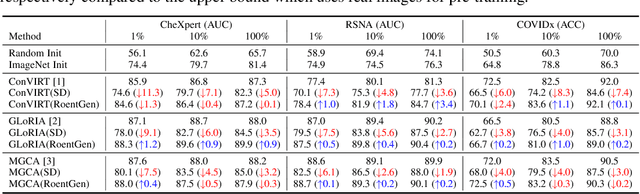
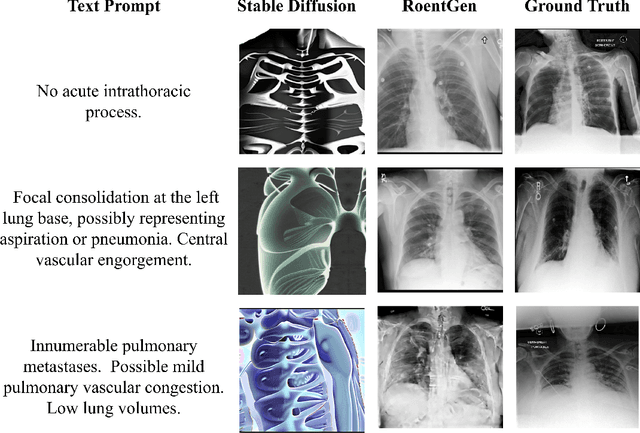
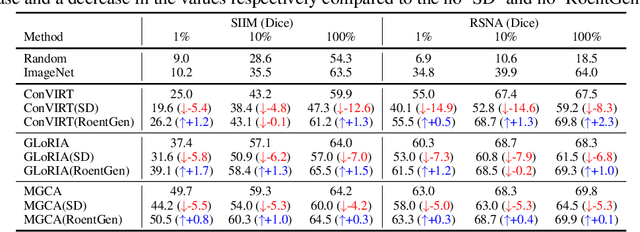
Medical Vision-Language Pre-training (VLP) learns representations jointly from medical images and paired radiology reports. It typically requires large-scale paired image-text datasets to achieve effective pre-training for both the image encoder and text encoder. The advent of text-guided generative models raises a compelling question: Can VLP be implemented solely with synthetic images generated from genuine radiology reports, thereby mitigating the need for extensively pairing and curating image-text datasets? In this work, we scrutinize this very question by examining the feasibility and effectiveness of employing synthetic images for medical VLP. We replace real medical images with their synthetic equivalents, generated from authentic medical reports. Utilizing three state-of-the-art VLP algorithms, we exclusively train on these synthetic samples. Our empirical evaluation across three subsequent tasks, namely image classification, semantic segmentation and object detection, reveals that the performance achieved through synthetic data is on par with or even exceeds that obtained with real images. As a pioneering contribution to this domain, we introduce a large-scale synthetic medical image dataset, paired with anonymized real radiology reports. This alleviates the need of sharing medical images, which are not easy to curate and share in practice. The code and the dataset will be made publicly available upon paper acceptance.
M-FLAG: Medical Vision-Language Pre-training with Frozen Language Models and Latent Space Geometry Optimization
Jul 19, 2023
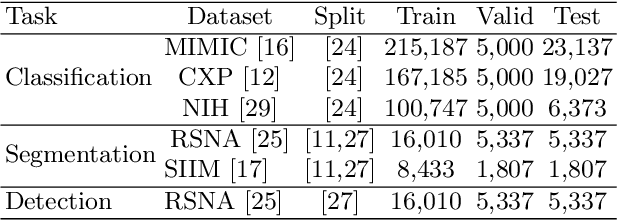
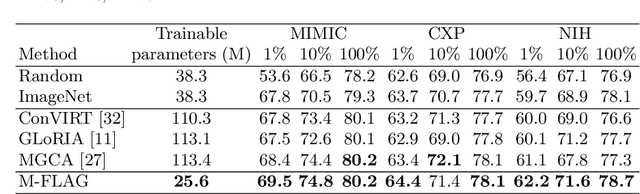

Medical vision-language models enable co-learning and integrating features from medical imaging and clinical text. However, these models are not easy to train and the latent representation space can be complex. Here we propose a novel way for pre-training and regularising medical vision-language models. The proposed method, named Medical vision-language pre-training with Frozen language models and Latent spAce Geometry optimization (M-FLAG), leverages a frozen language model for training stability and efficiency and introduces a novel orthogonality loss to harmonize the latent space geometry. We demonstrate the potential of the pre-trained model on three downstream tasks: medical image classification, segmentation, and object detection. Extensive experiments across five public datasets demonstrate that M-FLAG significantly outperforms existing medical vision-language pre-training approaches and reduces the number of parameters by 78\%. Notably, M-FLAG achieves outstanding performance on the segmentation task while using only 1\% of the RSNA dataset, even outperforming ImageNet pre-trained models that have been fine-tuned using 100\% of the data.
SAPSAM - Sparsely Annotated Pathological Sign Activation Maps - A novel approach to train Convolutional Neural Networks on lung CT scans using binary labels only
Feb 06, 2019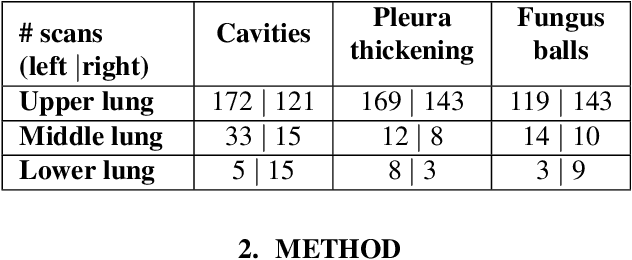



Chronic Pulmonary Aspergillosis (CPA) is a complex lung disease caused by infection with Aspergillus. Computed tomography (CT) images are frequently requested in patients with suspected and established disease, but the radiological signs on CT are difficult to quantify making accurate follow-up challenging. We propose a novel method to train Convolutional Neural Networks using only regional labels on the presence of pathological signs, to not only detect CPA, but also spatially localize pathological signs. We use average intensity projections within different ranges of Hounsfield-unit (HU) values, transforming input 3D CT scans into 2D RGB-like images. CNN architectures are trained for hierarchical tasks, leading to precise activation maps of pathological patterns. Results on a cohort of 352 subjects demonstrate high classification accuracy, localization precision and predictive power of 2 year survival. Such tool opens the way to CPA patient stratification and quantitative follow-up of CPA pathological signs, for patients under drug therapy.
* Accepted paper for ISBI2019