 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Creative Intent and Visual Quality: Creator-Driven Recurrent Video Generation with Agentic Feedback Loops
Jun 17, 2026Generative AI has made content creation increasingly accessible, but many AI-generated videos lack narrative coherence and creative direction, issues that become more substantial at longer durations. Unlike coding, where AI generation benefits from reliable feedback and techniques such as recurrent self-improvement, video generation requires subjective feedback about plot, scenes, and narrative, which naturally motivates approaches that incorporate human creative direction. We introduce CHIEF, a human-AI co-creation video generation framework that places the creator at the center of human-in-the-loop iterative video refinement, and supports them by providing automatic subjective feedback. The creator incorporates their creative direction by driving each iteration, while their revisions are incorporated by a specialized refiner agent. The feedback loop is generated by persona-conditioned multimodal LLMs that watch generated videos and produce subjective critique from the audience perspectives, providing feedback that self-evaluation alone cannot capture. To test the effectiveness of our proposed framework, we work with high school and college students with no prior filmmaking experience to create videos, from short 1-minute videos to a complete short 10-minute film with a complicated plot.
Masked Autoencoders As The Unified Learners For Pre-Trained Sentence Representation
Jul 30, 2022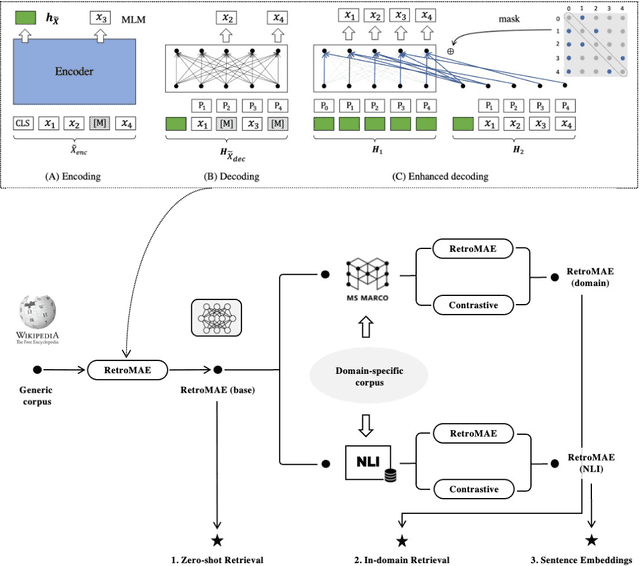
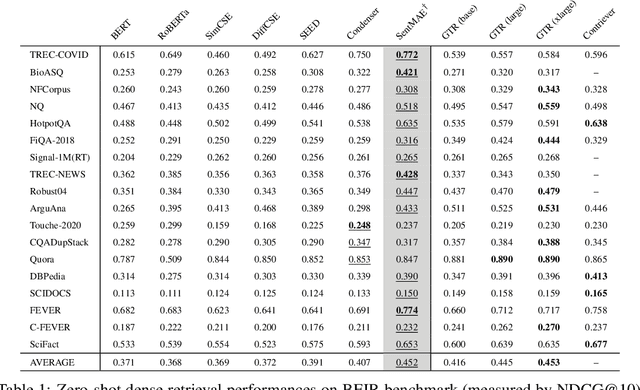
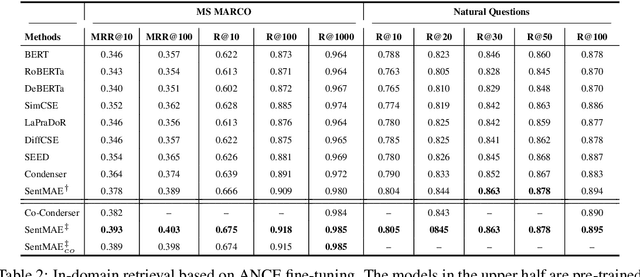
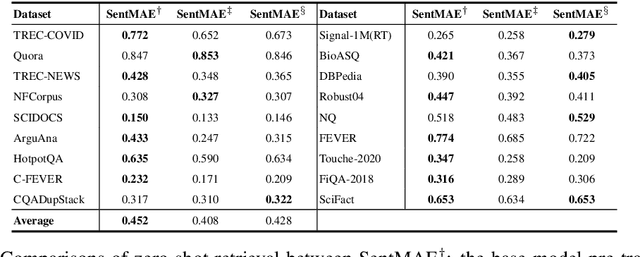
Despite the progresses on pre-trained language models, there is a lack of unified frameworks for pre-trained sentence representation. As such, it calls for different pre-training methods for specific scenarios, and the pre-trained models are likely to be limited by their universality and representation quality. In this work, we extend the recently proposed MAE style pre-training strategy, RetroMAE, such that it may effectively support a wide variety of sentence representation tasks. The extended framework consists of two stages, with RetroMAE conducted throughout the process. The first stage performs RetroMAE over generic corpora, like Wikipedia, BookCorpus, etc., from which the base model is learned. The second stage takes place on domain-specific data, e.g., MS MARCO and NLI, where the base model is continuingly trained based on RetroMAE and contrastive learning. The pre-training outputs at the two stages may serve different applications, whose effectiveness are verified with comprehensive experiments. Concretely, the base model are proved to be effective for zero-shot retrieval, with remarkable performances achieved on BEIR benchmark. The continuingly pre-trained models further benefit more downstream tasks, including the domain-specific dense retrieval on MS MARCO, Natural Questions, and the sentence embeddings' quality for standard STS and transfer tasks in SentEval. The empirical insights of this work may inspire the future design of sentence representation pre-training. Our pre-trained models and source code will be released to the public communities.
Monarch: Expressive Structured Matrices for Efficient and Accurate Training
Apr 01, 2022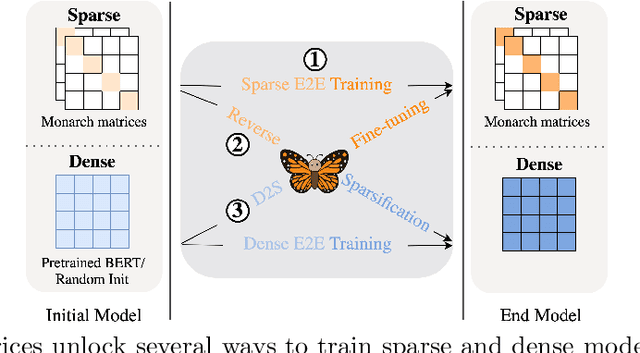
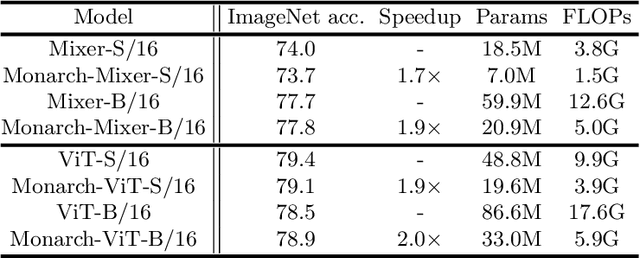
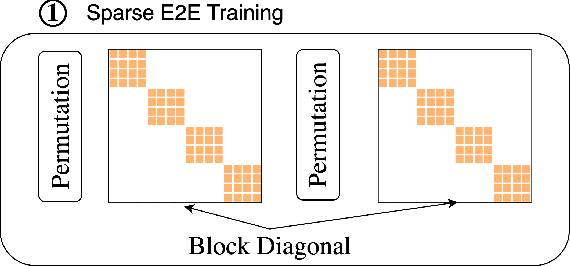
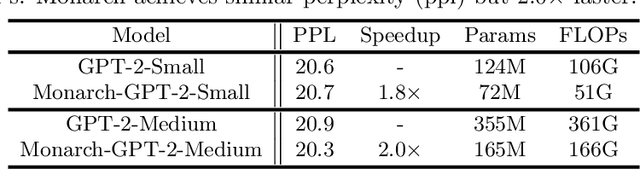
Large neural networks excel in many domains, but they are expensive to train and fine-tune. A popular approach to reduce their compute or memory requirements is to replace dense weight matrices with structured ones (e.g., sparse, low-rank, Fourier transform). These methods have not seen widespread adoption (1) in end-to-end training due to unfavorable efficiency--quality tradeoffs, and (2) in dense-to-sparse fine-tuning due to lack of tractable algorithms to approximate a given dense weight matrix. To address these issues, we propose a class of matrices (Monarch) that is hardware-efficient (they are parameterized as products of two block-diagonal matrices for better hardware utilization) and expressive (they can represent many commonly used transforms). Surprisingly, the problem of approximating a dense weight matrix with a Monarch matrix, though nonconvex, has an analytical optimal solution. These properties of Monarch matrices unlock new ways to train and fine-tune sparse and dense models. We empirically validate that Monarch can achieve favorable accuracy-efficiency tradeoffs in several end-to-end sparse training applications: speeding up ViT and GPT-2 training on ImageNet classification and Wikitext-103 language modeling by 2x with comparable model quality, and reducing the error on PDE solving and MRI reconstruction tasks by 40%. In sparse-to-dense training, with a simple technique called "reverse sparsification," Monarch matrices serve as a useful intermediate representation to speed up GPT-2 pretraining on OpenWebText by 2x without quality drop. The same technique brings 23% faster BERT pretraining than even the very optimized implementation from Nvidia that set the MLPerf 1.1 record. In dense-to-sparse fine-tuning, as a proof-of-concept, our Monarch approximation algorithm speeds up BERT fine-tuning on GLUE by 1.7x with comparable accuracy.
Routing with Self-Attention for Multimodal Capsule Networks
Dec 01, 2021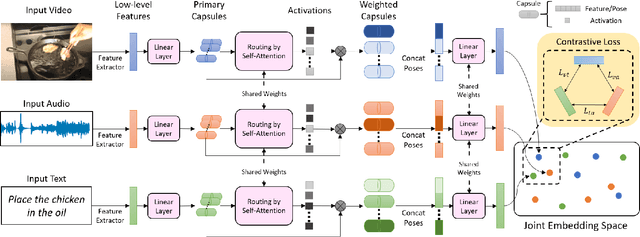
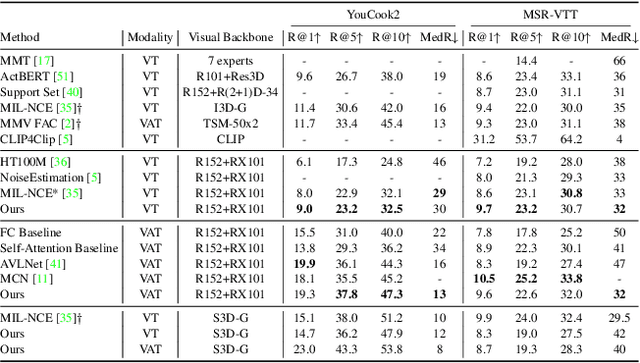
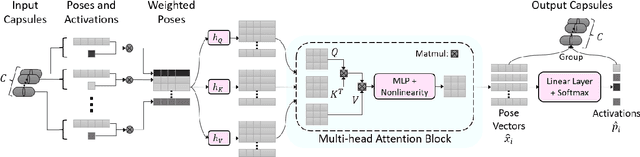
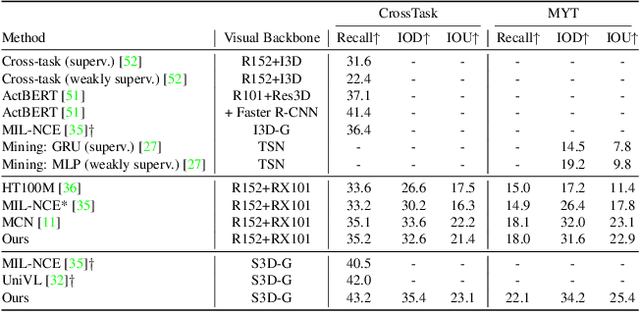
The task of multimodal learning has seen a growing interest recently as it allows for training neural architectures based on different modalities such as vision, text, and audio. One challenge in training such models is that they need to jointly learn semantic concepts and their relationships across different input representations. Capsule networks have been shown to perform well in context of capturing the relation between low-level input features and higher-level concepts. However, capsules have so far mainly been used only in small-scale fully supervised settings due to the resource demand of conventional routing algorithms. We present a new multimodal capsule network that allows us to leverage the strength of capsules in the context of a multimodal learning framework on large amounts of video data. To adapt the capsules to large-scale input data, we propose a novel routing by self-attention mechanism that selects relevant capsules which are then used to generate a final joint multimodal feature representation. This allows not only for robust training with noisy video data, but also to scale up the size of the capsule network compared to traditional routing methods while still being computationally efficient. We evaluate the proposed architecture by pretraining it on a large-scale multimodal video dataset and applying it on four datasets in two challenging downstream tasks. Results show that the proposed multimodal capsule network is not only able to improve results compared to other routing techniques, but also achieves competitive performance on the task of multimodal learning.
Spoken Moments: Learning Joint Audio-Visual Representations from Video Descriptions
May 10, 2021

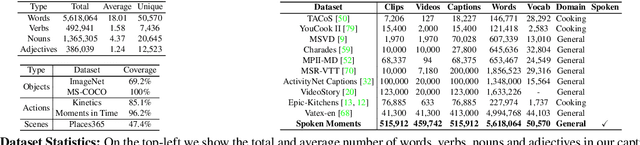
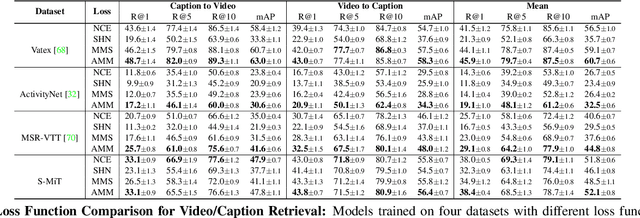
When people observe events, they are able to abstract key information and build concise summaries of what is happening. These summaries include contextual and semantic information describing the important high-level details (what, where, who and how) of the observed event and exclude background information that is deemed unimportant to the observer. With this in mind, the descriptions people generate for videos of different dynamic events can greatly improve our understanding of the key information of interest in each video. These descriptions can be captured in captions that provide expanded attributes for video labeling (e.g. actions/objects/scenes/sentiment/etc.) while allowing us to gain new insight into what people find important or necessary to summarize specific events. Existing caption datasets for video understanding are either small in scale or restricted to a specific domain. To address this, we present the Spoken Moments (S-MiT) dataset of 500k spoken captions each attributed to a unique short video depicting a broad range of different events. We collect our descriptions using audio recordings to ensure that they remain as natural and concise as possible while allowing us to scale the size of a large classification dataset. In order to utilize our proposed dataset, we present a novel Adaptive Mean Margin (AMM) approach to contrastive learning and evaluate our models on video/caption retrieval on multiple datasets. We show that our AMM approach consistently improves our results and that models trained on our Spoken Moments dataset generalize better than those trained on other video-caption datasets.