 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Autoencoders As The Unified Learners For Pre-Trained Sentence Representation
Paper and Code
Jul 30, 2022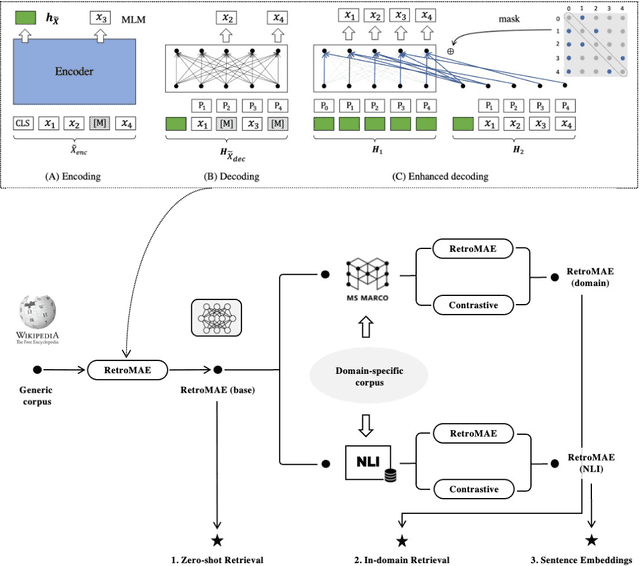
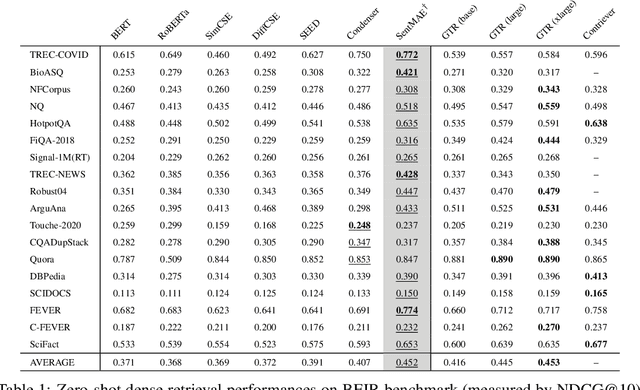
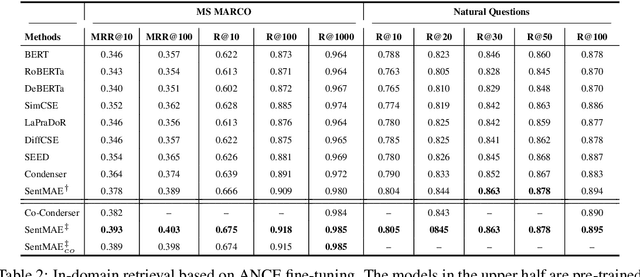
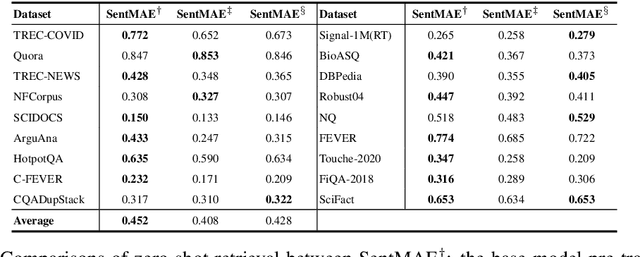
Despite the progresses on pre-trained language models, there is a lack of unified frameworks for pre-trained sentence representation. As such, it calls for different pre-training methods for specific scenarios, and the pre-trained models are likely to be limited by their universality and representation quality. In this work, we extend the recently proposed MAE style pre-training strategy, RetroMAE, such that it may effectively support a wide variety of sentence representation tasks. The extended framework consists of two stages, with RetroMAE conducted throughout the process. The first stage performs RetroMAE over generic corpora, like Wikipedia, BookCorpus, etc., from which the base model is learned. The second stage takes place on domain-specific data, e.g., MS MARCO and NLI, where the base model is continuingly trained based on RetroMAE and contrastive learning. The pre-training outputs at the two stages may serve different applications, whose effectiveness are verified with comprehensive experiments. Concretely, the base model are proved to be effective for zero-shot retrieval, with remarkable performances achieved on BEIR benchmark. The continuingly pre-trained models further benefit more downstream tasks, including the domain-specific dense retrieval on MS MARCO, Natural Questions, and the sentence embeddings' quality for standard STS and transfer tasks in SentEval. The empirical insights of this work may inspire the future design of sentence representation pre-training. Our pre-trained models and source code will be released to the public communities.