 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming and Combining Rewards for Aligning Large Language Models
Feb 01, 2024A common approach for aligning language models to human preferences is to first learn a reward model from preference data, and then use this reward model to update the language model. We study two closely related problems that arise in this approach. First, any monotone transformation of the reward model preserves preference ranking; is there a choice that is ``better'' than others? Second, we often wish to align language models to multiple properties: how should we combine multiple reward models? Using a probabilistic interpretation of the alignment procedure, we identify a natural choice for transformation for (the common case of) rewards learned from Bradley-Terry preference models. This derived transformation has two important properties. First, it emphasizes improving poorly-performing outputs, rather than outputs that already score well. This mitigates both underfitting (where some prompts are not improved) and reward hacking (where the model learns to exploit misspecification of the reward model). Second, it enables principled aggregation of rewards by linking summation to logical conjunction: the sum of transformed rewards corresponds to the probability that the output is ``good'' in all measured properties, in a sense we make precise. Experiments aligning language models to be both helpful and harmless using RLHF show substantial improvements over the baseline (non-transformed) approach.
Helping or Herding? Reward Model Ensembles Mitigate but do not Eliminate Reward Hacking
Dec 21, 2023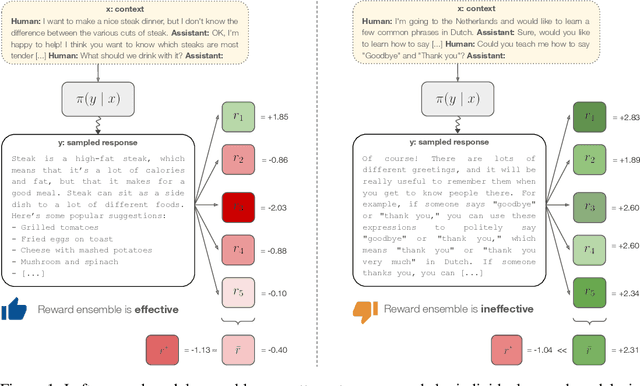

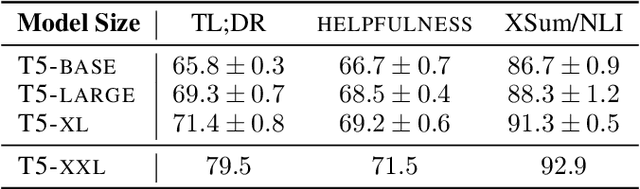
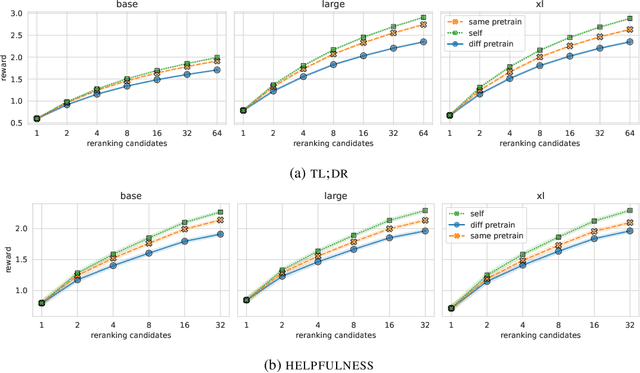
Reward models play a key role in aligning language model applications towards human preferences. However, this setup creates an incentive for the language model to exploit errors in the reward model to achieve high estimated reward, a phenomenon often termed \emph{reward hacking}. A natural mitigation is to train an ensemble of reward models, aggregating over model outputs to obtain a more robust reward estimate. We explore the application of reward ensembles to alignment at both training time (through reinforcement learning) and inference time (through reranking). First, we show that reward models are \emph{underspecified}: reward models that perform similarly in-distribution can yield very different rewards when used in alignment, due to distribution shift. Second, underspecification results in overoptimization, where alignment to one reward model does not improve reward as measured by another reward model trained on the same data. Third, overoptimization is mitigated by the use of reward ensembles, and ensembles that vary by their \emph{pretraining} seeds lead to better generalization than ensembles that differ only by their \emph{fine-tuning} seeds, with both outperforming individual reward models. However, even pretrain reward ensembles do not eliminate reward hacking: we show several qualitative reward hacking phenomena that are not mitigated by ensembling because all reward models in the ensemble exhibit similar error patterns.
Detecting Extrapolation with Local Ensembles
Oct 21, 2019
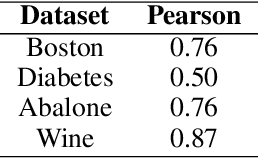
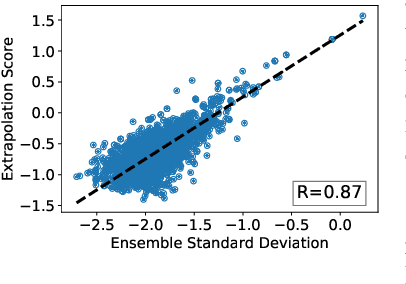
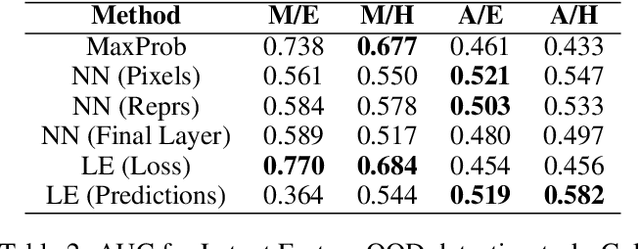
We present local ensembles, a method for detecting extrapolation at test time in a pre-trained model. We focus on underdetermination as a key component of extrapolation: we aim to detect when many possible predictions are consistent with the training data and model class. Our method uses local second-order information to approximate the variance of predictions across an ensemble of models from the same class. We compute this approximation by estimating the norm of the component of a test point's gradient that aligns with the low-curvature directions of the Hessian, and provide a tractable method for estimating this quantity. Experimentally, we show that our method is capable of detecting when a pre-trained model is extrapolating on test data, with applications to out-of-distribution detection, detecting spurious correlates, and active learning.
BriarPatches: Pixel-Space Interventions for Inducing Demographic Parity
Dec 17, 2018
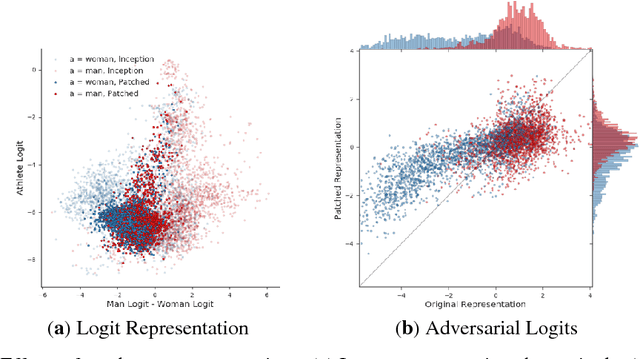
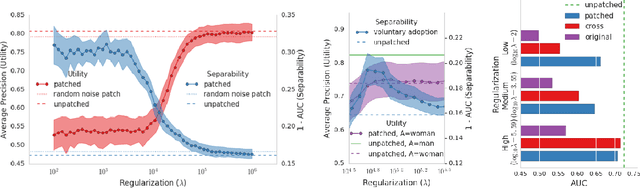
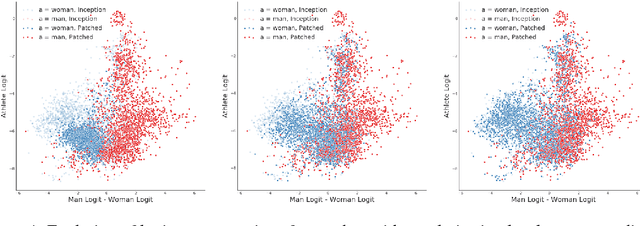
We introduce the BriarPatch, a pixel-space intervention that obscures sensitive attributes from representations encoded in pre-trained classifiers. The patches encourage internal model representations not to encode sensitive information, which has the effect of pushing downstream predictors towards exhibiting demographic parity with respect to the sensitive information. The net result is that these BriarPatches provide an intervention mechanism available at user level, and complements prior research on fair representations that were previously only applicable by model developers and ML experts.