 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Constrained Correlation Filter
Nov 11, 2017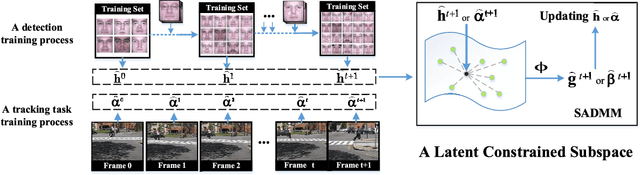
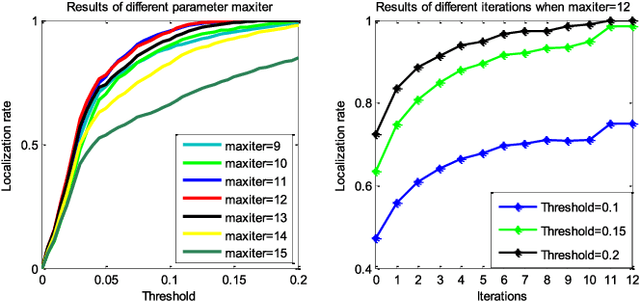
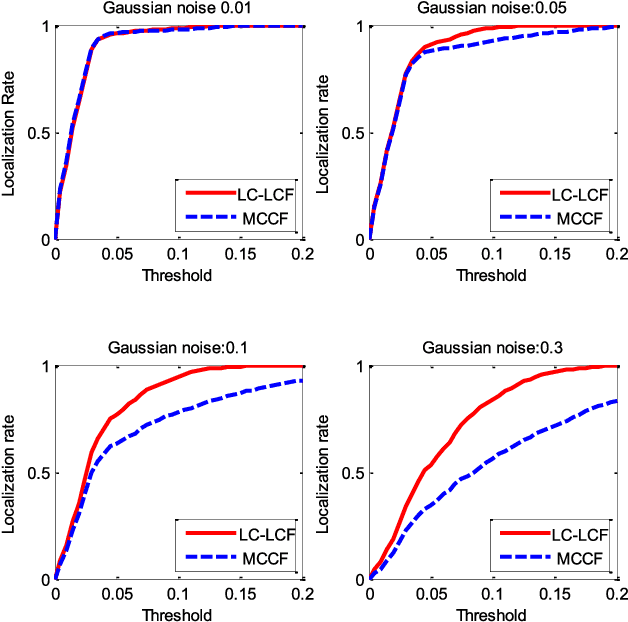
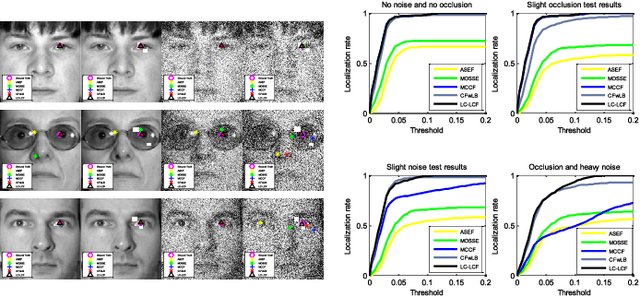
Correlation filters are special classifiers designed for shift-invariant object recognition, which are robust to pattern distortions. The recent literature shows that combining a set of sub-filters trained based on a single or a small group of images obtains the best performance. The idea is equivalent to estimating variable distribution based on the data sampling (bagging), which can be interpreted as finding solutions (variable distribution approximation) directly from sampled data space. However, this methodology fails to account for the variations existed in the data. In this paper, we introduce an intermediate step -- solution sampling -- after the data sampling step to form a subspace, in which an optimal solution can be estimated. More specifically, we propose a new method, named latent constrained correlation filters (LCCF), by mapping the correlation filters to a given latent subspace, and develop a new learning framework in the latent subspace that embeds distribution-related constraints into the original problem. To solve the optimization problem, we introduce a subspace based alternating direction method of multipliers (SADMM), which is proven to converge at the saddle point. Our approach is successfully applied to three different tasks, including eye localization, car detection and object tracking. Extensive experiments demonstrate that LCCF outperforms the state-of-the-art methods. The source code will be publicly available. https://github.com/bczhangbczhang/.
Latent Constrained Correlation Filters for Object Localization
Jun 03, 2017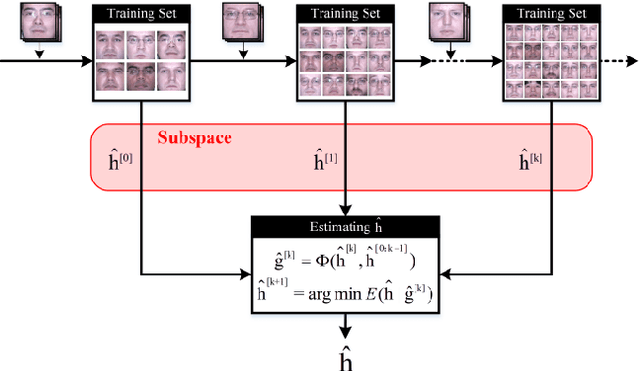
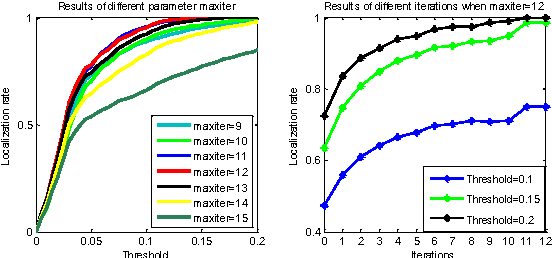
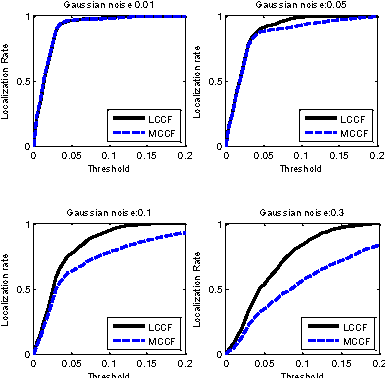
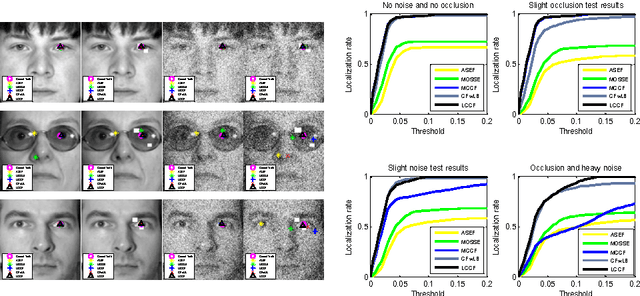
There is a neglected fact in the traditional machine learning methods that the data sampling can actually lead to the solution sampling. We consider this observation to be important because having the solution sampling available makes the variable distribution estimation, which is a problem in many learning-related applications, more tractable. In this paper, we implement this idea on correlation filter, which has attracted much attention in the past few years due to its high performance with a low computational cost. More specifically, we propose a new method, named latent constrained correlation filters (LCCF) by mapping the correlation filters to a given latent subspace, in which we establish a new learning framework that embeds distribution-related constraints into the original problem. We further introduce a subspace based alternating direction method of multipliers (SADMM) to efficiently solve the optimization problem, which is proved to converge at the saddle point. Our approach is successfully applied to two different tasks inclduing eye localization and car detection. Extensive experiments demonstrate that LCCF outperforms the state-of-the-art methods when samples are suffered from noise and occlusion.
Output Constraint Transfer for Kernelized Correlation Filter in Tracking
Dec 16, 2016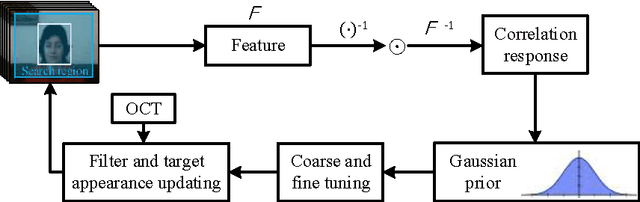
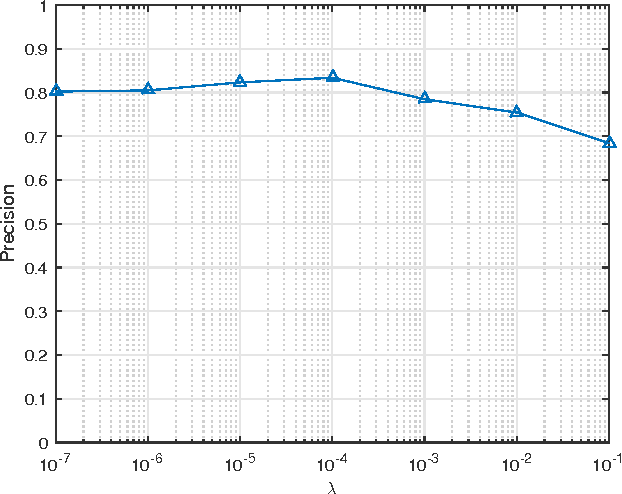

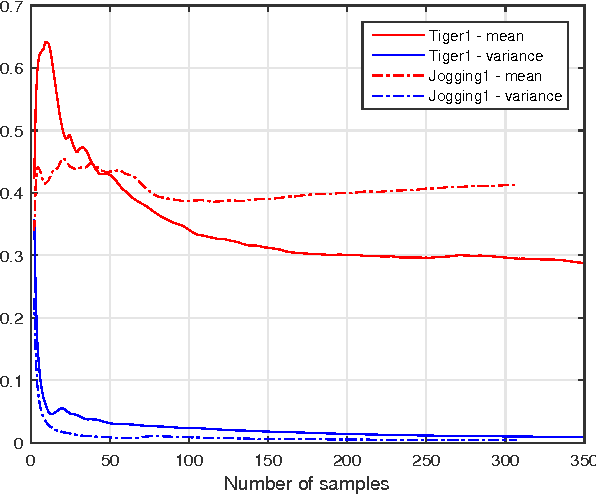
Kernelized Correlation Filter (KCF) is one of the state-of-the-art object trackers. However, it does not reasonably model the distribution of correlation response during tracking process, which might cause the drifting problem, especially when targets undergo significant appearance changes due to occlusion, camera shaking, and/or deformation. In this paper, we propose an Output Constraint Transfer (OCT) method that by modeling the distribution of correlation response in a Bayesian optimization framework is able to mitigate the drifting problem. OCT builds upon the reasonable assumption that the correlation response to the target image follows a Gaussian distribution, which we exploit to select training samples and reduce model uncertainty. OCT is rooted in a new theory which transfers data distribution to a constraint of the optimized variable, leading to an efficient framework to calculate correlation filters. Extensive experiments on a commonly used tracking benchmark show that the proposed method significantly improves KCF, and achieves better performance than other state-of-the-art trackers. To encourage further developments, the source code is made available https://github.com/bczhangbczhang/OCT-KCF.
Hierarchical learning of grids of microtopics
Jun 08, 2016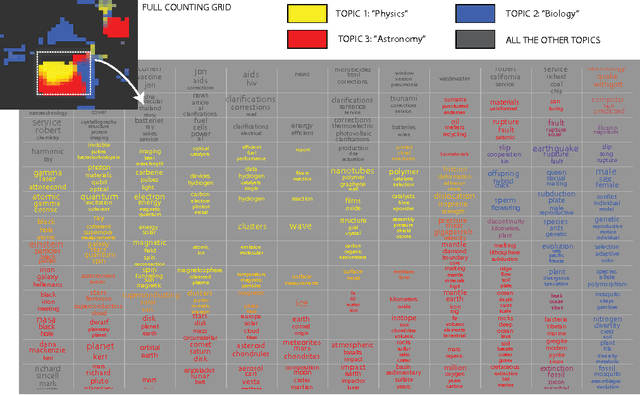

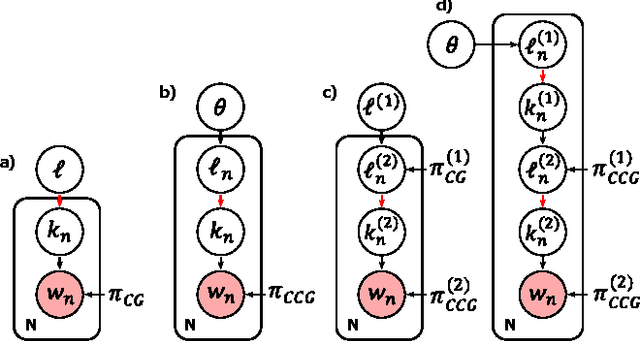
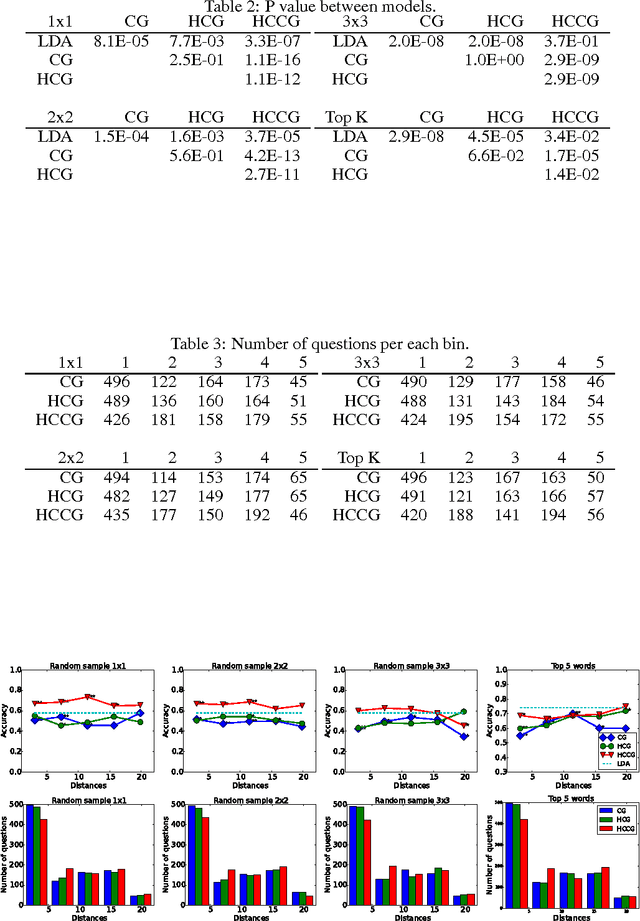
The counting grid is a grid of microtopics, sparse word/feature distributions. The generative model associated with the grid does not use these microtopics individually. Rather, it groups them in overlapping rectangular windows and uses these grouped microtopics as either mixture or admixture components. This paper builds upon the basic counting grid model and it shows that hierarchical reasoning helps avoid bad local minima, produces better classification accuracy and, most interestingly, allows for extraction of large numbers of coherent microtopics even from small datasets. We evaluate this in terms of consistency, diversity and clarity of the indexed content, as well as in a user study on word intrusion tasks. We demonstrate that these models work well as a technique for embedding raw images and discuss interesting parallels between hierarchical CG models and other deep architectures.
3D Pose from Detections
Jul 20, 2015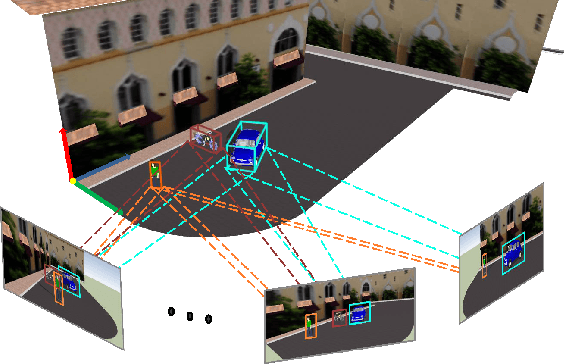


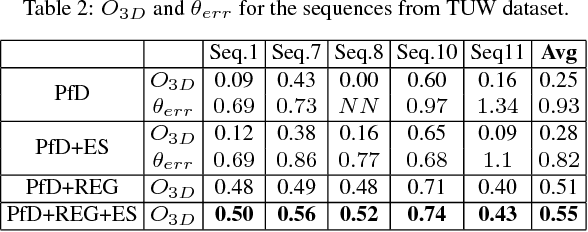
We present a novel method to infer, in closed-form, a general 3D spatial occupancy and orientation of a collection of rigid objects given 2D image detections from a sequence of images. In particular, starting from 2D ellipses fitted to bounding boxes, this novel multi-view problem can be reformulated as the estimation of a quadric (ellipsoid) in 3D. We show that an efficient solution exists in the dual-space using a minimum of three views while a solution with two views is possible through the use of regularization. However, this algebraic solution can be negatively affected in the presence of gross inaccuracies in the bounding boxes estimation. To this end, we also propose a robust ellipse fitting algorithm able to improve performance in the presence of errors in the detected objects. Results on synthetic tests and on different real datasets, involving real challenging scenarios, demonstrate the applicability and potential of our method.
Capturing spatial interdependence in image features: the counting grid, an epitomic representation for bags of features
Oct 23, 2014



In recent scene recognition research images or large image regions are often represented as disorganized "bags" of features which can then be analyzed using models originally developed to capture co-variation of word counts in text. However, image feature counts are likely to be constrained in different ways than word counts in text. For example, as a camera pans upwards from a building entrance over its first few floors and then further up into the sky Fig. 1, some feature counts in the image drop while others rise -- only to drop again giving way to features found more often at higher elevations. The space of all possible feature count combinations is constrained both by the properties of the larger scene and the size and the location of the window into it. To capture such variation, in this paper we propose the use of the counting grid model. This generative model is based on a grid of feature counts, considerably larger than any of the modeled images, and considerably smaller than the real estate needed to tile the images next to each other tightly. Each modeled image is assumed to have a representative window in the grid in which the feature counts mimic the feature distribution in the image. We provide a learning procedure that jointly maps all images in the training set to the counting grid and estimates the appropriate local counts in it. Experimentally, we demonstrate that the resulting representation captures the space of feature count combinations more accurately than the traditional models, not only when the input images come from a panning camera, but even when modeling images of different scenes from the same category.
In the sight of my wearable camera: Classifying my visual experience
Apr 26, 2013



We introduce and we analyze a new dataset which resembles the input to biological vision systems much more than most previously published ones. Our analysis leaded to several important conclusions. First, it is possible to disambiguate over dozens of visual scenes (locations) encountered over the course of several weeks of a human life with accuracy of over 80%, and this opens up possibility for numerous novel vision applications, from early detection of dementia to everyday use of wearable camera streams for automatic reminders, and visual stream exchange. Second, our experimental results indicate that, generative models such as Latent Dirichlet Allocation or Counting Grids, are more suitable to such types of data, as they are more robust to overtraining and comfortable with images at low resolution, blurred and characterized by relatively random clutter and a mix of objects.
Multidimensional counting grids: Inferring word order from disordered bags of words
Feb 14, 2012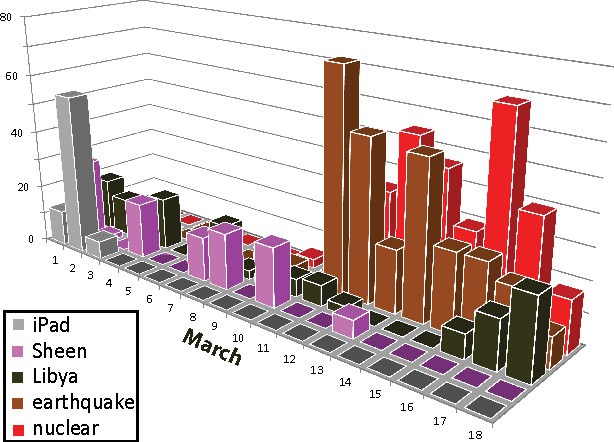
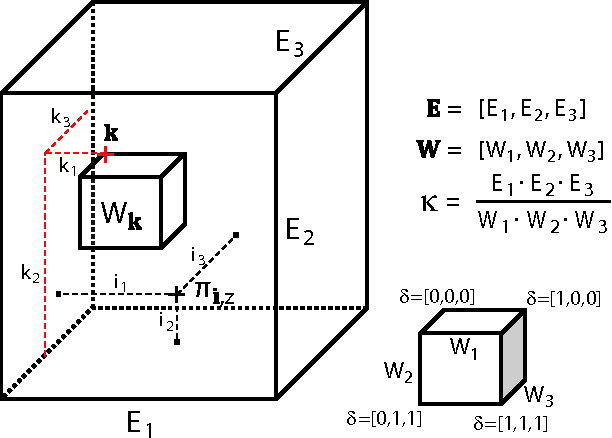
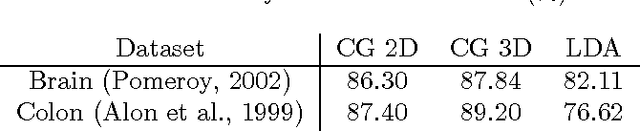
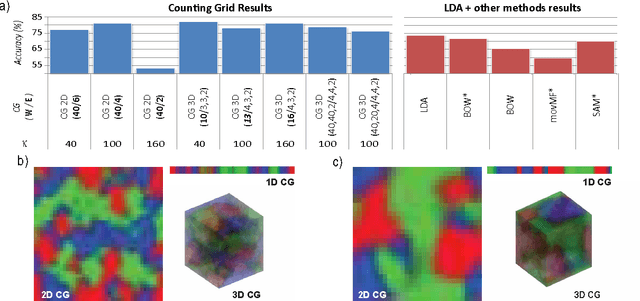
Models of bags of words typically assume topic mixing so that the words in a single bag come from a limited number of topics. We show here that many sets of bag of words exhibit a very different pattern of variation than the patterns that are efficiently captured by topic mixing. In many cases, from one bag of words to the next, the words disappear and new ones appear as if the theme slowly and smoothly shifted across documents (providing that the documents are somehow ordered). Examples of latent structure that describe such ordering are easily imagined. For example, the advancement of the date of the news stories is reflected in a smooth change over the theme of the day as certain evolving news stories fall out of favor and new events create new stories. Overlaps among the stories of consecutive days can be modeled by using windows over linearly arranged tight distributions over words. We show here that such strategy can be extended to multiple dimensions and cases where the ordering of data is not readily obvious. We demonstrate that this way of modeling covariation in word occurrences outperforms standard topic models in classification and prediction tasks in applications in biology, text modeling and computer vision.