 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Heading Prediction for Autonomous Aerial Vehicles
Dec 10, 2025The integration of Unmanned Aerial Vehicles (UAVs) and Unmanned Ground Vehicles (UGVs) is increasingly central to the development of intelligent autonomous systems for applications such as search and rescue, environmental monitoring, and logistics. However, precise coordination between these platforms in real-time scenarios presents major challenges, particularly when external localization infrastructure such as GPS or GNSS is unavailable or degraded [1]. This paper proposes a vision-based, data-driven framework for real-time UAV-UGV integration, with a focus on robust UGV detection and heading angle prediction for navigation and coordination. The system employs a fine-tuned YOLOv5 model to detect UGVs and extract bounding box features, which are then used by a lightweight artificial neural network (ANN) to estimate the UAV's required heading angle. A VICON motion capture system was used to generate ground-truth data during training, resulting in a dataset of over 13,000 annotated images collected in a controlled lab environment. The trained ANN achieves a mean absolute error of 0.1506° and a root mean squared error of 0.1957°, offering accurate heading angle predictions using only monocular camera inputs. Experimental evaluations achieve 95% accuracy in UGV detection. This work contributes a vision-based, infrastructure- independent solution that demonstrates strong potential for deployment in GPS/GNSS-denied environments, supporting reliable multi-agent coordination under realistic dynamic conditions. A demonstration video showcasing the system's real-time performance, including UGV detection, heading angle prediction, and UAV alignment under dynamic conditions, is available at: https://github.com/Kooroshraf/UAV-UGV-Integration
Volatility in Certainty (VC): A Metric for Detecting Adversarial Perturbations During Inference in Neural Network Classifiers
Nov 14, 2025

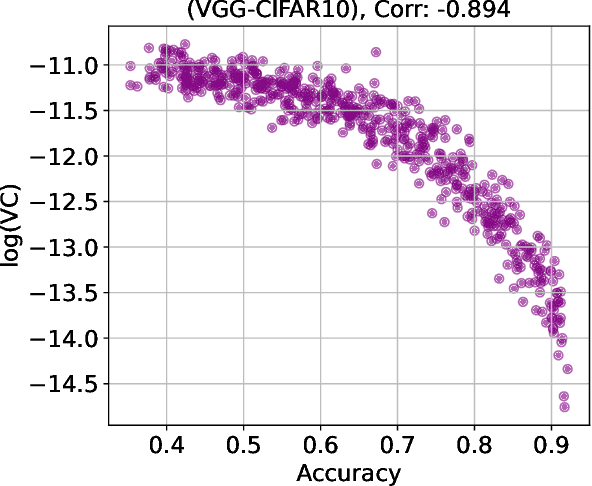

Adversarial robustness remains a critical challenge in deploying neural network classifiers, particularly in real-time systems where ground-truth labels are unavailable during inference. This paper investigates \textit{Volatility in Certainty} (VC), a recently proposed, label-free metric that quantifies irregularities in model confidence by measuring the dispersion of sorted softmax outputs. Specifically, VC is defined as the average squared log-ratio of adjacent certainty values, capturing local fluctuations in model output smoothness. We evaluate VC as a proxy for classification accuracy and as an indicator of adversarial drift. Experiments are conducted on artificial neural networks (ANNs) and convolutional neural networks (CNNs) trained on MNIST, as well as a regularized VGG-like model trained on CIFAR-10. Adversarial examples are generated using the Fast Gradient Sign Method (FGSM) across varying perturbation magnitudes. In addition, mixed test sets are created by gradually introducing adversarial contamination to assess VC's sensitivity under incremental distribution shifts. Our results reveal a strong negative correlation between classification accuracy and log(VC) (correlation rho < -0.90 in most cases), suggesting that VC effectively reflects performance degradation without requiring labeled data. These findings position VC as a scalable, architecture-agnostic, and real-time performance metric suitable for early-warning systems in safety-critical applications.
Negative Selection Approach to support Formal Verification and Validation of BlackBox Models' Input Constraints
Sep 03, 2022
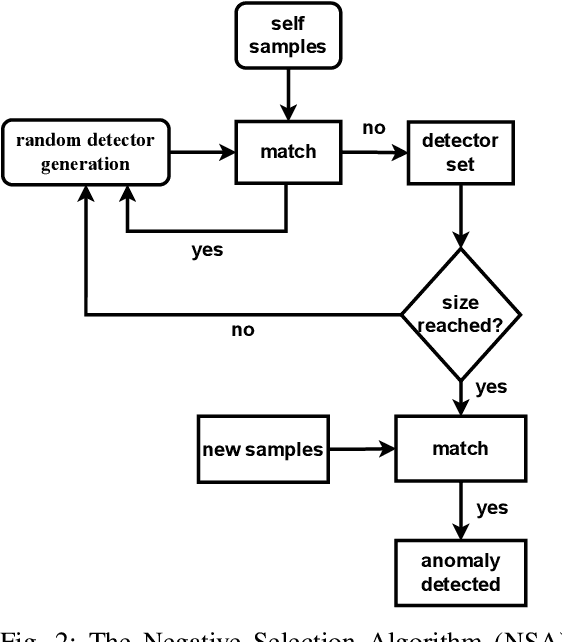
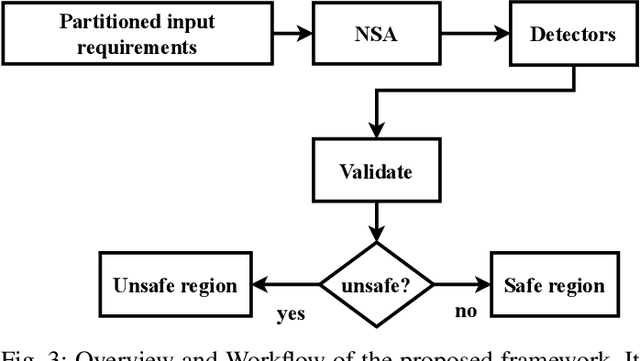
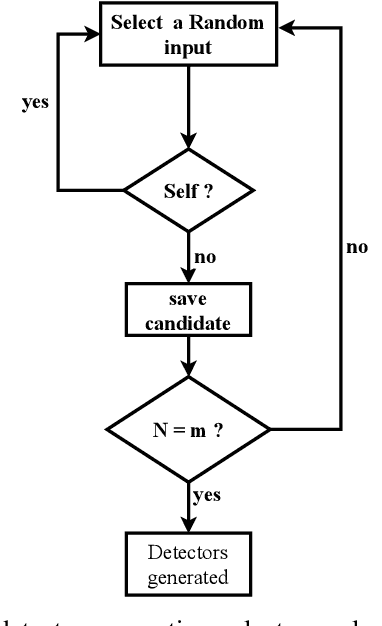
Generating unsafe sub-requirements from a partitioned input space to support verification-guided test cases for formal verification of black-box models is a challenging problem for researchers. The size of the search space makes exhaustive search computationally impractical. This paper investigates a meta-heuristic approach to search for unsafe candidate sub-requirements in partitioned input space. We present a Negative Selection Algorithm (NSA) for identifying the candidates' unsafe regions within given safety properties. The Meta-heuristic capability of the NSA algorithm made it possible to estimate vast unsafe regions while validating a subset of these regions. We utilize a parallel execution of partitioned input space to produce safe areas. The NSA based on the prior knowledge of the safe regions is used to identify candidate unsafe region areas and the Marabou framework is then used to validate the NSA results. Our preliminary experimentation and evaluation show that the procedure finds candidate unsafe sub-requirements when validated with the Marabou framework with high precision.
Mitigating shortage of labeled data using clustering-based active learning with diversity exploration
Jul 06, 2022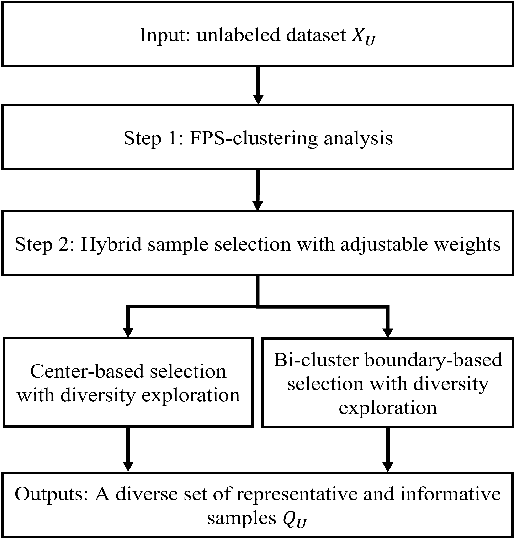
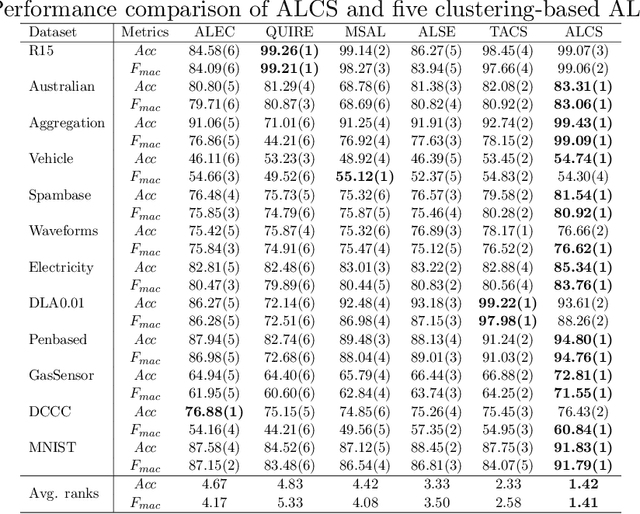
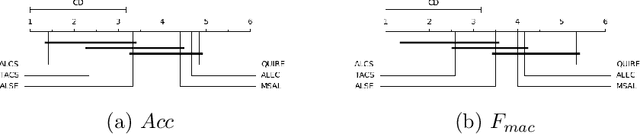
In this paper, we proposed a new clustering-based active learning framework, namely Active Learning using a Clustering-based Sampling (ALCS), to address the shortage of labeled data. ALCS employs a density-based clustering approach to explore the cluster structure from the data without requiring exhaustive parameter tuning. A bi-cluster boundary-based sample query procedure is introduced to improve the learning performance for classifying highly overlapped classes. Additionally, we developed an effective diversity exploration strategy to address the redundancy among queried samples. Our experimental results justified the efficacy of the ALCS approach.
A Robust Completed Local Binary Pattern for Surface Defect Detection
Dec 07, 2021
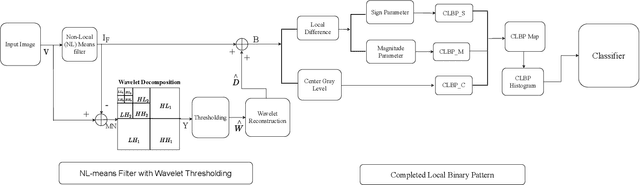

In this paper, we present a Robust Completed Local Binary Pattern (RCLBP) framework for a surface defect detection task. Our approach uses a combination of Non-Local (NL) means filter with wavelet thresholding and Completed Local Binary Pattern (CLBP) to extract robust features which are fed into classifiers for surface defects detection. This paper combines three components: A denoising technique based on Non-Local (NL) means filter with wavelet thresholding is established to denoise the noisy image while preserving the textures and edges. Second, discriminative features are extracted using the CLBP technique. Finally, the discriminative features are fed into the classifiers to build the detection model and evaluate the performance of the proposed framework. The performance of the defect detection models are evaluated using a real-world steel surface defect database from Northeastern University (NEU). Experimental results demonstrate that the proposed approach RCLBP is noise robust and can be applied for surface defect detection under varying conditions of intra-class and inter-class changes and with illumination changes.
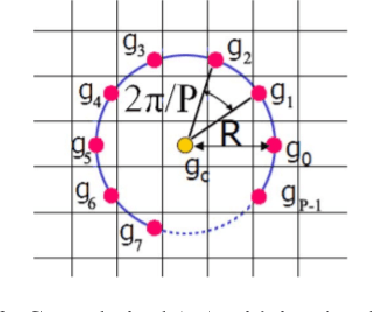
DA$^{\textbf{2}}$-Net : Diverse & Adaptive Attention Convolutional Neural Network
Nov 25, 2021
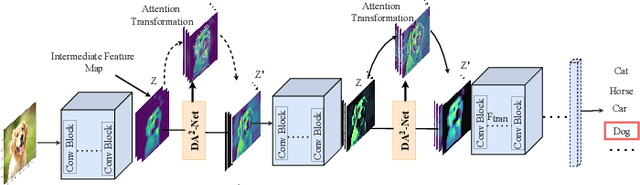

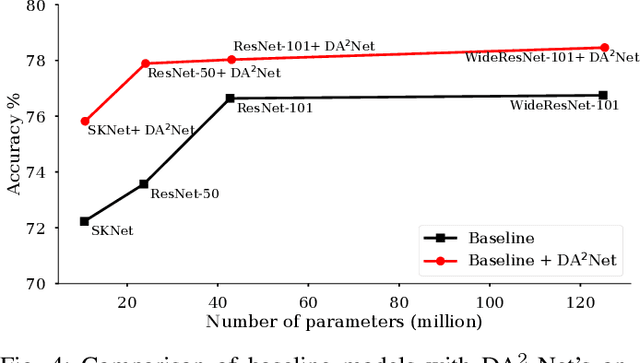
Standard Convolutional Neural Network (CNN) designs rarely focus on the importance of explicitly capturing diverse features to enhance the network's performance. Instead, most existing methods follow an indirect approach of increasing or tuning the networks' depth and width, which in many cases significantly increases the computational cost. Inspired by a biological visual system, we propose a Diverse and Adaptive Attention Convolutional Network (DA$^{2}$-Net), which enables any feed-forward CNNs to explicitly capture diverse features and adaptively select and emphasize the most informative features to efficiently boost the network's performance. DA$^{2}$-Net incurs negligible computational overhead and it is designed to be easily integrated with any CNN architecture. We extensively evaluated DA$^{2}$-Net on benchmark datasets, including CIFAR100, SVHN, and ImageNet, with various CNN architectures. The experimental results show DA$^{2}$-Net provides a significant performance improvement with very minimal computational overhead.
A Software Tool for Evaluating Unmanned Autonomous Systems
Nov 21, 2021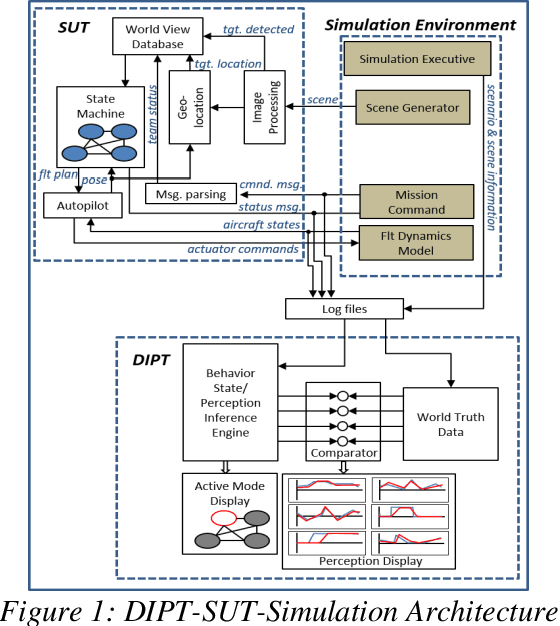

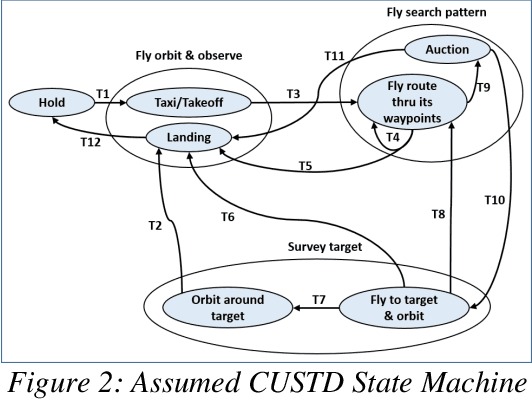
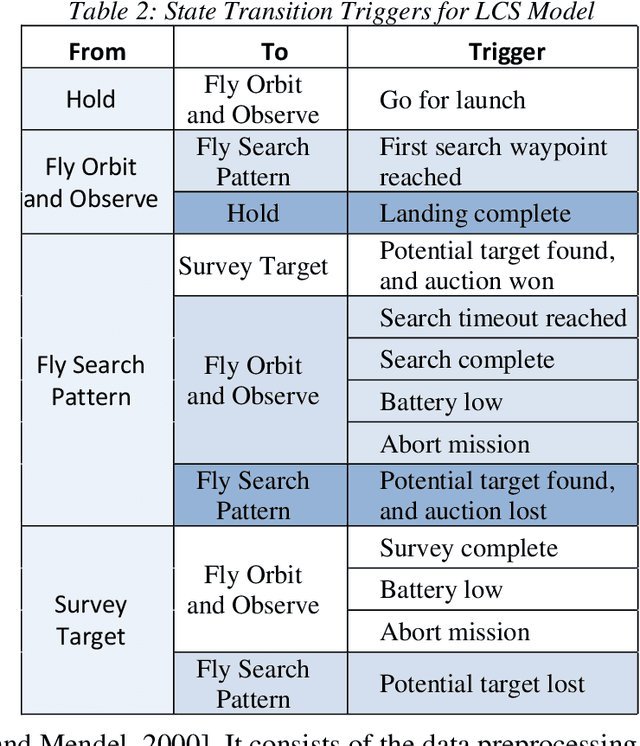
The North Carolina Agriculture and Technical State University (NC A&T) in collaboration with Georgia Tech Research Institute (GTRI) has developed methodologies for creating simulation-based technology tools that are capable of inferring the perceptions and behavioral states of autonomous systems. These methodologies have the potential to provide the Test and Evaluation (T&E) community at the Department of Defense (DoD) with a greater insight into the internal processes of these systems. The methodologies use only external observations and do not require complete knowledge of the internal processing of and/or any modifications to the system under test. This paper presents an example of one such simulation-based technology tool, named as the Data-Driven Intelligent Prediction Tool (DIPT). DIPT was developed for testing a multi-platform Unmanned Aerial Vehicle (UAV) system capable of conducting collaborative search missions. DIPT's Graphical User Interface (GUI) enables the testers to view the aircraft's current operating state, predicts its current target-detection status, and provides reasoning for exhibiting a particular behavior along with an explanation of assigning a particular task to it.
A Supervised Feature Selection Method For Mixed-Type Data using Density-based Feature Clustering
Nov 10, 2021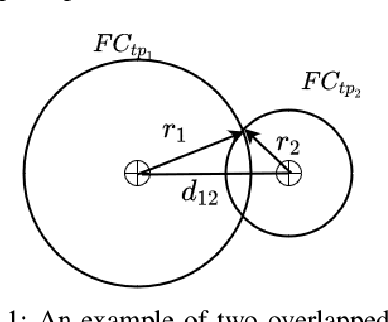


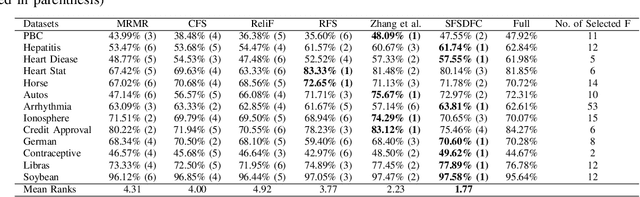
Feature selection methods are widely used to address the high computational overheads and curse of dimensionality in classifying high-dimensional data. Most conventional feature selection methods focus on handling homogeneous features, while real-world datasets usually have a mixture of continuous and discrete features. Some recent mixed-type feature selection studies only select features with high relevance to class labels and ignore the redundancy among features. The determination of an appropriate feature subset is also a challenge. In this paper, a supervised feature selection method using density-based feature clustering (SFSDFC) is proposed to obtain an appropriate final feature subset for mixed-type data. SFSDFC decomposes the feature space into a set of disjoint feature clusters using a novel density-based clustering method. Then, an effective feature selection strategy is employed to obtain a subset of important features with minimal redundancy from those feature clusters. Extensive experiments as well as comparison studies with five state-of-the-art methods are conducted on SFSDFC using thirteen real-world benchmark datasets and results justify the efficacy of the SFSDFC method.
A Framework for eVTOL Performance Evaluation in Urban Air Mobility Realm
Nov 09, 2021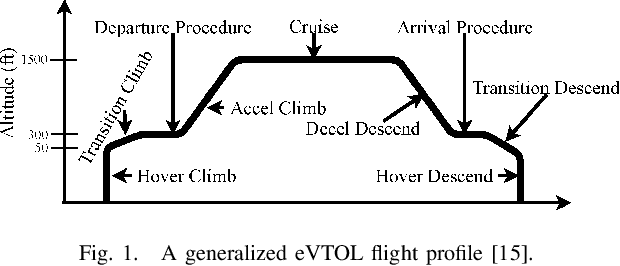
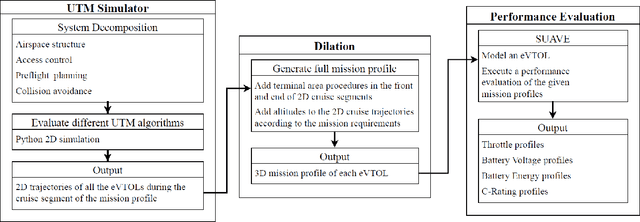

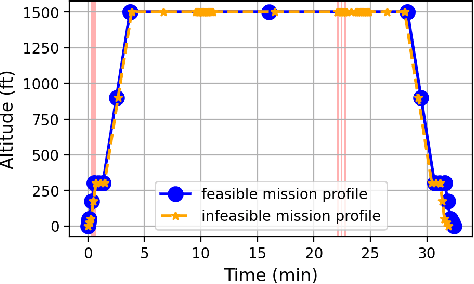
In this paper, we developed a generalized simulation framework for the evaluation of electric vertical takeoff and landing vehicles (eVTOLs) in the context of Unmanned Aircraft Systems (UAS) Traffic Management (UTM) and under the concept of Urban Air Mobility (UAM). Unlike most existing studies, the proposed framework combines the utilization of UTM and eVTOLs to develop a realistic UAM testing platform. For this purpose, we first enhanced an existing UTM simulator to simulate the real-world UAM environment. Then, instead of using a simplified eVOTL model, a realistic eVTOL design tool, namely SUAVE, is employed and an dilation sub-module is introduced to bridge the gap between the UTM simulator and SUAVE eVTOL performance evaluation tool to elaborate the complete mission profile. Based on the developed simulation framework, experiments are conducted and the results are presented to analyze the performance of eVTOLs in the UAM environment.
A Clustering-based Framework for Classifying Data Streams
Jun 22, 2021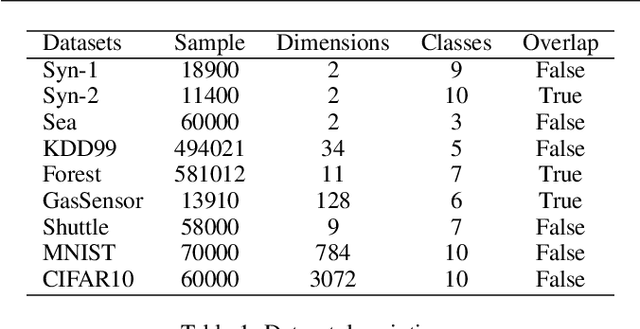
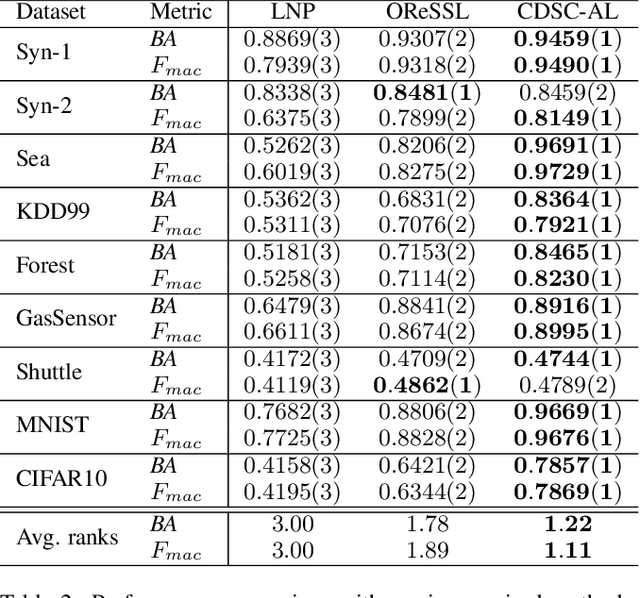
The non-stationary nature of data streams strongly challenges traditional machine learning techniques. Although some solutions have been proposed to extend traditional machine learning techniques for handling data streams, these approaches either require an initial label set or rely on specialized design parameters. The overlap among classes and the labeling of data streams constitute other major challenges for classifying data streams. In this paper, we proposed a clustering-based data stream classification framework to handle non-stationary data streams without utilizing an initial label set. A density-based stream clustering procedure is used to capture novel concepts with a dynamic threshold and an effective active label querying strategy is introduced to continuously learn the new concepts from the data streams. The sub-cluster structure of each cluster is explored to handle the overlap among classes. Experimental results and quantitative comparison studies reveal that the proposed method provides statistically better or comparable performance than the existing methods.