 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating shortage of labeled data using clustering-based active learning with diversity exploration
Jul 06, 2022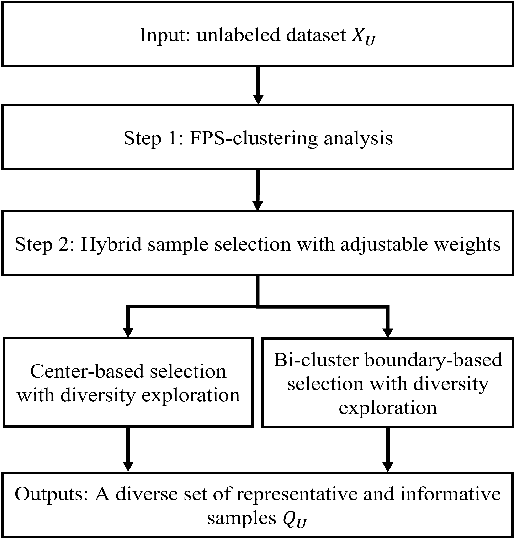
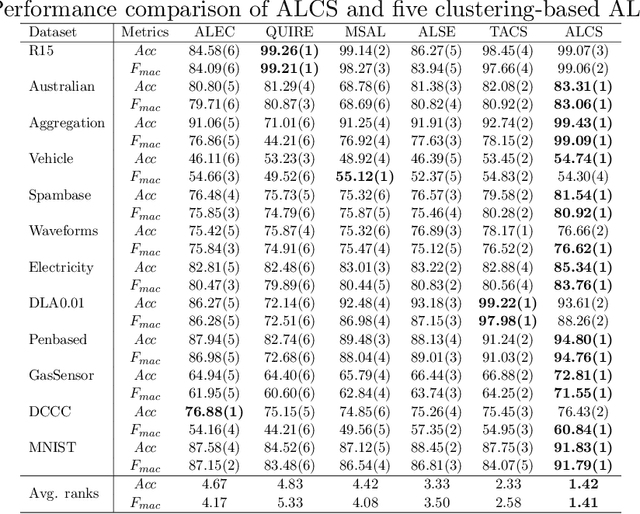
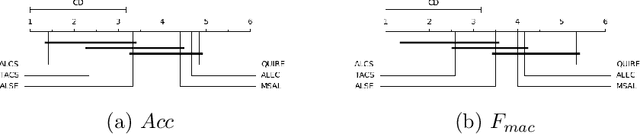
In this paper, we proposed a new clustering-based active learning framework, namely Active Learning using a Clustering-based Sampling (ALCS), to address the shortage of labeled data. ALCS employs a density-based clustering approach to explore the cluster structure from the data without requiring exhaustive parameter tuning. A bi-cluster boundary-based sample query procedure is introduced to improve the learning performance for classifying highly overlapped classes. Additionally, we developed an effective diversity exploration strategy to address the redundancy among queried samples. Our experimental results justified the efficacy of the ALCS approach.
A Supervised Feature Selection Method For Mixed-Type Data using Density-based Feature Clustering
Nov 10, 2021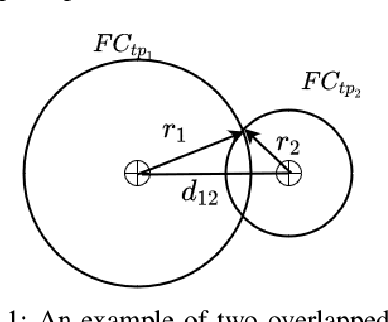


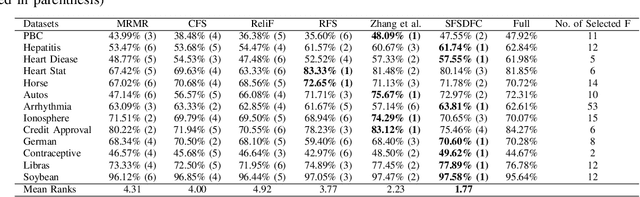
Feature selection methods are widely used to address the high computational overheads and curse of dimensionality in classifying high-dimensional data. Most conventional feature selection methods focus on handling homogeneous features, while real-world datasets usually have a mixture of continuous and discrete features. Some recent mixed-type feature selection studies only select features with high relevance to class labels and ignore the redundancy among features. The determination of an appropriate feature subset is also a challenge. In this paper, a supervised feature selection method using density-based feature clustering (SFSDFC) is proposed to obtain an appropriate final feature subset for mixed-type data. SFSDFC decomposes the feature space into a set of disjoint feature clusters using a novel density-based clustering method. Then, an effective feature selection strategy is employed to obtain a subset of important features with minimal redundancy from those feature clusters. Extensive experiments as well as comparison studies with five state-of-the-art methods are conducted on SFSDFC using thirteen real-world benchmark datasets and results justify the efficacy of the SFSDFC method.