 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating shortage of labeled data using clustering-based active learning with diversity exploration
Jul 06, 2022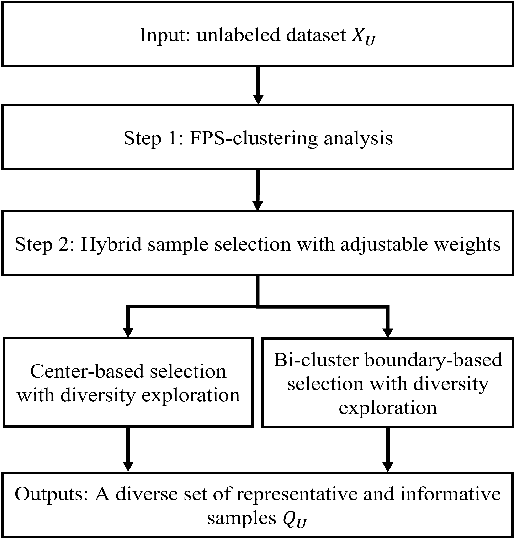
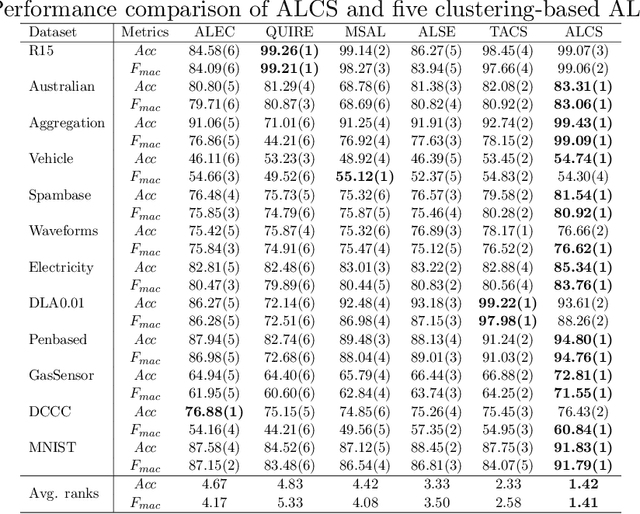
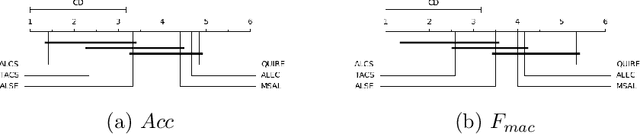
In this paper, we proposed a new clustering-based active learning framework, namely Active Learning using a Clustering-based Sampling (ALCS), to address the shortage of labeled data. ALCS employs a density-based clustering approach to explore the cluster structure from the data without requiring exhaustive parameter tuning. A bi-cluster boundary-based sample query procedure is introduced to improve the learning performance for classifying highly overlapped classes. Additionally, we developed an effective diversity exploration strategy to address the redundancy among queried samples. Our experimental results justified the efficacy of the ALCS approach.
A Software Tool for Evaluating Unmanned Autonomous Systems
Nov 21, 2021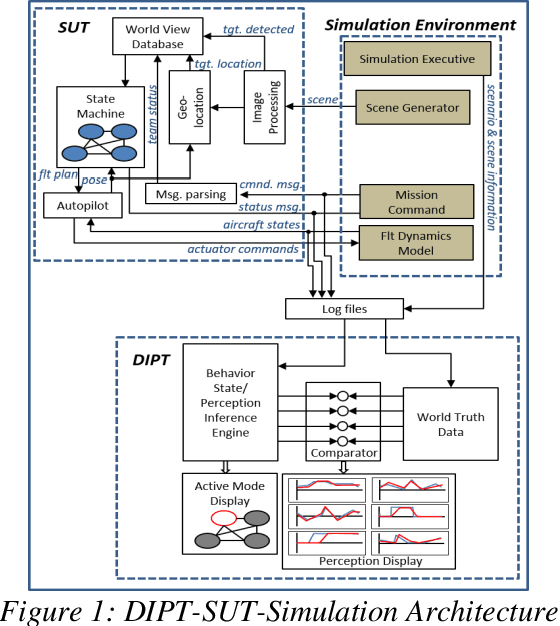

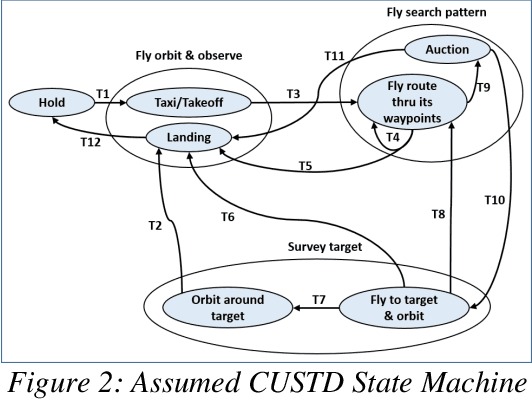
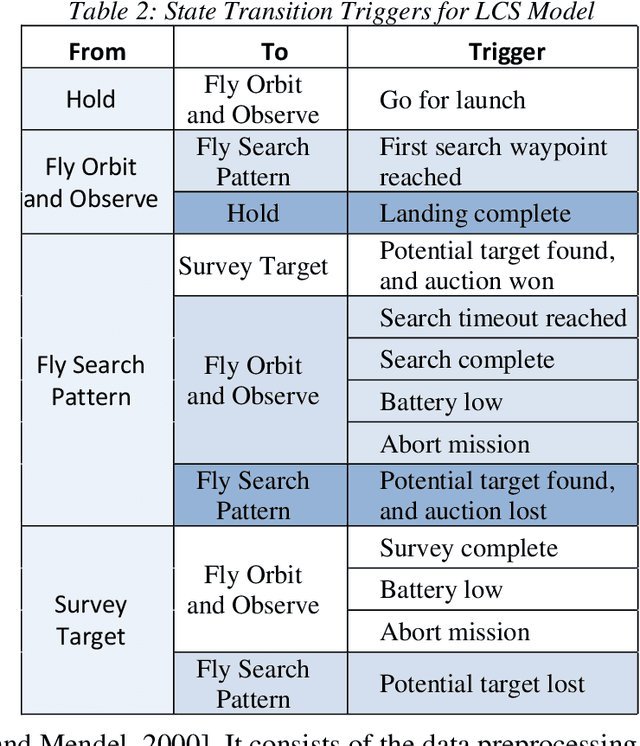
The North Carolina Agriculture and Technical State University (NC A&T) in collaboration with Georgia Tech Research Institute (GTRI) has developed methodologies for creating simulation-based technology tools that are capable of inferring the perceptions and behavioral states of autonomous systems. These methodologies have the potential to provide the Test and Evaluation (T&E) community at the Department of Defense (DoD) with a greater insight into the internal processes of these systems. The methodologies use only external observations and do not require complete knowledge of the internal processing of and/or any modifications to the system under test. This paper presents an example of one such simulation-based technology tool, named as the Data-Driven Intelligent Prediction Tool (DIPT). DIPT was developed for testing a multi-platform Unmanned Aerial Vehicle (UAV) system capable of conducting collaborative search missions. DIPT's Graphical User Interface (GUI) enables the testers to view the aircraft's current operating state, predicts its current target-detection status, and provides reasoning for exhibiting a particular behavior along with an explanation of assigning a particular task to it.
A Supervised Feature Selection Method For Mixed-Type Data using Density-based Feature Clustering
Nov 10, 2021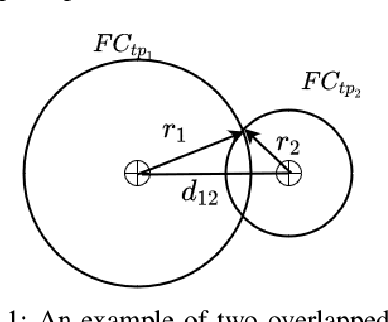


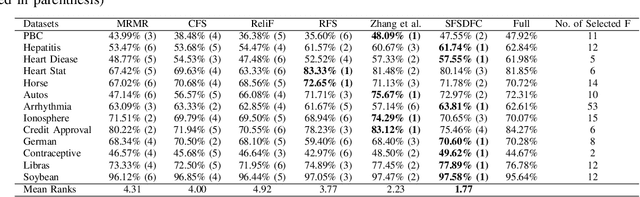
Feature selection methods are widely used to address the high computational overheads and curse of dimensionality in classifying high-dimensional data. Most conventional feature selection methods focus on handling homogeneous features, while real-world datasets usually have a mixture of continuous and discrete features. Some recent mixed-type feature selection studies only select features with high relevance to class labels and ignore the redundancy among features. The determination of an appropriate feature subset is also a challenge. In this paper, a supervised feature selection method using density-based feature clustering (SFSDFC) is proposed to obtain an appropriate final feature subset for mixed-type data. SFSDFC decomposes the feature space into a set of disjoint feature clusters using a novel density-based clustering method. Then, an effective feature selection strategy is employed to obtain a subset of important features with minimal redundancy from those feature clusters. Extensive experiments as well as comparison studies with five state-of-the-art methods are conducted on SFSDFC using thirteen real-world benchmark datasets and results justify the efficacy of the SFSDFC method.
Evolving Multi-label Classification Rules by Exploiting High-order Label Correlation
Jul 22, 2020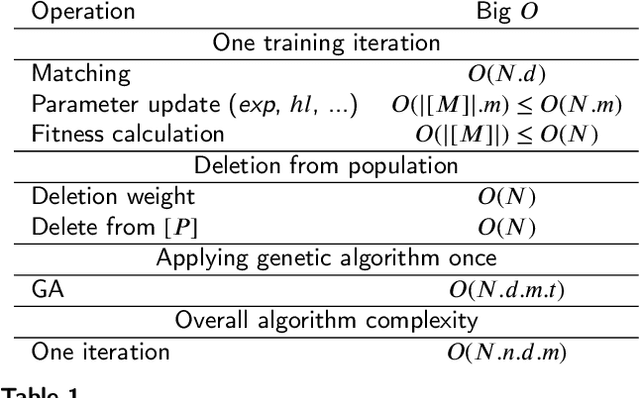
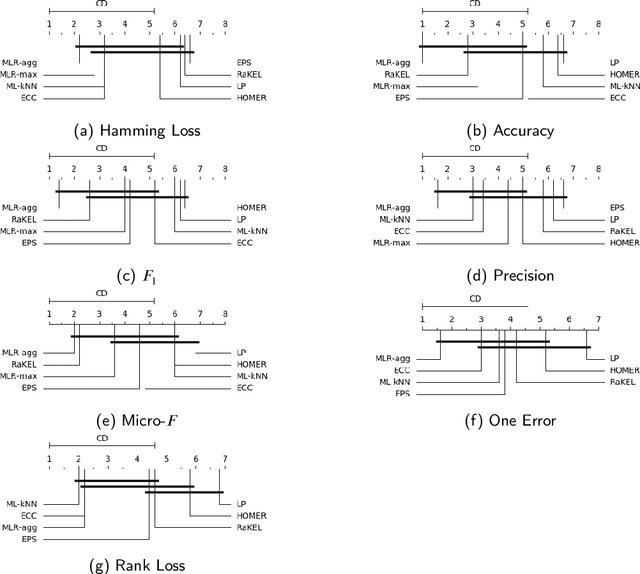
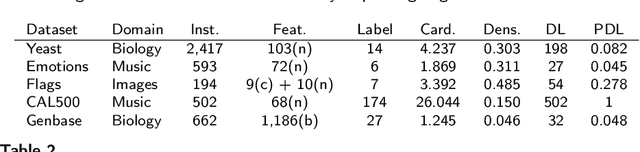

In multi-label classification tasks, each problem instance is associated with multiple classes simultaneously. In such settings, the correlation between labels contains valuable information that can be used to obtain more accurate classification models. The correlation between labels can be exploited at different levels such as capturing the pair-wise correlation or exploiting the higher-order correlations. Even though the high-order approach is more capable of modeling the correlation, it is computationally more demanding and has scalability issues. This paper aims at exploiting the high-order label correlation within subsets of labels using a supervised learning classifier system (UCS). For this purpose, the label powerset (LP) strategy is employed and a prediction aggregation within the set of the relevant labels to an unseen instance is utilized to increase the prediction capability of the LP method in the presence of unseen labelsets. Exact match ratio and Hamming loss measures are considered to evaluate the rule performance and the expected fitness value of a classifier is investigated for both metrics. Also, a computational complexity analysis is provided for the proposed algorithm. The experimental results of the proposed method are compared with other well-known LP-based methods on multiple benchmark datasets and confirm the competitive performance of this method.