 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Stone Toolmaking Action Grammar (HSTAG): A Challenging Benchmark for Fine-grained Motor Behavior Recognition
Oct 10, 2024Action recognition has witnessed the development of a growing number of novel algorithms and datasets in the past decade. However, the majority of public benchmarks were constructed around activities of daily living and annotated at a rather coarse-grained level, which lacks diversity in domain-specific datasets, especially for rarely seen domains. In this paper, we introduced Human Stone Toolmaking Action Grammar (HSTAG), a meticulously annotated video dataset showcasing previously undocumented stone toolmaking behaviors, which can be used for investigating the applications of advanced artificial intelligence techniques in understanding a rapid succession of complex interactions between two hand-held objects. HSTAG consists of 18,739 video clips that record 4.5 hours of experts' activities in stone toolmaking. Its unique features include (i) brief action durations and frequent transitions, mirroring the rapid changes inherent in many motor behaviors; (ii) multiple angles of view and switches among multiple tools, increasing intra-class variability; (iii) unbalanced class distributions and high similarity among different action sequences, adding difficulty in capturing distinct patterns for each action. Several mainstream action recognition models are used to conduct experimental analysis, which showcases the challenges and uniqueness of HSTAG https://nyu.databrary.org/volume/1697.
Mitigating shortage of labeled data using clustering-based active learning with diversity exploration
Jul 06, 2022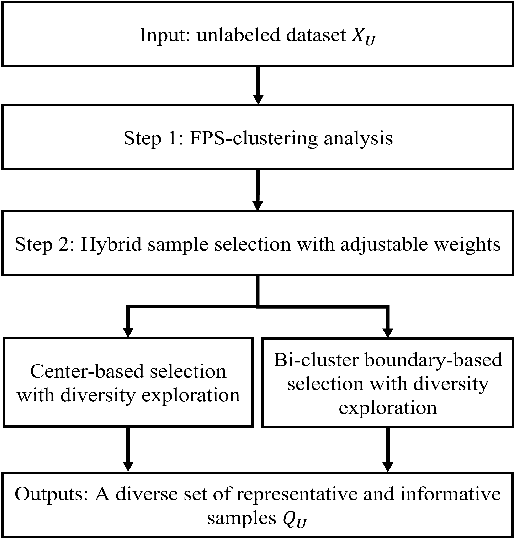
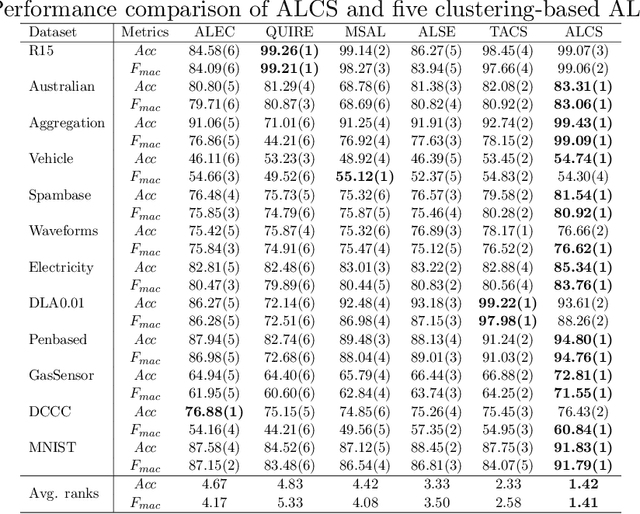
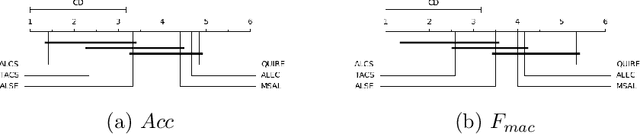
In this paper, we proposed a new clustering-based active learning framework, namely Active Learning using a Clustering-based Sampling (ALCS), to address the shortage of labeled data. ALCS employs a density-based clustering approach to explore the cluster structure from the data without requiring exhaustive parameter tuning. A bi-cluster boundary-based sample query procedure is introduced to improve the learning performance for classifying highly overlapped classes. Additionally, we developed an effective diversity exploration strategy to address the redundancy among queried samples. Our experimental results justified the efficacy of the ALCS approach.
DA$^{\textbf{2}}$-Net : Diverse & Adaptive Attention Convolutional Neural Network
Nov 25, 2021
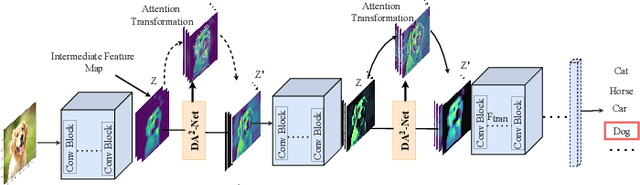

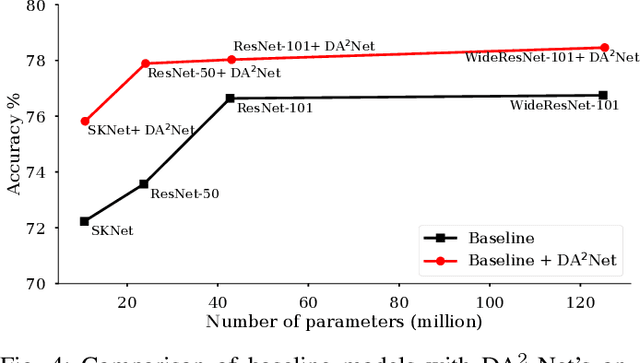
Standard Convolutional Neural Network (CNN) designs rarely focus on the importance of explicitly capturing diverse features to enhance the network's performance. Instead, most existing methods follow an indirect approach of increasing or tuning the networks' depth and width, which in many cases significantly increases the computational cost. Inspired by a biological visual system, we propose a Diverse and Adaptive Attention Convolutional Network (DA$^{2}$-Net), which enables any feed-forward CNNs to explicitly capture diverse features and adaptively select and emphasize the most informative features to efficiently boost the network's performance. DA$^{2}$-Net incurs negligible computational overhead and it is designed to be easily integrated with any CNN architecture. We extensively evaluated DA$^{2}$-Net on benchmark datasets, including CIFAR100, SVHN, and ImageNet, with various CNN architectures. The experimental results show DA$^{2}$-Net provides a significant performance improvement with very minimal computational overhead.
A Supervised Feature Selection Method For Mixed-Type Data using Density-based Feature Clustering
Nov 10, 2021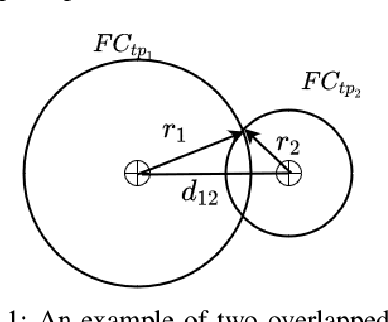


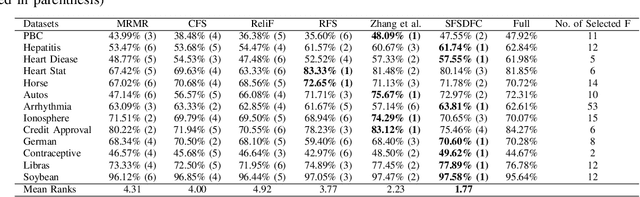
Feature selection methods are widely used to address the high computational overheads and curse of dimensionality in classifying high-dimensional data. Most conventional feature selection methods focus on handling homogeneous features, while real-world datasets usually have a mixture of continuous and discrete features. Some recent mixed-type feature selection studies only select features with high relevance to class labels and ignore the redundancy among features. The determination of an appropriate feature subset is also a challenge. In this paper, a supervised feature selection method using density-based feature clustering (SFSDFC) is proposed to obtain an appropriate final feature subset for mixed-type data. SFSDFC decomposes the feature space into a set of disjoint feature clusters using a novel density-based clustering method. Then, an effective feature selection strategy is employed to obtain a subset of important features with minimal redundancy from those feature clusters. Extensive experiments as well as comparison studies with five state-of-the-art methods are conducted on SFSDFC using thirteen real-world benchmark datasets and results justify the efficacy of the SFSDFC method.
A Framework for eVTOL Performance Evaluation in Urban Air Mobility Realm
Nov 09, 2021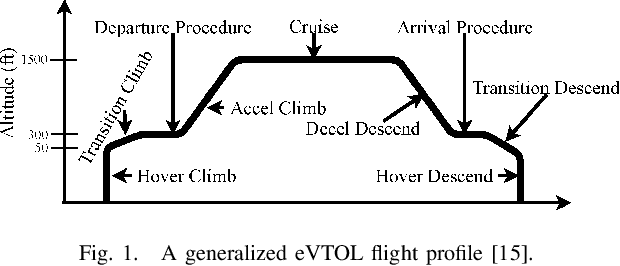
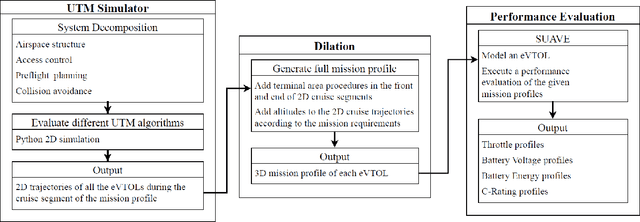

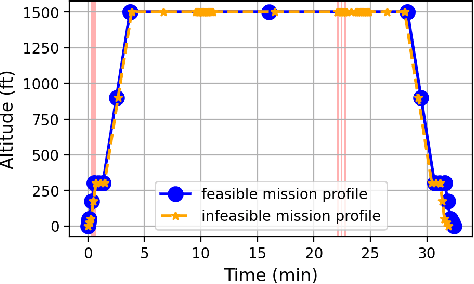
In this paper, we developed a generalized simulation framework for the evaluation of electric vertical takeoff and landing vehicles (eVTOLs) in the context of Unmanned Aircraft Systems (UAS) Traffic Management (UTM) and under the concept of Urban Air Mobility (UAM). Unlike most existing studies, the proposed framework combines the utilization of UTM and eVTOLs to develop a realistic UAM testing platform. For this purpose, we first enhanced an existing UTM simulator to simulate the real-world UAM environment. Then, instead of using a simplified eVOTL model, a realistic eVTOL design tool, namely SUAVE, is employed and an dilation sub-module is introduced to bridge the gap between the UTM simulator and SUAVE eVTOL performance evaluation tool to elaborate the complete mission profile. Based on the developed simulation framework, experiments are conducted and the results are presented to analyze the performance of eVTOLs in the UAM environment.
A Clustering-based Framework for Classifying Data Streams
Jun 22, 2021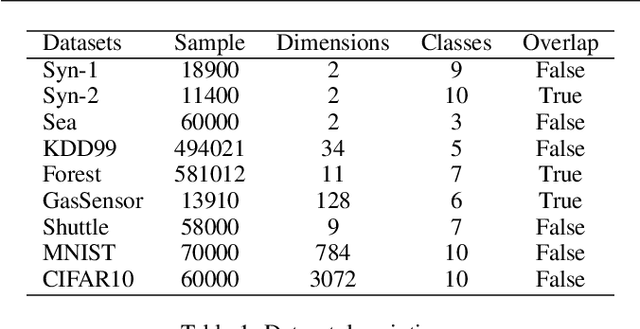
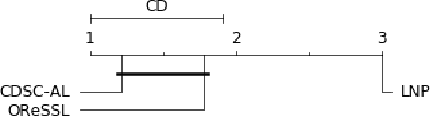
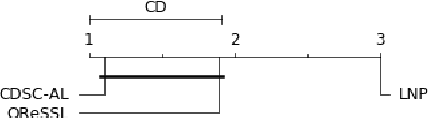
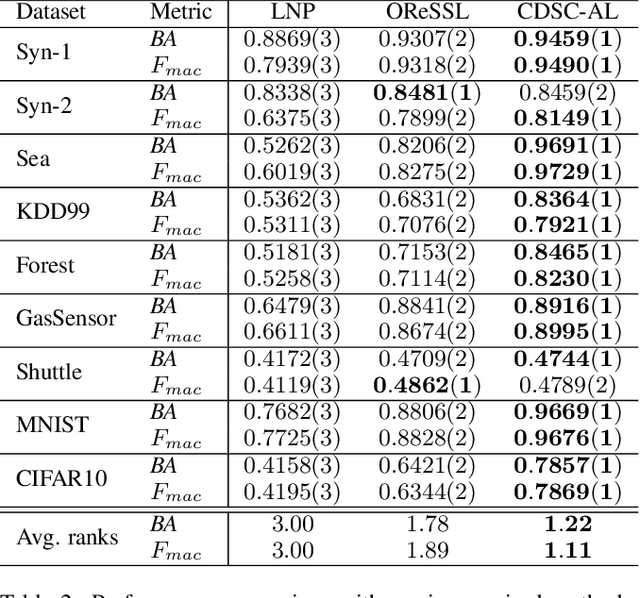
The non-stationary nature of data streams strongly challenges traditional machine learning techniques. Although some solutions have been proposed to extend traditional machine learning techniques for handling data streams, these approaches either require an initial label set or rely on specialized design parameters. The overlap among classes and the labeling of data streams constitute other major challenges for classifying data streams. In this paper, we proposed a clustering-based data stream classification framework to handle non-stationary data streams without utilizing an initial label set. A density-based stream clustering procedure is used to capture novel concepts with a dynamic threshold and an effective active label querying strategy is introduced to continuously learn the new concepts from the data streams. The sub-cluster structure of each cluster is explored to handle the overlap among classes. Experimental results and quantitative comparison studies reveal that the proposed method provides statistically better or comparable performance than the existing methods.
Evolving Multi-label Classification Rules by Exploiting High-order Label Correlation
Jul 22, 2020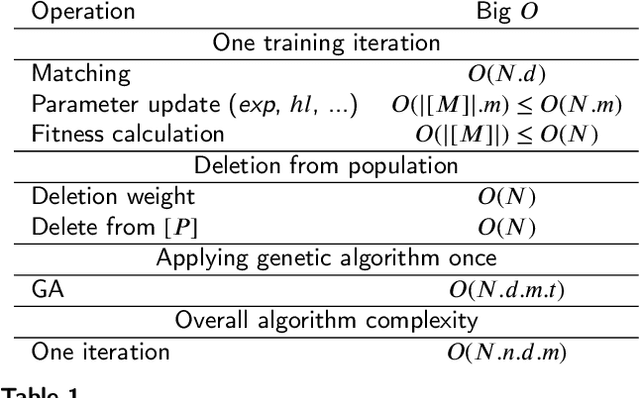
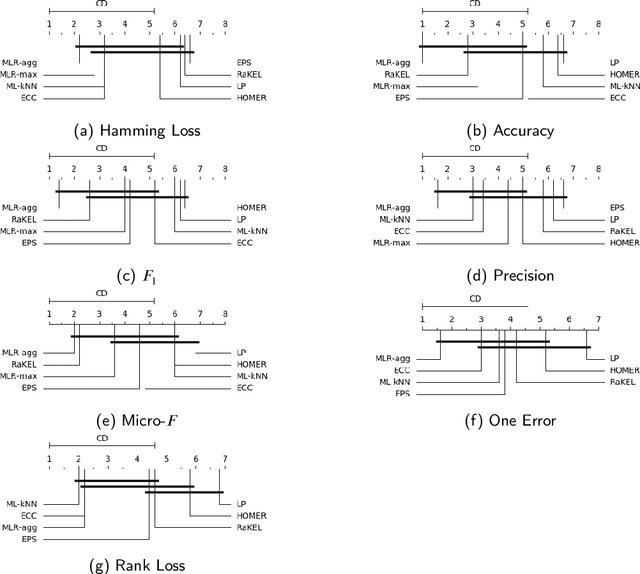
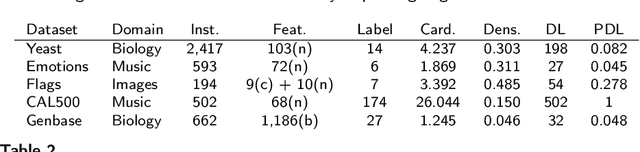

In multi-label classification tasks, each problem instance is associated with multiple classes simultaneously. In such settings, the correlation between labels contains valuable information that can be used to obtain more accurate classification models. The correlation between labels can be exploited at different levels such as capturing the pair-wise correlation or exploiting the higher-order correlations. Even though the high-order approach is more capable of modeling the correlation, it is computationally more demanding and has scalability issues. This paper aims at exploiting the high-order label correlation within subsets of labels using a supervised learning classifier system (UCS). For this purpose, the label powerset (LP) strategy is employed and a prediction aggregation within the set of the relevant labels to an unseen instance is utilized to increase the prediction capability of the LP method in the presence of unseen labelsets. Exact match ratio and Hamming loss measures are considered to evaluate the rule performance and the expected fitness value of a classifier is investigated for both metrics. Also, a computational complexity analysis is provided for the proposed algorithm. The experimental results of the proposed method are compared with other well-known LP-based methods on multiple benchmark datasets and confirm the competitive performance of this method.
Driver Identification Based on Vehicle Telematics Data using LSTM-Recurrent Neural Network
Nov 19, 2019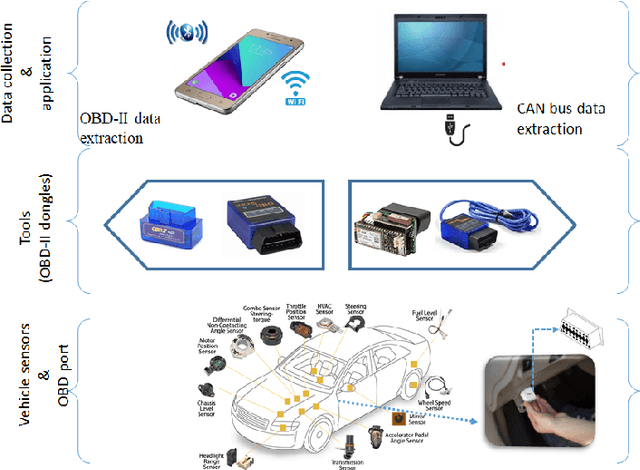
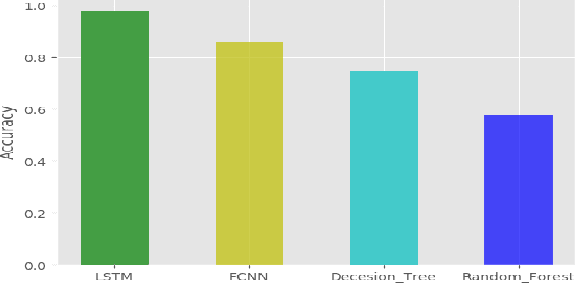
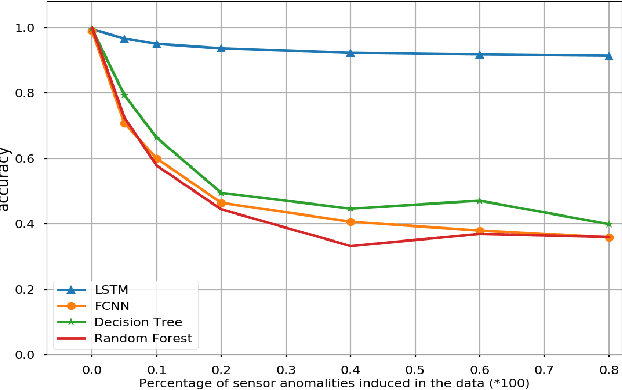
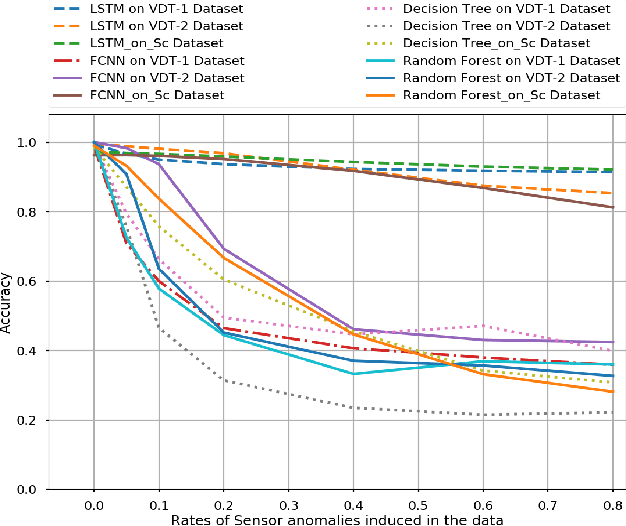
Despite advancements in vehicle security systems, over the last decade, auto-theft rates have increased, and cyber-security attacks on internet-connected and autonomous vehicles are becoming a new threat. In this paper, a deep learning model is proposed, which can identify drivers from their driving behaviors based on vehicle telematics data. The proposed Long-Short-Term-Memory (LSTM) model predicts the identity of the driver based on the individual's unique driving patterns learned from the vehicle telematics data. Given the telematics is time-series data, the problem is formulated as a time series prediction task to exploit the embedded sequential information. The performance of the proposed approach is evaluated on three naturalistic driving datasets, which gives high accuracy prediction results. The robustness of the model on noisy and anomalous data that is usually caused by sensor defects or environmental factors is also investigated. Results show that the proposed model prediction accuracy remains satisfactory and outperforms the other approaches despite the extent of anomalies and noise-induced in the data.