 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Supervised Feature Selection Method For Mixed-Type Data using Density-based Feature Clustering
Paper and Code
Nov 10, 2021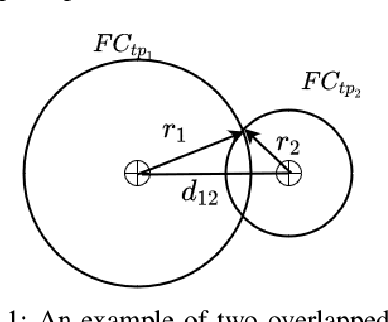


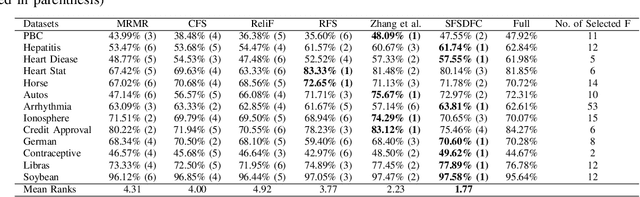
Feature selection methods are widely used to address the high computational overheads and curse of dimensionality in classifying high-dimensional data. Most conventional feature selection methods focus on handling homogeneous features, while real-world datasets usually have a mixture of continuous and discrete features. Some recent mixed-type feature selection studies only select features with high relevance to class labels and ignore the redundancy among features. The determination of an appropriate feature subset is also a challenge. In this paper, a supervised feature selection method using density-based feature clustering (SFSDFC) is proposed to obtain an appropriate final feature subset for mixed-type data. SFSDFC decomposes the feature space into a set of disjoint feature clusters using a novel density-based clustering method. Then, an effective feature selection strategy is employed to obtain a subset of important features with minimal redundancy from those feature clusters. Extensive experiments as well as comparison studies with five state-of-the-art methods are conducted on SFSDFC using thirteen real-world benchmark datasets and results justify the efficacy of the SFSDFC method.