 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLicense Plate Recognition
License-plate recognition is the process of identifying and reading license plates from images or videos.
Papers and Code
LP-LLM: End-to-End Real-World Degraded License Plate Text Recognition via Large Multimodal Models
Jan 14, 2026Real-world License Plate Recognition (LPR) faces significant challenges from severe degradations such as motion blur, low resolution, and complex illumination. The prevailing "restoration-then-recognition" two-stage paradigm suffers from a fundamental flaw: the pixel-level optimization objectives of image restoration models are misaligned with the semantic goals of character recognition, leading to artifact interference and error accumulation. While Vision-Language Models (VLMs) have demonstrated powerful general capabilities, they lack explicit structural modeling for license plate character sequences (e.g., fixed length, specific order). To address this, we propose an end-to-end structure-aware multimodal reasoning framework based on Qwen3-VL. The core innovation lies in the Character-Aware Multimodal Reasoning Module (CMRM), which introduces a set of learnable Character Slot Queries. Through a cross-attention mechanism, these queries actively retrieve fine-grained evidence corresponding to character positions from visual features. Subsequently, we inject these character-aware representations back into the visual tokens via residual modulation, enabling the language model to perform autoregressive generation based on explicit structural priors. Furthermore, combined with the LoRA parameter-efficient fine-tuning strategy, the model achieves domain adaptation while retaining the generalization capabilities of the large model. Extensive experiments on both synthetic and real-world severely degraded datasets demonstrate that our method significantly outperforms existing restoration-recognition combinations and general VLMs, validating the superiority of incorporating structured reasoning into large models for low-quality text recognition tasks.
Advancing Multinational License Plate Recognition Through Synthetic and Real Data Fusion: A Comprehensive Evaluation
Jan 12, 2026Automatic License Plate Recognition is a frequent research topic due to its wide-ranging practical applications. While recent studies use synthetic images to improve License Plate Recognition (LPR) results, there remain several limitations in these efforts. This work addresses these constraints by comprehensively exploring the integration of real and synthetic data to enhance LPR performance. We subject 16 Optical Character Recognition (OCR) models to a benchmarking process involving 12 public datasets acquired from various regions. Several key findings emerge from our investigation. Primarily, the massive incorporation of synthetic data substantially boosts model performance in both intra- and cross-dataset scenarios. We examine three distinct methodologies for generating synthetic data: template-based generation, character permutation, and utilizing a Generative Adversarial Network (GAN) model, each contributing significantly to performance enhancement. The combined use of these methodologies demonstrates a notable synergistic effect, leading to end-to-end results that surpass those reached by state-of-the-art methods and established commercial systems. Our experiments also underscore the efficacy of synthetic data in mitigating challenges posed by limited training data, enabling remarkable results to be achieved even with small fractions of the original training data. Finally, we investigate the trade-off between accuracy and speed among different models, identifying those that strike the optimal balance in each intra-dataset and cross-dataset settings.
Intelligent Traffic Surveillance for Real-Time Vehicle Detection, License Plate Recognition, and Speed Estimation
Jan 01, 2026Speeding is a major contributor to road fatalities, particularly in developing countries such as Uganda, where road safety infrastructure is limited. This study proposes a real-time intelligent traffic surveillance system tailored to such regions, using computer vision techniques to address vehicle detection, license plate recognition, and speed estimation. The study collected a rich dataset using a speed gun, a Canon Camera, and a mobile phone to train the models. License plate detection using YOLOv8 achieved a mean average precision (mAP) of 97.9%. For character recognition of the detected license plate, the CNN model got a character error rate (CER) of 3.85%, while the transformer model significantly reduced the CER to 1.79%. Speed estimation used source and target regions of interest, yielding a good performance of 10 km/h margin of error. Additionally, a database was established to correlate user information with vehicle detection data, enabling automated ticket issuance via SMS via Africa's Talking API. This system addresses critical traffic management needs in resource-constrained environments and shows potential to reduce road accidents through automated traffic enforcement in developing countries where such interventions are urgently needed.
Next-Generation License Plate Detection and Recognition System using YOLOv8
Dec 18, 2025In the evolving landscape of traffic management and vehicle surveillance, efficient license plate detection and recognition are indispensable. Historically, many methodologies have tackled this challenge, but consistent real-time accuracy, especially in diverse environments, remains elusive. This study examines the performance of YOLOv8 variants on License Plate Recognition (LPR) and Character Recognition tasks, crucial for advancing Intelligent Transportation Systems. Two distinct datasets were employed for training and evaluation, yielding notable findings. The YOLOv8 Nano variant demonstrated a precision of 0.964 and mAP50 of 0.918 on the LPR task, while the YOLOv8 Small variant exhibited a precision of 0.92 and mAP50 of 0.91 on the Character Recognition task. A custom method for character sequencing was introduced, effectively sequencing the detected characters based on their x-axis positions. An optimized pipeline, utilizing YOLOv8 Nano for LPR and YOLOv8 Small for Character Recognition, is proposed. This configuration not only maintains computational efficiency but also ensures high accuracy, establishing a robust foundation for future real-world deployments on edge devices within Intelligent Transportation Systems. This effort marks a significant stride towards the development of smarter and more efficient urban infrastructures.
* 6 pages, 5 figures. Accepted and published in the 2023 IEEE 20th International Conference on Smart Communities: Improving Quality of Life using AI, Robotics and IoT (HONET)
A Novel AI-Driven System for Real-Time Detection of Mirror Absence, Helmet Non-Compliance, and License Plates Using YOLOv8 and OCR
Nov 15, 2025Road safety is a critical global concern, with manual enforcement of helmet laws and vehicle safety standards (e.g., rear-view mirror presence) being resource-intensive and inconsistent. This paper presents an AI-powered system to automate traffic violation detection, significantly enhancing enforcement efficiency and road safety. The system leverages YOLOv8 for robust object detection and EasyOCR for license plate recognition. Trained on a custom dataset of annotated images (augmented for diversity), it identifies helmet non-compliance, the absence of rear-view mirrors on motorcycles, an innovative contribution to automated checks, and extracts vehicle registration numbers. A Streamlit-based interface facilitates real-time monitoring and violation logging. Advanced image preprocessing enhances license plate recognition, particularly under challenging conditions. Based on evaluation results, the model achieves an overall precision of 0.9147, a recall of 0.886, and a mean Average Precision (mAP@50) of 0.843. The mAP@50 95 of 0.503 further indicates strong detection capability under stricter IoU thresholds. This work demonstrates a practical and effective solution for automated traffic rule enforcement, with considerations for real-world deployment discussed.
* 6 pages, 4 figures. Published in: Proceedings of the 12th International Conference on Emerging Trends in Engineering Technology Signal and Information Processing (ICETET SIP 2025) Note: The conference proceedings contain an outdated abstract due to a publisher-side error. This arXiv version includes the correct and updated abstract
Theoretical Analysis of Power-law Transformation on Images for Text Polarity Detection
Nov 11, 2025Several computer vision applications like vehicle license plate recognition, captcha recognition, printed or handwriting character recognition from images etc., text polarity detection and binarization are the important preprocessing tasks. To analyze any image, it has to be converted to a simple binary image. This binarization process requires the knowledge of polarity of text in the images. Text polarity is defined as the contrast of text with respect to background. That means, text is darker than the background (dark text on bright background) or vice-versa. The binarization process uses this polarity information to convert the original colour or gray scale image into a binary image. In the literature, there is an intuitive approach based on power-law transformation on the original images. In this approach, the authors have illustrated an interesting phenomenon from the histogram statistics of the transformed images. Considering text and background as two classes, they have observed that maximum between-class variance between two classes is increasing (decreasing) for dark (bright) text on bright (dark) background. The corresponding empirical results have been presented. In this paper, we present a theoretical analysis of the above phenomenon.
VRAE: Vertical Residual Autoencoder for License Plate Denoising and Deblurring
Sep 11, 2025In real-world traffic surveillance, vehicle images captured under adverse weather, poor lighting, or high-speed motion often suffer from severe noise and blur. Such degradations significantly reduce the accuracy of license plate recognition systems, especially when the plate occupies only a small region within the full vehicle image. Restoring these degraded images a fast realtime manner is thus a crucial pre-processing step to enhance recognition performance. In this work, we propose a Vertical Residual Autoencoder (VRAE) architecture designed for the image enhancement task in traffic surveillance. The method incorporates an enhancement strategy that employs an auxiliary block, which injects input-aware features at each encoding stage to guide the representation learning process, enabling better general information preservation throughout the network compared to conventional autoencoders. Experiments on a vehicle image dataset with visible license plates demonstrate that our method consistently outperforms Autoencoder (AE), Generative Adversarial Network (GAN), and Flow-Based (FB) approaches. Compared with AE at the same depth, it improves PSNR by about 20%, reduces NMSE by around 50%, and enhances SSIM by 1%, while requiring only a marginal increase of roughly 1% in parameters.
TransLPRNet: Lite Vision-Language Network for Single/Dual-line Chinese License Plate Recognition
Jul 23, 2025License plate recognition in open environments is widely applicable across various domains; however, the diversity of license plate types and imaging conditions presents significant challenges. To address the limitations encountered by CNN and CRNN-based approaches in license plate recognition, this paper proposes a unified solution that integrates a lightweight visual encoder with a text decoder, within a pre-training framework tailored for single and double-line Chinese license plates. To mitigate the scarcity of double-line license plate datasets, we constructed a single/double-line license plate dataset by synthesizing images, applying texture mapping onto real scenes, and blending them with authentic license plate images. Furthermore, to enhance the system's recognition accuracy, we introduce a perspective correction network (PTN) that employs license plate corner coordinate regression as an implicit variable, supervised by license plate view classification information. This network offers improved stability, interpretability, and low annotation costs. The proposed algorithm achieves an average recognition accuracy of 99.34% on the corrected CCPD test set under coarse localization disturbance. When evaluated under fine localization disturbance, the accuracy further improves to 99.58%. On the double-line license plate test set, it achieves an average recognition accuracy of 98.70%, with processing speeds reaching up to 167 frames per second, indicating strong practical applicability.
FANVID: A Benchmark for Face and License Plate Recognition in Low-Resolution Videos
Jun 08, 2025


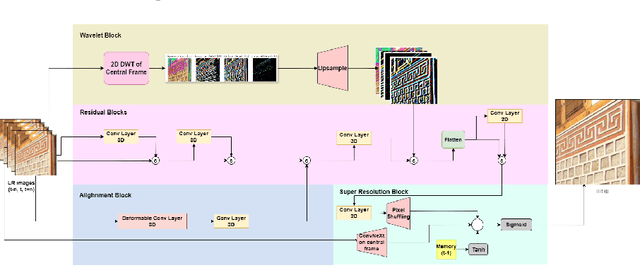
Real-world surveillance often renders faces and license plates unrecognizable in individual low-resolution (LR) frames, hindering reliable identification. To advance temporal recognition models, we present FANVID, a novel video-based benchmark comprising nearly 1,463 LR clips (180 x 320, 20--60 FPS) featuring 63 identities and 49 license plates from three English-speaking countries. Each video includes distractor faces and plates, increasing task difficulty and realism. The dataset contains 31,096 manually verified bounding boxes and labels. FANVID defines two tasks: (1) face matching -- detecting LR faces and matching them to high-resolution mugshots, and (2) license plate recognition -- extracting text from LR plates without a predefined database. Videos are downsampled from high-resolution sources to ensure that faces and text are indecipherable in single frames, requiring models to exploit temporal information. We introduce evaluation metrics adapted from mean Average Precision at IoU > 0.5, prioritizing identity correctness for faces and character-level accuracy for text. A baseline method with pre-trained video super-resolution, detection, and recognition achieved performance scores of 0.58 (face matching) and 0.42 (plate recognition), highlighting both the feasibility and challenge of the tasks. FANVID's selection of faces and plates balances diversity with recognition challenge. We release the software for data access, evaluation, baseline, and annotation to support reproducibility and extension. FANVID aims to catalyze innovation in temporal modeling for LR recognition, with applications in surveillance, forensics, and autonomous vehicles.
PatrolVision: Automated License Plate Recognition in the wild
Apr 15, 2025Adoption of AI driven techniques in public services remains low due to challenges related to accuracy and speed of information at population scale. Computer vision techniques for traffic monitoring have not gained much popularity despite their relative strength in areas such as autonomous driving. Despite large number of academic methods for Automatic License Plate Recognition (ALPR) systems, very few provide an end to end solution for patrolling in the city. This paper presents a novel prototype for a low power GPU based patrolling system to be deployed in an urban environment on surveillance vehicles for automated vehicle detection, recognition and tracking. In this work, we propose a complete ALPR system for Singapore license plates having both single and double line creating our own YOLO based network. We focus on unconstrained capture scenarios as would be the case in real world application, where the license plate (LP) might be considerably distorted due to oblique views. In this work, we first detect the license plate from the full image using RFB-Net and rectify multiple distorted license plates in a single image. After that, the detected license plate image is fed to our network for character recognition. We evaluate the performance of our proposed system on a newly built dataset covering more than 16,000 images. The system was able to correctly detect license plates with 86\% precision and recognize characters of a license plate in 67\% of the test set, and 89\% accuracy with one incorrect character (partial match). We also test latency of our system and achieve 64FPS on Tesla P4 GPU